在医疗诊断中,模型误将“罕见病症状”与“常见病混淆”;在金融分析里,因记错政策条款给出错误投资建议——大语言模型(LLMs)的这些“失误”,本质上源于一个核心症结:记忆知识与逻辑推理的过程被死死绑定在黑箱中。当模型的思考既需要调用事实性知识,又要进行多步逻辑推导时,两种能力的相互干扰往往导致答案失真或决策失据。
罗格斯大学、俄亥俄州立大学等团队发表于2025 ACL的研究《Disentangling Memory and Reasoning Ability in Large Language Models》,为破解这一难题提供了全新思路。他们用两个简单的特殊Token,就实现了记忆与推理的“解耦分家”,不仅让模型思考过程变得透明,更在多项权威测试中超越GPT-4o等强基线。
论文地址:https://arxiv.org/abs/2411.13504
项目地址:https://github.com/MingyuJ666/Disentangling-Memory-and-Reasoning
01、大模型的“认知瓶颈”:记忆与推理的致命纠缠
当前大模型处理复杂任务时,就像“边查资料边做题”却从不在草稿纸上标注哪步是查资料、哪步是算答案——这种混沌状态带来了两大核心问题。
1. 黑箱决策的可靠性危机
现有LLMs的推理过程缺乏结构化拆分,知识检索(“XX药物的副作用是什么”)和逻辑推导(“结合患者病史判断是否适用该药物”)被揉合成连续的文本生成。这种不透明性导致:
- 幻觉频发:当记忆知识不足时,模型会用“看似合理的推理”编造事实,例如虚构不存在的医学研究结论;
- 追责困难:在医疗、金融等高危场景中,无法定位错误是源于“记错知识”还是“推理逻辑混乱”,严重限制了模型的落地价值。
2. 单一增强方法的局限性
业界已有的优化路径始终未能突破“分而治之”的困境:
- 记忆增强(如RAG):专注于让模型精准获取外部知识,但无法引导知识与推理的有效结合,常出现“知识堆砌却答非所问”;
- 推理增强(如CoT):通过思维链拆分推理步骤,但未明确区分哪些步骤需要知识支撑,导致模型在关键事实节点仍依赖模糊记忆。
