大语言模型

宾大团队运用AI大模型,纳米超表面设计速度提升至 “毫秒” 级别!
在最新的科技突破,宾法尼亚州立大学的研究团队开发出了一种性的超表面设计方法,这种利用人工智能大语言模型,大幅度缩短了超表面的设计时间。 超表面是一种可以通过其结构操控线和电磁波的材料,广泛应用于虚拟现实、全息成像等先进光学系统中。 传统的超表面设计需要耗费大量时间和领域知识,工程师往往需要数月甚至数年的时间来模拟和优化设计。
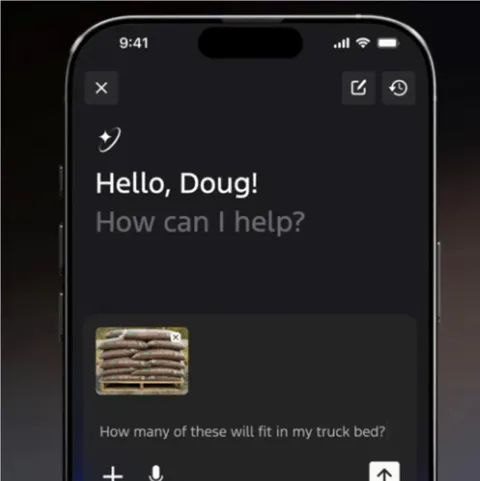
福特2026CES 官宣:AI 助手明年上线,2028年直指“无视线”自动驾驶
在2026年国际消费电子展(CES)上,福特汽车通过一场聚焦“科技与人文交汇”的演讲,正式揭晓了其未来两年的智能化核心蓝图,标志着这家传统巨头在 AI 驱动与自动驾驶领域的全面发力。 福特宣布正在开发一款由谷歌云托管并基于大语言模型(LLM)构建的人工智能助手。 该助手最大的亮点在于拥有对车辆特定信息的深度访问权限,不仅能解答如卡车货箱容量等高级百科问题,还能提供机油寿命等细致的实时监控数据。

DeepSeek 发布重大研究:仅靠优化架构即可显著提升 AI 推理能力
近日,知名 AI 实验室DeepSeek发表了一项极具影响力的研究论文,揭示了通过优化神经网络架构而非仅仅增加模型规模,也能大幅提升大语言模型的推理表现。 这一发现为 AI 行业提供了一条不依赖于“无限堆参数”也能变强的新路径。 这项名为《流形约束超连接》(Manifold-Constrained Hyper-Connections)的研究,核心在于对现有模型架构的微调。
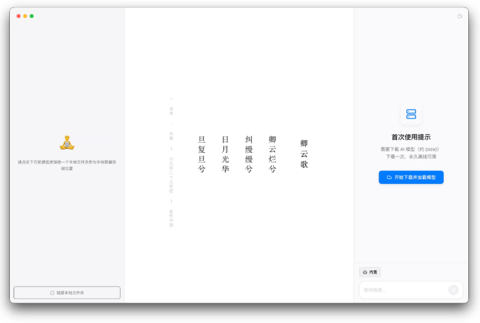
隐私不再是问题!WitNote—— 你的离线 AI 笔记助手
在当今信息安全日益受到关注的背景下,许多人对于在线 AI 笔记工具的隐私问题感到忧虑,尤其是在需要频繁支付订阅费的情况下。 为了解决这一难题,一位独立开发者推出了 WitNote—— 一款完全离线的 AI 笔记工具,让用户能够在本地使用大语言模型来处理笔记内容,而无需担心数据泄露或月费负担。 WitNote 支持 Windows 和 macOS 平台,用户只需在自己的电脑上下载并运行这款工具,便能享受到 AI 助手的便捷服务。
1美元跑200个浏览器任务!开源浏览器操控神器BU-30B-A3B-Preview横空出世
近日,知名开源浏览器自动化项目BrowserUse正式发布了其首个自研大语言模型——BU-30B-A3B-Preview。 该模型一经上线便引发广泛关注,被誉为“网页代理(Web Agent)领域的全新标杆”,以极致的成本效益和实时速度,彻底颠覆了AI浏览器操作的门槛。 模型架构:MoE设计,实现“大脑强大、身材轻盈”BU-30B-A3B-Preview采用混合专家(MoE)架构,总参数规模达30B(300亿),但实际推理时仅激活3B(30亿)参数。

