AI

谷歌在德国投资 64 亿美元 建设新 AI 数据中心
谷歌将在德国进行重大投资,计划投入约55亿欧元(约合64亿美元),这是其在欧洲最大的一次投资,预计将在2029年前完成。 此次投资项目的核心目标是加速谷歌在德国 AI 领域的布局,力争在当地市场占据主导地位。 此次投资的主要内容之一是位于法兰克福东南方向的迪岑巴赫(Dietzenbach)建设一个全新的数据中心。
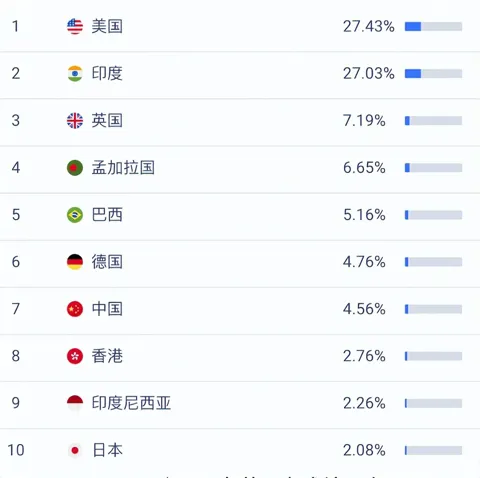
全球首个AI Agent交易市场MuleRun发布2.0版本,上线一个月用户数突破50万
11月13日凌晨0点,全球首个AI Agent交易市场MuleRun(骡子快跑)发布2.0版本,核心升级点包括为用户配置专属Agent团队,和上线多种垂直场景的Agent专题等。 自2025年9月MuleRun发布正式版本以来,仅一个月时间,注册用户数已突破50万,其中美国用户占比最高,达27.43%。 目前,已有上万名全球创作者报名入驻MuleRun,其中包括Quick BI、Funda AI、Piccopilot AI等在内的50 专业团队,为用户提供覆盖电商、数据分析、内容创作等多样化领域的160 Agent服务。

优必选正式开启8亿订单量产交付
11月12日,优必选首批数百台全尺寸工业人形机器人Walker S2正式开启量产交付,将分批投入产业一线应用。 2025年初至今,优必选Walker系列人形机器人累计订单金额已突破8亿元。

万豪国际采用阿里云基础设施,2026年飞猪旗舰店将试点 AI 智能体应用
昨日,阿里巴巴集团与万豪国际集团宣布达成重大的 AI 战略合作,双方将在中国市场围绕云基础设施和 AI 应用创新等领域展开深度合作,目标是为用户创造更个性化、高品质的旅行体验。 此次合作是双方自2017年成立合资公司以来,面向 AI 时代的又一次全面升级。 在技术底座方面,万豪国际将采用 阿里云领先的云基础设施及数据产品,以构建坚实的 AI 时代技术底座,助力其提升运营效率和业务增长。
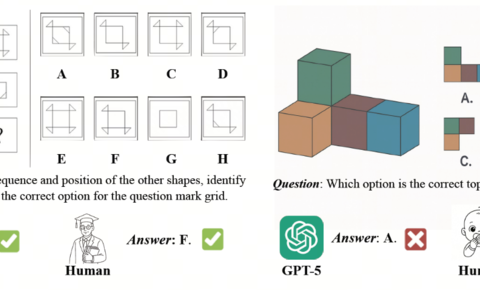
商汤日日新开源模型实现空间智能性能突破,多项评测领先 GPT-5
今天,商汤日日新在空间智能领域实现重要突破,正式发布并开源SenseNova-SI系列模型。 在多项权威评测的空间理解和推理任务上,SenseNova-SI 不仅大幅度领先同量级开源多模态大模型,还超越了 GPT-5 和 Gemini 2.5 Pro 等国际顶尖闭源模型的表现。 空间智能短板与系统性解决当下行业领先的大模型,虽然在知识、写作、推理、编程等方面展示了突出的性能,但是普遍存在一个重要的缺陷,就是对空间结构的理解和推理存在很严重的短板,而这恰恰是具身智能体与世界交互所需要的关键基础能力。

英特尔AI主管跳槽OpenAI,负责计算基础设施建设
近日,英特尔的首席技术与人工智能官萨钦・卡蒂(Sachin Katti)正式宣布离职,转投 OpenAI,担任公司的基础设施建设负责人。 这一消息于当地时间 11 月 10 日公布,迅速引发业内广泛关注。 卡蒂的离开标志着英特尔在人工智能领域的一次重要人事变动。

英特尔顶级 AI 高管离职,短短六个月投奔 OpenAI
英特尔公司的一名高管于近日宣布辞去首席技术官职务,仅在这个职位上任职六个月。 Sachin Katti 的离职标志着英特尔在 AI 领域面临的又一次重大挑战。 在 Katti 担任首席技术官期间,他负责公司的 AI 战略,但如今他选择加盟 OpenAI,这引发了业界的广泛关注。