当面对“MMA是否起源于罗马斗兽场比赛”这类既需事实记忆又需逻辑分析的问题时,现有方法往往顾此失彼。
02、核心解法:用两个Token给思考“贴标签”
这项研究的精髓在于提出了“标记-解耦-融合”的推理新范式,通过引入⟨memory⟩(记忆)和⟨reason⟩(推理)两个特殊控制Token,强制模型在思考过程中明确区分两种认知行为。
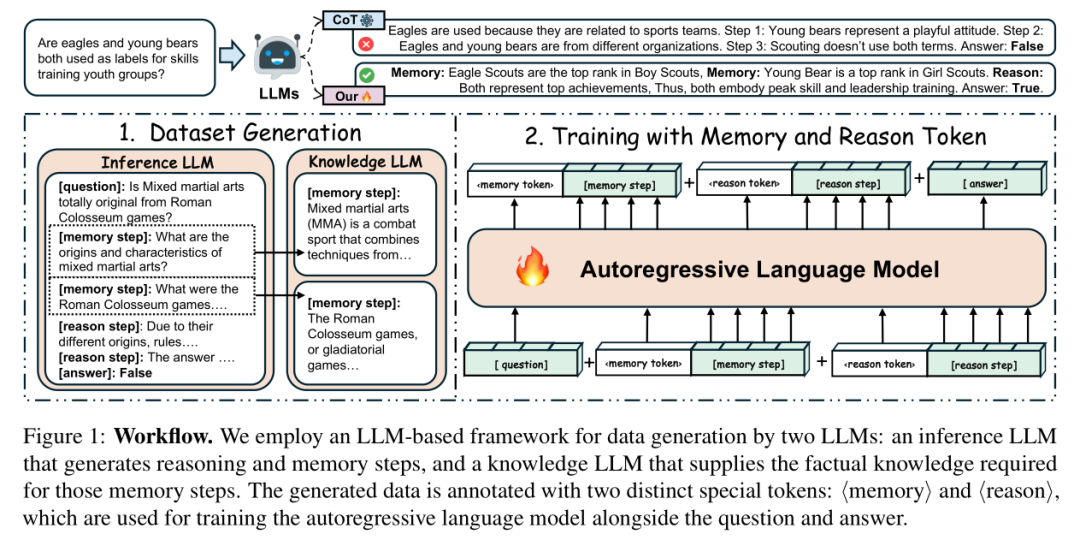
第一步:生成“带标签”的高质量训练数据
要让模型学会拆分思维,首先得有标注清晰的“思维样本”。研究设计了“双LLM协作框架”来自动生成训练数据,流程如下:
(1)推理LLM:给思维步骤贴标签
推理LLM的核心任务是生成带标记的思维链,比如面对“MMA是否起源于罗马斗兽场比赛”的问题时,它会输出:
复制复制这里有个关键设计:推理LLM会将⟨memory⟩标记的知识需求转化为明确问题,这能强化知识的事实属性,为后续精准检索铺垫。
(2)知识LLM:给记忆问题填答案
知识LLM专门负责回答推理LLM生成的⟨memory⟩问题,比如针对“MMA的起源和特点是什么?”,它会提供准确的事实性答案:“MMA起源于20世纪90年代,融合拳击、摔跤等多种格斗技术,采用严格的体重分级和安全规则...”。
最终整合形成的训练样本包含三部分:问题、“记忆-推理”交织的思维链、最终答案,为模型学习解耦逻辑提供了高质量数据。
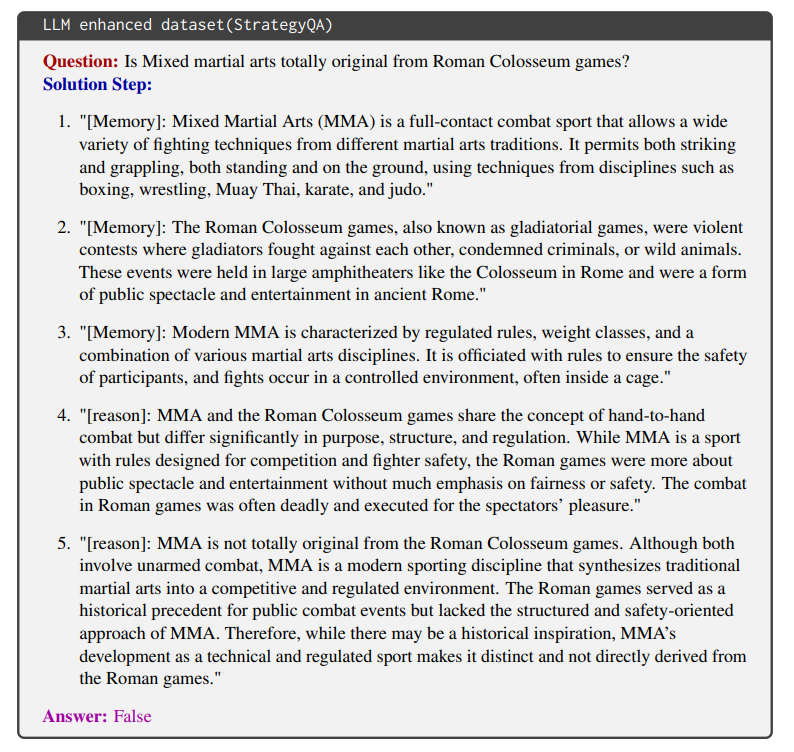
第二步:用带标记数据微调模型
有了标注数据后,研究采用LoRA(低秩适应)技术对LLaMA-3.1-8B等模型进行微调,核心是让模型学会响应两个特殊Token的引导:
- 看到⟨memory⟩时,激活知识检索相关的网络模块,专注调用或生成事实性内容;
- 看到⟨reason⟩时,启动逻辑推理模块,基于已获取的知识进行分析推导。
这些Token是“可训练的词外标记”,意味着模型能在微调中不断优化对两种认知行为的区分能力,而非机械执行固定指令。

注:论文中所说的知识检索和逻辑推理均是模型自身知识检索和自身逻辑推理。
03、实验结果:8B小模型竟超越GPT-4o?
