Transformer

英伟达推出 Nemotron 3:混合架构提升 AI 代理处理效率
英伟达近日发布了其全新的 Nemotron 3 系列,这一系列产品结合了 Mamba 和 Transformer 两种架构,旨在高效处理长时间上下文窗口,同时减少资源消耗。 Nemotron 3 系列专为基于代理的人工智能系统设计,这类系统能够自主执行复杂任务,持续进行长时间的交互。 新产品系列包括三个型号:Nano、Super 和 Ultra。

AI“手指难题”翻车,6 根手指暴露 Transformer 致命缺陷
最近几天,整个互联网陷入阴影 —— AI,在用数手指嘲笑人类。 人类给 AI 的这道题,指令很简单:在图中的每根手指上,依次标出数字。 当然题目中有个小陷阱,就是这只手其实有六个手指。
谷歌新架构突破Transformer超长上下文瓶颈!Hinton灵魂拷问:后悔Open吗?
鱼羊 发自 凹非寺. 量子位 | 公众号 QbitAITransformer的提出者谷歌,刚刚上来给了Transformer梆梆就两拳(doge)。 两项关于大模型新架构的研究一口气在NeurIPS 2025上发布,通过“测试时训练”机制,能在推理阶段将上下文窗口扩展至200万token。
Transformer作者爆料GPT-5.1内幕!OpenAI内部命名规则变乱了
鹭羽 发自 凹非寺. 量子位 | 公众号 QbitAI我们正在经历一次静悄悄、但本质性的AI范式转换。 它的意义不亚于Transformer本身。

Databricks联创Konwinski警告:美国AI研究优势正在流失
Databricks联合创始人Andy Konwinski在本周Cerebral Valley AI Summit上表示,美国正将AI研究主导权让予中国,他称这一趋势对民主制度构成“生存级”威胁。 Konwinski援引伯克利与斯坦福博士生反馈指出,过去一年值得关注的AI新思路约半数出自中国团队,比例显著高于此前。 Konwinski与NEA前合伙人Pete Sonsini、Antimatter CEO Andrew Krioukov于 2024 年共同创立风投机构Laude,并同步运营非营利加速器Laude Institute,向高校研究者提供无附加条件的资助。

最具争议性研究:大模型中间层输出可 100% 反推原始输入
最近,一篇名为《Language Models are Injective and Hence Invertible》的论文在学术界和科技圈引起了广泛讨论,甚至连老马的 Grok 官方也下场转发。 这篇论文出自意大利罗马第一大学(Sapienza University of Rome)的 GLADIA Research Lab,文中提出了一个颇有争议却又耐人寻味的观点:主流的 Transformer 语言模型在信息处理过程中几乎不会丢失任何输入内容,从数学意义上看,它们是可逆的。 换句话说,模型的隐藏状态并不是模糊的语义压缩,而是一种能够完整保留输入信息的精确重编码。

「我受够了Transformer」:其作者Llion Jones称AI领域已僵化,正错失下一个突破
这两天,VentureBeat 一篇报道在 Hacker News 上引发热议。 颠覆性论文《Attention is all you need》的作者之一,现任 Sakana AI CTO 的 Llion Jones 在近日的 TED AI 大会上表示他已经厌倦了 Transformer。 是什么,让这位 Transformer 的创造者发出了如此言论?
苹果AI选Mamba:Agent任务比Transformer更好
闻乐 发自 凹非寺. 量子位 | 公众号 QbitAI都说苹果AI慢半拍,没想到新研究直接在Transformer头上动土。 「Mamba 工具」,在Agent场景更能打!

不靠英伟达,中科院在国产 GPU 上跑通 76B 类脑大模型
过去几年,大模型几乎都依赖 Transformer,它支撑了 GPT、Claude、Gemini 等一众前沿模型的进步,但也一直被诟病:一旦文本变长,计算量和内存消耗就会成倍膨胀,百万级 token 几乎不可承受。 与此同时,大模型训练几乎完全依赖 NVIDIA 的 GPU 体系。 从算力到软件栈,整个行业被牢牢绑定在 CUDA 上,硬件自主化成了迟迟迈不过去的门槛。

