开源

开源版“Veo 3”来了:LTX-2正式发布,一次性生成20秒4K音画同步AI视频,本地显卡轻松跑
AI视频生成领域迎来里程碑式突破!Lightricks团队正式开源LTX-2模型,这被誉为首个真正完整的开源音视频基础模型,支持一次性生成最长20秒的4K高清视频,并实现画面、声音、口型、环境音和音乐的完美同步。 AIbase编辑团队梳理最新网络动态,为您带来全面解读。 开源大礼包:权重 代码全放出,社区狂欢开启LTX-2模型权重、完整训练代码、基准测试和工具包已全部开源,托管于GitHub和Hugging Face。

元象开源XVERSE-Ent大模型!聚焦泛娱乐场景,中英双语支持,填补行业专属模型空白
国产大模型生态再添重磅成员。 元象科技(XVERSE)今日正式开源其聚焦泛娱乐领域的底座大模型——XVERSE-Ent,同步推出中文与英文双版本。 该模型专为社交互动、游戏叙事、文化创作(含小说、剧本、短视频脚本等)等泛娱乐核心场景深度优化,支持轻量化部署与垂直领域快速落地,成为国内首个面向泛娱乐行业的专属开源大模型,填补了该领域高质量基础模型的空白。

端侧AI翻译新突破:腾讯混元1.5版开源,手机也能实时多语种互译
据AIbase报道,腾讯近日正式发布其混元翻译模型(HY-MT)的1.5版本,并宣布将其开源。 这是一个支持33种语言互译的强大解决方案,旨在为移动设备和高效的端侧部署提供卓越的翻译能力。 新发布的模型包含两个版本:Tencent-HY-MT1.5-1.8B 和 Tencent-HY-MT1.5-7B。

北京发布开源生态三年行动方案!2028年前打造10个国际顶级开源项目,AI大模型落地目标100个
中国开源生态迎来政策强引擎。 近日,《北京市开源生态体系建设实施方案(2026— 2028 年)正式印发,明确提出:到 2028 年,培育 10 个具有国际影响力的开源项目(其中不少于 5 个达到国际引领水平),打造 30 个国内明星开源项目(AI领域占比超1/3),并推动 100 个行业大模型实现规模化落地应用。 这一方案标志着北京正以国家战略高度系统性构建全球领先的开源创新高地。

艾伦人工智能研究所推出 Molmo 2 开源视频语言模型
近日,艾伦人工智能研究所(Ai2)发布了全新的 Molmo2开源视频语言模型。 这一系列新模型和相关训练数据展示了该非营利机构在开源领域的坚定承诺,特别是在企业希望掌控模型使用的背景下,这无疑是一项重大利好。 Molmo2包含几种不同的模型版本,包括基于阿里巴巴 Qwen3语言模型的 Molmo2-4B 和 Molmo2-8B,此外还有基于 Ai2Olmo 语言模型的完全开源版本 Molmo2-O-7B。

加码开源技术,英伟达收购 AI 软件公司 SchedMD
AI在线 12 月 16 日消息,英伟达当地时间周一宣布,已收购人工智能软件公司 SchedMD。 此举彰显了这家芯片设计巨头对开源技术的加倍投入,并进一步加码人工智能生态系统投资,以应对日益激烈的竞争。 除了高性能芯片,英伟达同时也提供涵盖物理仿真、自动驾驶等多个领域的自有 AI 模型,并以开源软件形式供研究人员和企业使用。

智谱开源 GLM-4.6V 系列:106B 原生支持 Function Call,轻量版 9B 免费商用
智谱正式并上线开源 GLM-4.6V 多模态大模型系列,含基础版 GLM-4.6V(总参106B,激活12B)与轻量版 GLM-4.6V-Flash(9B)。 新模型将上下文窗口提升至128k tokens,视觉理解精度达同参数 SOTA,首次把 Function Call 能力原生融入视觉模型,打通「视觉感知 → 可执行行动」完整链路。 API 价格较 GLM-4.5V 下降50%,输入1元 / 百万 tokens、输出3元 / 百万 tokens;GLM-4.6V-Flash 完全免费,已集成 GLM Coding Plan 与专用 MCP 工具,开发者可零成本商用。
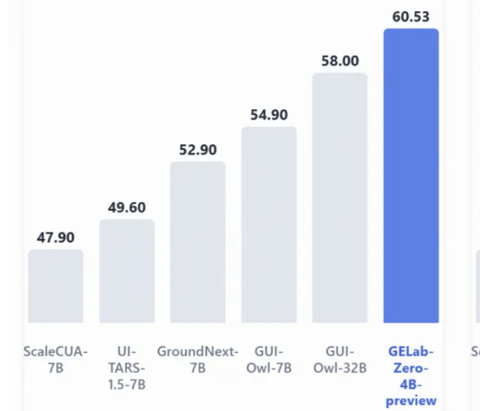
阶跃开源4B Agent模型,跑通所有安卓设备,手搓党一键部署
GELab-Zero团队 投稿. 量子位 | 公众号 QbitAI首次将GUI Agent模型与完整配套基建同步开放,支持手搓党一键部署! 这就是阶跃星辰刚刚开源的GELab-Zero。
Zleap技术解密:后RAG时代已来,SAG重新定义AI搜索
大家好,我是Jomy,是智跃Zleap的CEO,也是Zleap产品和技术的主要设计者。 此前在报道中,我曾粗略介绍过Zleap产品背后的技术:一个能帮助CEO自动整理、总结海量企业内部信息的智能Agent。 今天,我要正式为大家介绍驱动这个Agent的底层技术:SAG。