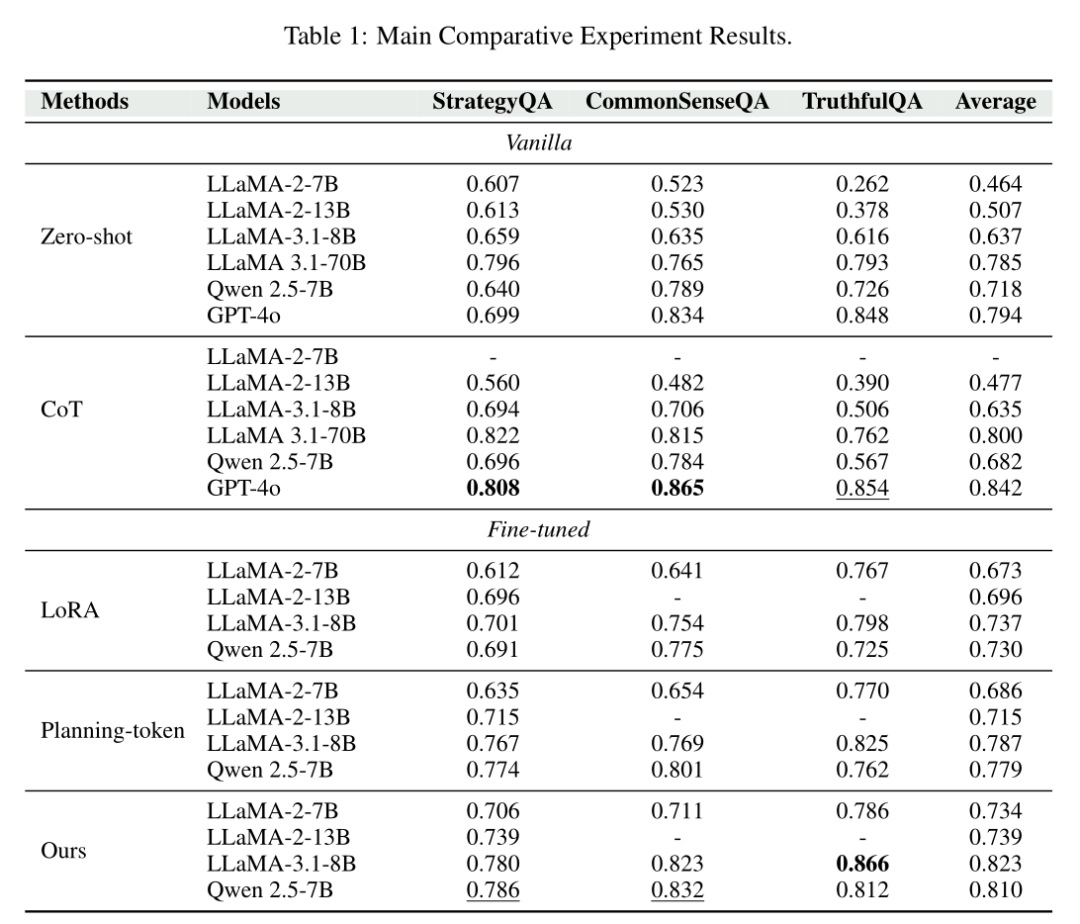
研究在三大权威数据集上进行了全面测试,对比了Zero-shot、CoT、Planning-token等主流方法,结果显示这种“贴标签”的简单思路实现了性能的跨越式提升。
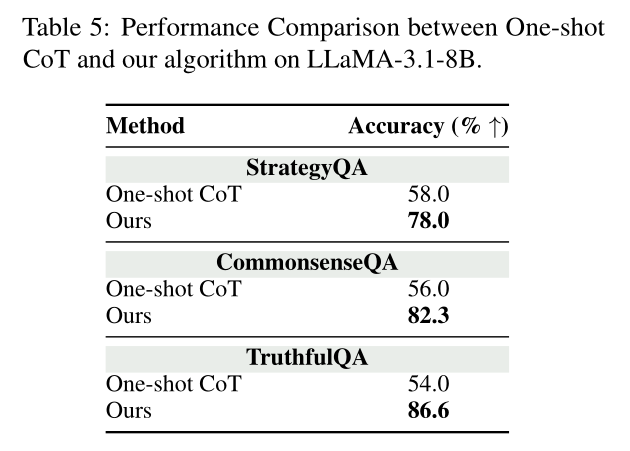
核心任务:准确率全面碾压基线
最令人意外的是,在TruthfulQA数据集上,80亿参数的LLaMA-3.1-8B经过本方法微调后,准确率竟超过了参数量远超于它的GPT-4o,证明解耦机制能极大释放小模型的潜力。
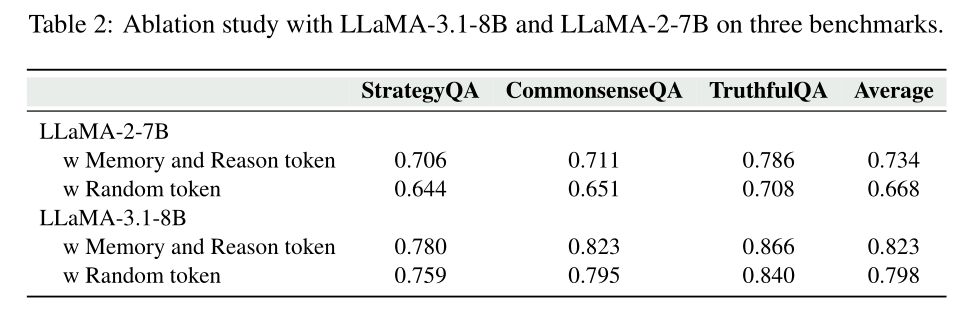
消融实验:验证关键设计的必要性
为了确认核心模块的价值,研究进行了多组消融测试,结果清晰展现了各设计的不可替代性:
(1)特殊Token是“灵魂”
结果显示,使用特定Token的模型性能明显优于随机Token的模型,这证明模型确实能理解Token的语义含义,而非单纯依赖序列模式,也验证了特殊Token在解耦记忆和推理中的有效性。
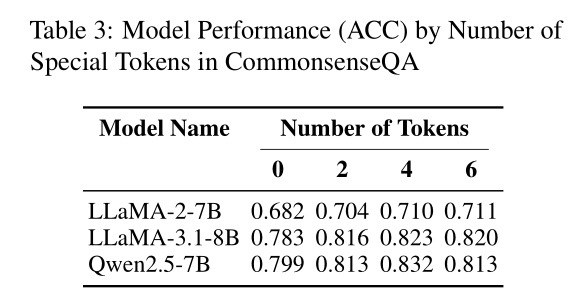
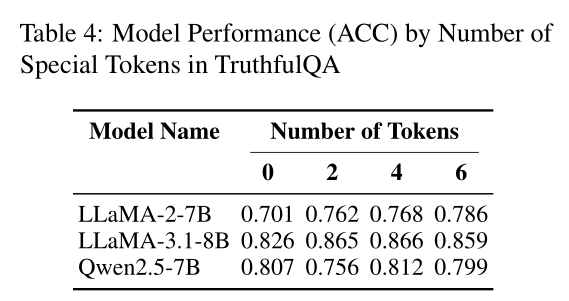
(2)Token数量有“最优解”
实验发现,当特殊Token数量在4到6个时(可理解为思维链中记忆与推理步骤的最佳配比),模型性能达到峰值。过少则无法充分拆分思维,过多则会增加输入冗余,反而干扰理解。 这表明适量的特殊Token能够更好地引导模型进行记忆和推理的解耦。