Transformer危!谷歌MoR架构发布:内存减半推理速度还翻倍
超越Transformer,谷歌推出全新底层架构——. Mixture-of-Recursions(MoR),注意不是MoE,它能推理速度提高2倍,而KV内存直接减半! 而且All in One,首次在单一框架中实现,用同一组参数处理不同任务的同时,进行动态分配计算资源。

Mamba一作预告新架构!长文论述Transformer≠最终解法
Mamba一作最新大发长文! 主题只有一个,即探讨两种主流序列模型——状态空间模型(SSMs)和Transformer模型的权衡之术。 简单介绍下,Mamba就是一种典型的SSMs,它建立在更现代的适用于深度学习的结构化SSM基础上,与经典架构RNN有相似之处。

基于能量的Transformer横空出世!全面超越主流模型35%
时令 发自 凹非寺. 量子位 | 公众号 QbitAI. AI无需监督就能学习思考?

Transformer死角,只需500步后训练,循环模型突破256k长度泛化极限
线性循环模型(如 Mamba)和线性注意力机制都具备这样一个显著优势:它们能够处理极长的序列,这一能力对长上下文推理任务至关重要。 事实上,这正是它们相较于 Transformer 的关键优势 —— 后者受限于有限的上下文窗口,且在序列长度上的计算复杂度是二次的,成为性能瓶颈。 过去,循环模型面临的主要问题是性能不足:在处理短序列时,它们的表现往往不如 Transformer。

Meta新注意力机制突破Transformer上限,还用上了OpenAI的开源技术
Meta挖走OpenAI大批员工后,又用OpenAI的技术搞出新突破。 这是什么杀人又诛心(doge)? 新架构名为2-Simplicial Transformer,重点是通过修改标准注意力,让Transformer能更高效地利用训练数据,以突破当前大模型发展的数据瓶颈。
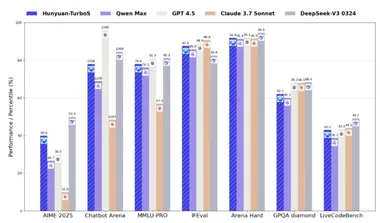
腾讯混元 TurboS 技术报告全面揭秘,560B参数混合Mamba架构
腾讯发布了混元 TurboS 技术报告,揭示了其旗舰大语言模型 TurboS 的核心创新与强大能力。 根据全球权威大模型评测平台 Chatbot Arena 的最新排名,混元 TurboS 在239个参赛模型中位列第七,成为国内仅次于 Deepseek 的顶尖模型,并在国际上仅落后于谷歌、OpenAI 及 xAI 等几家机构。 混元 TurboS 模型的架构采用了创新的 Hybrid Transformer-Mamba 结构,这种新颖的设计结合了 Mamba 架构在处理长序列上的高效性与 Transformer 架构在上下文理解上的优势,从而实现了性能与效率的平衡。

字节Seed 团队推出 PHD-Transformer,成功扩展预训练长度,解决 KV 缓存问题!
近日,字节跳动的 Seed 团队在人工智能领域再传佳音,推出了一种新型的 PHD-Transformer(Parallel Hidden Decoding Transformer),这项创新突破了预训练长度的限制,有效解决了推理过程中的 KV 缓存膨胀问题。 随着大型推理模型的迅速发展,研究人员在后训练阶段尝试通过强化学习方法来生成更长的推理链,并在复杂的推理任务上取得了显著成果。 受到启发,字节 Seed 团队决定探索在预训练阶段进行长度扩展的可能性。

姚班学霸、OpenAI姚顺雨:AI发展已从模型创新到产品思维
随着人工智能(AI)技术的不断成熟,业内专家提出,AI 发展的重心正在发生显著转变。 从早期的模型训练和算法创新,转向更加关注任务定义与评估优化。 这一观点由 OpenAI 的研究员姚顺雨提出,他强调,在 AI 的下半场,产品思维将成为推动技术应用和商业化的关键。

算法不重要,AI的下一个范式突破,「解锁」新数据源才是关键
众所周知,人工智能在过去十五年里取得了令人难以置信的进步,尤其是在最近五年。 回顾一下人工智能的「四大发明」吧:深度神经网络→Transformer 语言模型→RLHF→推理,基本概括了 AI 领域发生的一切。 我们有了深度神经网络(主要是图像识别系统),然后是文本分类器,然后是聊天机器人,现在我们又有了推理模型。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