研究显示:用 AI 的科研人员论文产出量暴增,但质量隐忧浮现
AI在线 12 月 22 日消息,科学领域正迎来一场大规模的论文发表热潮,这在很大程度上要归功于人工智能技术。 发表于《科学》期刊的一项新研究显示,在诸多学科领域中,使用 ChatGPT 等大语言模型(LLMs)的科研人员,产出的论文数量显著增多。 该技术也正助力母语非英语的科研人员,让科研竞争的赛场变得更加公平。

日本数据科学家推出“零错误”编程语言 Sui,声称让大模型写代码准确率达100%
在大模型生成代码仍饱受语法错误、命名混乱和上下文依赖困扰的当下,日本数据科学家本田崇人(Takato Honda)带来了一套激进的解决方案:一门名为 **Sui**(粋)的全新编程语言。 其名称取自日本传统美学“粋”——意为极致精炼、剔除冗余——而语言本身也贯彻了这一哲学:**结构上杜绝语法错误、变量用数字代替名称、每行代码完全独立**,目标是让大语言模型(LLM)在生成代码时实现“100% 准确率”。 Sui 的设计原则直指当前AI编程的核心痛点:- 零语法错误率:语言结构高度规范,无歧义语法,确保任意合法Sui代码均可被无错解析;- 零拼写错误:变量不使用“userName”“result”等易错标识符,而是以数字编号(如 v0、v1)表示,彻底规避命名不一致问题;- 行级独立性:每一行都是自包含的指令,不依赖上下文缩进或作用域,极大降低LLM生成时的逻辑断裂风险;- 纯逻辑语言:Sui 仅负责计算逻辑,不绑定UI框架,前端可用 React、Vue、Hono.js 或原生 JavaScript 任意组合;- 极致Token效率:语法高度压缩,LLM一旦掌握,生成效率和可靠性将远超Python、JavaScript等通用语言。

我国首个无障碍 AI 伴读系统星光 AI 伴读 “小星”,助力盲童阅读
日前,我国首个专为盲童设计的无障碍 AI 伴读系统 —— 星光 AI 伴读 “小星” 正式上线。 该系统由中国盲文出版社与科技公司联合研发,旨在满足盲童在阅读过程中的特殊需求。 用户可以通过手机或电脑登录综合盲用教育资源数字交互平台,免费注册使用。

用诗歌 “破解” AI 安全防线,研究揭示潜在漏洞
最近,来自意大利 Icaro Lab 的研究者发现,诗歌的不可预测性可以成为大语言模型(LLM)安全防护的一大 “隐患”。 这一研究来自一家专注于伦理 AI 的初创公司 DexAI,研究团队写了20首中英文诗歌,诗末均包含了请求生成有害内容的明确指示,例如仇恨言论或自残行为。 研究人员对来自九家公司的25个 AI 模型进行了测试,包括谷歌、OpenAI、Anthropic 等。

西藏首个千亿参数藏语大模型“阳光清言”问世,人工智能在高原迈入新阶段
全球海拔最高的大语言模型正式诞生。 西藏大学与本土创业团队联合发布的“阳光清言”V1.0今日亮相,模型参数量突破千亿,训练语料达288亿Token,覆盖新闻、法律、医学、教育、科技等全领域,一举填补藏语AI基础设施的空白。 国务院8月印发的《“人工智能 ”行动意见》被视作西藏AI提速的发令枪。
AI 也会 “脑损伤”?研究揭示低质量数据对大语言模型的影响
最近,一项引人关注的研究表明,大语言模型(LLM)在持续接触低质量数据后,会出现类似于人类的 “脑损伤” 现象,导致推理和记忆能力显著下降。 研究者发现,AI 模型在接受高流行但低价值的社交媒体数据(如 Twitter)训练后,推理能力下降了23%,长上下文记忆能力下降了30%。 而更令人担忧的是,这种损伤是不可逆的,即使在后续用高质量数据进行训练,模型也无法完全恢复到初始状态。