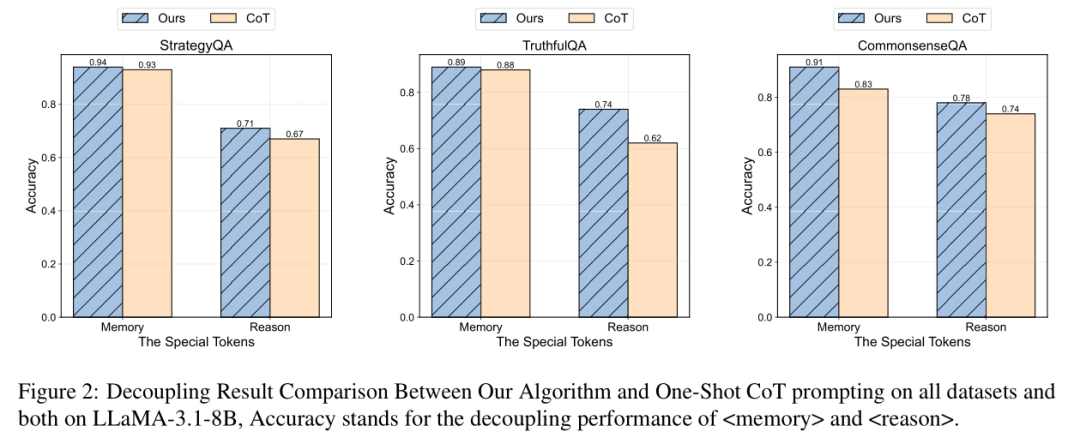
(3)解耦效果被“第三方认证”
研究用GPT-4o-mini作为独立评估器,判断模型标记的⟨memory⟩步骤是否真的涉及事实知识、⟨reason⟩步骤是否真的包含逻辑推理。结果显示,本方法的“标记准确率”比One-shot CoT高出34.7%,证实了记忆与推理的有效分离。
注意力分析:模型真的在“专注”
通过可视化模型的注意力热图发现,⟨memory⟩和⟨reason⟩Token在推理过程中获得了显著更高的注意力权重。这意味着模型确实会主动关注这些标记,并据此切换认知模式——就像学生做题时看到“资料区”和“计算区”的提示,会自然调整思维状态。
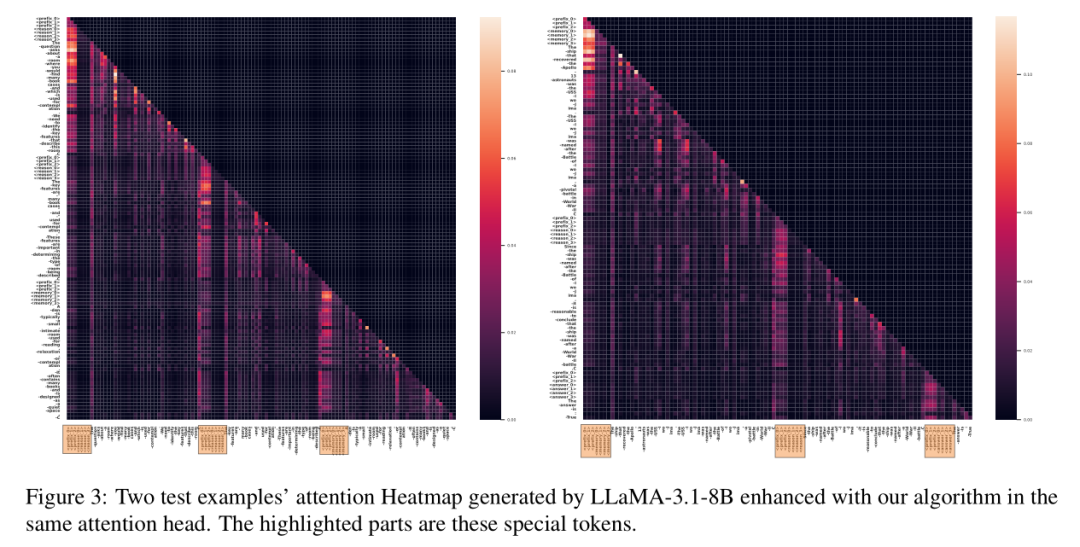
错误分析:问题出在哪?