今晚19点|2GPU+2CPU微调超大模型,带你上手开源KTransformers
视点 发自 凹非寺. 量子位|公众号 QbitAI2GPU 2CPU就可以在本地微调自己的DeepSeek 671B / Kimi K2 1TB超大模型了。 这就是前两天量子位介绍的明星开源项目KTransformers,吸引了很多伙伴的关注。

Cursor“自研”模型套壳国产开源?网友:毕竟好用又便宜
美国顶流AI产品“套壳”中国开源大模型,这事儿上“热搜”了(doge)。 𝕏网友都在感叹:大家都认为中国大模型正在迎头赶上。 不,它们已经赶上了。

开源Agent编程模型MiniMax M2,性价比之王
开源模型之王易主,不过还是国产模型! 行业评测里,它在 Artificial Analysis 榜单综合进入全球前五、开源模型第一梯队,重点在编程、工具使用、深度搜索这些 Agent 核心能力上表现亮眼。 MiniMax 刚发布并开源M2模型,它采用稀疏 MoE 架构,总参数 230B,但推理时仅激活约 10B,这意味着在保持高性能的同时,把算力开销和延迟压下来了。

世界模型有了开源基座Emu3.5!拿下多模态SOTA,性能超越Nano Banana
最新最强的开源原生多模态世界模型——北京智源人工智能研究院(BAAI)的悟界·Emu3.5来炸场了。 图、文、视频任务一网打尽,不仅能画图改图,还能生成图文教程,视频任务更是增加了物理真实性。 先感受一下它的高精度操作:一句话消除手写痕迹。

OpenAI 再出开源力作 Safeguard 模型:可完整展示 AI“思维链”,强化内容分类能力
10 月 30 日消息,科技媒体 NeoWin 昨日(10 月 29 日)发布博文,报道称 OpenAI 公司推出 gpt-oss-safeguard-120b 和 gpt-oss-safeguard-20b 两款开源权重模型,专门用于根据用户提供的策略对内容进行推理、分类和标记。 这是继今年早些时候发布 gpt-oss 系列推理模型后,OpenAI 在开源领域的又一重要举措。 新模型是此前 gpt-oss 模型的微调版本,同样遵循宽松的 Apache 2.0 许可证,允许任何开发者免费使用、修改和商业部署。

DeepSeek-OCR:用视觉模态给长文本“瘦身”,大模型处理效率再突破
在大语言模型(LLMs)不断拓展能力边界的今天,长文本处理始终是道绕不开的坎——文本序列每增加一倍,计算量就可能翻四倍,像处理一本几十万字的书籍、一份上千页的金融报告时,内存溢出、推理卡顿成了常态。 但DeepSeek团队最近开源的DeepSeek-OCR模型,给出了一个全新解法:把文本“画”成图像,用视觉Token实现高效压缩。 原本需要1000个文本Token存储的内容,现在100个视觉Token就能搞定,还能保持97%的OCR精度。

美团视频生成模型来了!一出手就是开源SOTA
美团,你是跨界上瘾了是吧! (doge)没错,最新开源SOTA视频模型,又是来自这家“送外卖”的公司。 模型名为LongCat-Video,参数13.6B,支持文生/图生视频,视频时长可达数分钟。

最强OCR竟然不是DeepSeek、Paddle!HuggingFace新作:六大顶尖开源OCR模型横评!继DS后又杀出匹黑马!
编辑 | 听雨在AI快速进化的浪潮中,文字和图像的界限正在被重新定义。 那些能“看懂”文件、理解图表、读出语义的视觉语言模型(VLM),正在让传统OCR(光学字符识别)进入一个全新的智能阶段。 如果你还以为OCR只是“识字”的工具,那你可能错过了它真正的革命性变化。

李开复:美国在AI硬件赛道已败给中国!中国AI算力将是美国十倍!警告AI速度失控:先上车再修路,将酿成重大事故!
编辑 | 云昭在旧金山TED AI大会上,创新工场董事长、AI科学家李开复通过视频连线发表演讲,罕见地直言:“在AI硬件和机器人制造方面,美国正在被中国超越。 ”李表示,这一点也不夸张。 在AI硬件与机器人赛道,中国的领先正在成为事实。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