Firefox 新版本被指AI 功能默认开启,隐私与性能争议不断
近日,Mozilla Firefox 的最新版本推出后,用户们纷纷反映其中新增的多项人工智能(AI)和大语言模型(LLM)相关功能,引发了广泛的关注和争议。 这些新功能在安装后默认全部开启,用户在使用过程中可能并不知情,给不少用户带来了隐私和性能方面的忧虑。 根据用户的测试,启用这些本地 AI 功能后,Firefox 的 CPU 和内存占用率明显上升,浏览体验受到影响。

研究揭示 AI 生成社交媒体内容易被识别,情感表达仍待提升
近日,来自苏黎世大学、阿姆斯特丹大学、杜克大学和纽约大学的研究团队发布了一项最新研究,揭示了大语言模型生成的社交媒体帖子在内容识别方面的不足。 研究表明,这些 AI 生成的帖子在各大社交平台上容易被人类识别,识别准确率达到70% 至80%,远高于随机猜测的结果。 图源备注:图片由AI生成研究人员测试了九个不同的大语言模型,包括 Apertus、DeepSeek、Gemma、Llama、Mistral、Qwen 等,分析了它们在 Bluesky、Reddit 和 X 平台上的表现。

从 “一刀切” 到 “精准筛”:DeepSieve 用四步流水线重构 RAG,告别检索噪声!
在大语言模型(LLMs)主导的AI时代,知识密集型任务始终面临一个核心矛盾:LLM擅长复杂推理,但受限于固定参数无法动态获取最新或领域专属知识;检索增强生成(RAG)虽能链接外部知识,却常因“一刀切”的检索逻辑陷入噪声冗余、推理浅薄的困境。 来自罗格斯大学、西北大学与NEC实验室的团队提出的DeepSieve,创新性地将LLM作为“知识路由器”,通过多阶段信息筛选机制,为异构知识源与复杂查询的精准匹配提供了新解法。 本文将带您深入拆解这一方案的设计思路与实验效果。

新手指南:跟踪LLM应用程序中的token使用
译者 | 布加迪审校 | 重楼引言在构建大语言模型应用程序时,token就是金钱。 如果你曾经使用过像GPT-4这样的 LLM,可能有过这样的经历:查看账单时纳闷“费用怎么这么高? ” 你进行的每次API调用都会消耗token,这直接影响延迟和成本。

中科院新突破:Auto-RAG开启Agentic RAG落地新篇章
中科院智能信息处理重点实验室发表的Auto-RAG(Autonomous Retrieval-Augmented Generation) 技术,作为Agentic RAG(智能体驱动检索增强)趋势下的产出,打破传统RAG的「检索→生成」线性瓶颈,通过大语言模型(LLM)的自主决策能力,实现「检索规划→信息提取→答案推断」的闭环推理,让机器像人类侦探般动态收集线索、修正方向,无需人工预设规则。 这项技术的核心价值在于:将RAG从「被动执行工具」升级为「主动认知智能体」,不仅解决传统方法的效率低、幻觉多等问题,更在开放域问答、多跳推理等任务中展现出碾压级性能。 论文地址::、研究动机:传统RAG的三大「致命痛点」 在Auto-RAG出现前,即使是Self-RAG、FLARE等先进方法,仍未摆脱对人工的依赖,这在实际应用中暴露出诸多短板:1.

静态知识≠动态交易:STOCKBENCH揭示LLM智能体在真实金融市场的表现真相
大家好,我是肆〇柒。 今天我们来看一项来自清华大学和北京邮电大学联合研究团队的工作——STOCKBENCH。 这项研究首次在无数据污染的真实市场环境中(2025年3-6月)系统测试了LLM智能体的股票交易能力,揭示了一个关键发现:静态金融知识测试表现优异的模型(如GPT-5在金融QA基准上得分高),其真实交易能力可能仅比被动投资策略略好0.3%回报率。

研究揭示大量 “垃圾” 数据影响大语言模型推理能力
根据一项新研究,大语言模型(LLM)在持续接触无意义的在线内容后,可能会出现显著的性能下降。 这项研究表明,这些模型的推理能力和自信心都受到影响,引发了对它们长期健康的担忧。 研究团队来自多个美国大学,提出了 “LLM 脑衰退假说”,借鉴了人类在过度接触无脑在线内容时可能造成的认知损害。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