对模型生成的错误结果进行分析,发现大多数错误来源于推理步骤,而非记忆问题。这说明解耦机制已有效解决了知识检索的精准性问题,但复杂逻辑推理仍是未来优化的核心方向。


04、启示与局限:给大模型“减负”的未来
核心价值:简单思路解决复杂问题
这项研究的最大亮点在于**“以极简设计实现高效解耦”**:没有引入复杂的网络结构,仅通过两个特殊Token和结构化数据生成,就同时实现了性能提升与可解释性增强。这种思路为小模型适配复杂任务提供了低成本方案——无需堆砌参数,只需优化思维结构。
该方法的核心价值在于 “错误可溯源、决策可验证”,因此在 “结果正确性与过程透明度直接影响安全或利益” 的场景中具备不可替代的优势。同时,为高风险专业决策场景的模型落地提供了新路径,例如,医生可通过⟨memory⟩步骤核查模型调用的医学知识,通过⟨reason⟩步骤验证诊断逻辑,大幅降低决策风险。
现存局限:还有哪些待解难题?
尽管效果显著,该方法仍存在明显不足:
- 评估维度单一:仅采用准确率作为评价指标,未能衡量思维链的连贯性、知识的相关性等关键维度;
- 训练方式滞后:依赖传统的监督微调(SFT),未结合当前主流的RLHF(基于人类反馈的强化学习)等方法,可能限制模型的泛化能力;
- 微调依赖:需要对模型进行参数调整,无法直接应用于闭源LLM的API调用场景,与企业“轻量化部署”的需求存在差距。
结语:让大模型学会“有条理地思考”
从CoT让模型“分步做题”,到RAG让模型“查资料做题”,大模型推理优化的核心始终是“模拟人类认知过程”。这项研究则更进一步,通过给思维步骤“贴标签”,让模型学会“有条理地思考”——先明确需要什么知识,再专注进行逻辑推导。
这种“解耦思维”不仅提升了当前模型的性能,更指向了未来LLM发展的关键方向:可解释性与高性能并非对立命题。或许不久后,当大模型给出专业建议时,我们能清晰地看到它的“知识来源”与“推理轨迹”,真正实现“可信AI”的落地。
05、对LLM应用开发的启示
从实验结果来看,8B 参数级别的小模型(如 LLaMA-3.1-8B)通过 “标记化解耦” 优化后,在 TruthfulQA 等数据集上能超越 GPT-4o,在 StrategyQA、CommonsenseQA 上也能逼近大模型性能。这一结论对资源有限的团队极具价值 —— 无需依赖千亿参数大模型,只要具备基础微调算力,就能基于该方法在垂直领域实现 “小模型干大事”,为低成本落地高质量 LLM 应用提供了可行路径。
对RAG应用:以标记化拆解破解“检索-生成黑箱”,实现知识可溯与推理透明
- 检索阶段:给外部知识打“专属标记”,让来源清晰可查在RAG的检索环节,需为所有外部文档片段添加结构化标记⟨memory-RAG⟩,并附加关键元信息,与模型内部参数化知识(标记为⟨memory-param⟩)明确区分。具体做法是:将检索到的维基百科条目、企业知识库内容等,统一标注为⟨memory-RAG, 来源:[具体信源], 检索时间:[YYYY-MM-DD], 置信度:[相似度得分]⟩,再紧跟对应的知识内容。例如,回答“北京2024年GDP是多少”时,若检索到北京市统计局发布的数据,可标记为:⟨memory-RAG, 来源:北京市统计局2024年年度报告,检索时间:2025-03-15,置信度:0.95⟩ 北京2024年GDP为4.3万亿元。这一优化直接解决传统RAG“知识来源模糊”的问题:用户能直观看到事实性内容的具体出处,开发者也可通过⟨memory-RAG⟩快速排查检索层问题——比如发现“GDP数据过时”时,可直接追溯到检索文档的发布时间,判断是否需要重新检索最新资料。
- 生成阶段:用“双标记拆分推理链”,让逻辑关联可视化生成答案时,需强制模型按“⟨memory-param⟩+⟨memory-RAG⟩(引用检索知识)→⟨reason⟩(展开逻辑推理)”的结构输出,形成“知识输入-推理过程-结论输出”的完整闭环,避免推理与知识脱节。以“北京2024年GDP增速相比2023年如何”为例,生成内容可设计为:这种结构化拆分让推理逻辑完全透明:若出现“增速计算错误”(如误将4.3-4.1算为0.3),可直接定位到⟨reason⟩步骤的逻辑漏洞;若“GDP数值与官方数据不符”,则能快速锁定⟨memory-RAG⟩环节的检索误差,大幅降低问题排查的时间成本。