维基百科呼吁 AI 公司停止 “白嫖” 内容,推广付费 API 服务
维基媒体基金会(Wikimedia Foundation)发布了一项公开声明,强烈要求人工智能(AI)公司停止使用自动化程序抓取维基百科内容,并建议他们使用付费 API 产品 ——“维基媒体企业平台”(Wikimedia Enterprise)。 此举是为了保护维基百科的资源和可持续发展。 维基媒体基金会指出,近年来 AI 公司通过网络抓取大量维基百科内容,严重消耗了其服务器资源,并影响了网站的正常运营。

上交博士最新思考:仅用两个问题讲清强化学习
人工智能领域发展到现在,强化学习(RL)已经成为人工智能中最令人着迷也最核心的研究方向之一。 它试图解决这样一个问题:当智能体没有现成答案时,如何通过与环境的交互,自主学会最优行为? 听起来简单,做起来却异常复杂。

具身智能公司无界动力完成3亿元首轮融资,红杉中国、线性资本领投,高瓴创投、地平线等跟投
11月10日,通用具身智能机器人公司无界动力完成首轮3亿元天使融资,由红杉中国、线性资本领投,高瓴创投、地平线、华业天成、钟鼎资本、BV百度风投、同歌创投等跟投,在首次融资中集聚了顶级财务投资机构与多元产业资本的双重认可。 与此同时,天使 轮融资已接近完成,累计融资额超5亿元。 无界动力2025年创立于北京,聚焦于构建机器人“通用大脑”与“操作智能”,突破手、眼、脑协同的关键瓶颈,将具身智能转化为一种可广泛部署、持续进化的基础设施,以通用基础模型研发与通用专家模型落地应用双线驱动,致力于为全球客户提供软硬一体、高可靠性的具身智能解决方案。

研究显示:英国四分之一大企业将因 AI 削减员工
根据最新的研究调查,预计未来一年内,约四分之一的大型英国企业将会因人工智能(AI)的发展而削减员工。 这项调查特别关注了企业的用人结构,显示出初级职位受到的影响尤为明显。 图源备注:图片由AI生成,图片授权服务商Midjourney在这项调查中,参与的企业主表示,随着 AI 技术的普及和应用,许多传统的初级岗位面临着被自动化取代的风险。

我从3.5亿用户的女性应用Flo ,学到9条聊天机器人的设计经验
编者按:顶级的产品通常在特定的功能上有一些非常深入的设计,这些设计常常立足于特定的领域、特定的用户,在深入的测试磨合之后,形成的行之有效的方案。 Flo 这款面向女性用户的 APP 在聊天机器人的设计上,有很多特别的设计,这对于当下的很多基于 AI 的聊天机器人产品而言,非常有参考价值。 Mary Borysova 在这篇文章当中,总结了 Flo 在聊天机器人当中的 9 个重要的优势和特点。

OpenAI CEO:大学学位的回报率将快速下降,但 AI 应用前景广阔
在最近的一次访谈中,OpenAI 首席执行官(CEO)山姆・奥特曼分享了他对普通大学学位回报率变化的看法。 他指出,普通大学学位的回报率将会比过去十年更快下降,尽管这种下降不会像理论上预测的那样迅速降到零。 他强调,未来的教育回报将受到人工智能(AI)技术普及的影响。

“左右脑互搏”还是“协同作战”? Uni-MMMU评估「理解-生成」双向协同
解几何题时,你是否会先画一条辅助线来帮助思考? 创作一幅画时,你是否需要先理解光影和物理原理? 这种「理解」与「生成」的紧密协同,是人类智能的核心特征。

社交平台 X 引入 AI 辅助核查,用户信息真实度或将提升
社交平台 X(原 Twitter)最近开始大规模采用人工智能(AI)进行内容核查,提升用户对信息的信任度。 据哥伦比亚新闻评论(CJR)报道,约有10% 的 “社区注释” 是由八个 AI 机器人生成的,这些机器人通过官方 API 为平台贡献内容。 图源备注:图片由AI生成今年10月,一段与 “No Kings” 抗议活动相关的视频在社交媒体上广泛传播。

AI 的本质不是算力,而是「上下文革命」
过去几年,人工智能的浪潮一次又一次刷新人们的想象:模型变得更大、算力更强、应用更广。 但在光鲜的成果背后,一个更深层的问题被不断暴露 —— AI 真的“理解”世界了吗? 它能记住对话,却常常忘记语境,能生成答案,却未必明白问题的由来。

微软启动人本主义超级智能 AI 项目,确保技术服务人类
微软 AI 部门负责人穆斯塔法・苏莱曼(Mustafa Suleyman)近日宣布,微软将成立一个新团队,专注于开发 “人本主义超级智能” AI。 这一新型 AI 将以人为中心,旨在服务人类,而不是取代人类或变得高度自治。 苏莱曼在博客中强调,这种超级智能将被谨慎地设定界限,并受严格的监管,以确保人类始终保持在技术发展的 “食物链顶端”。

谷歌拟加大对 Anthropic 投资,估值或超 3500 亿美元
谷歌正在与人工智能公司 Anthropic 进行深入的投资合作谈判,预计这一轮融资将使 Anthropic 的估值突破3500亿美元。 谈判尚在进行中,具体的合作细节仍未确定,谷歌可能会通过提供更多云计算服务、可转换债券或新一轮的融资来加强与 Anthropic 的合作。 目前,谷歌已经向 Anthropic 投资超过30亿美元,这使其获得了该公司的14% 股权。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