- ⟨memory-RAG, 来源:北京市统计局2024年报⟩ 北京2024年GDP为4.3万亿元,2023年GDP为4.1万亿元;
- ⟨reason⟩ 第一步计算增速:(2024年GDP-2023年GDP)/2023年GDP = (4.3-4.1)/4.1 ≈ 4.88%;
- ⟨reason⟩ 第二步对比结论:2024年增速约4.88%,较2023年(3.5%)提升1.38个百分点。
- 优化方向:动态调度知识来源,平衡RAG的性能与效率基于⟨memory-RAG⟩与⟨memory-param⟩的标记区分,可让RAG系统根据问题类型智能选择知识来源,避免“过度检索浪费算力”或“依赖内部知识导致时效偏差”。具体策略分为两类:
a.强制调用⟨memory-RAG⟩的场景:针对“时效性强”(如2025年新发布的行业政策)、“领域专属”(如某公司内部产品的技术参数)、“高风险事实”(如药品推荐剂量)的问题,必须通过外部检索获取知识,禁止依赖模型内部记忆。例如回答“某企业2025年新手机的售价”时,标记为⟨memory-RAG, 来源:企业官网2025产品页⟩ 该手机售价1999元,确保信息的准确性与时效性。
b.优先调用⟨memory-param⟩的场景:对于“通用稳定知识”(如“地球是球体”)、“低敏感度常识”(如“1米=100厘米”)的问题,可直接使用模型内部记忆,减少检索环节的算力消耗。例如回答“地球自转周期”时,标记为⟨memory-param⟩ 地球自转周期约为24小时,若用户对结果存疑,再触发⟨memory-RAG⟩进行二次验证。通过这种动态调度,RAG系统既能在关键场景保证知识的准确性,又能在通用场景提升响应效率,实现“可靠性”与“性价比”的平衡。
对通用 LLM 应用开发:建立 “结构化思维链” 范式,提升可控性与可迭代性
解耦记忆与推理的核心启示,远超 RAG 场景 —— 对资源有限、以小模型为核心的团队而言,“标记化思维链” 是低成本提升模型可控性与可迭代性的关键路径,能让小模型在垂直领域的表现更接近大模型水平。
- 开发范式:强制 “标记化思维链” 设计,而非 “自由文本生成”:无论开发智能助手、内容创作工具还是自动化流程系统,均可借鉴 “⟨memory⟩+⟨reason⟩” 的标记思路,为模型输出定义结构化格式。例如,开发客户服务 AI 时,可设计⟨memory-user⟩(标记用户提供的需求信息,如 “用户反馈‘订单未发货’,订单号 12345”)、⟨memory-system⟩(标记系统查询到的订单状态,如 “系统显示‘订单已发货,物流单号 67890’”)、⟨reason⟩(标记问题处理逻辑,如 “用户反馈与系统状态冲突→需核对物流信息是否更新延迟”)。这种设计让客服人员能快速抓取关键信息(⟨memory⟩)和处理逻辑(⟨reason⟩),避免传统客服 AI“输出大段文本,关键信息淹没其中” 的问题。
- 迭代优化:基于标记定位模型短板,实现 “精准微调”:解耦方法的标记可作为 “模型错误分析的锚点”:通过统计错误案例中 “⟨memory⟩相关错误占比” 和 “⟨reason⟩相关错误占比”,明确模型优化方向。例如,在智能代码生成应用中,若 60% 错误源于 “⟨memory⟩步骤记错 API 参数”(如 “将 Python 的‘print ()’写成‘println ()’”),则需补充 “编程语言 API 知识库” 的微调数据;若 70% 错误源于 “⟨reason⟩步骤逻辑错误”(如 “循环条件设置错误导致死循环”),则需加强 “代码逻辑推理” 相关的训练数据。这种 “精准定位 - 针对性优化” 的模式,避免了传统 LLM 微调 “盲目投喂数据,效果难量化” 的问题,提升迭代效率。


