Transformer

Mamba作者新作:将Llama3蒸馏成混合线性 RNN
Transformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transformer 也因此难以处理非常长的文本。前段时间,Mamba 的出现打破了这一局面,它可以随上下文长度的增加实现线性扩展。随着 Mamba 的发布,这些状态空间模型 (SSM) 在中小型规模上已经可以与 Transformer 匹敌,甚至超越 Transformer,同时还能维持

元象推出国内首个基于物理的3D动作生成模型MotionGen
www.MotionGen.cn 一句话生成复杂3D动作,效果惊艳!测试期可申请免费试用。3D内容制作领域,生成逼真的角色动作生成是一个持续挑战,传统方法依赖大量的手K制作,或昂贵动作捕捉设备,效率低、成本高、难以生成一般运动任务或适应复杂场景和交互。元象XVERSE推出国内首个基于物理的3D动作生成模型MotionGen,创新性融合大模型、物理仿真和强化学习等前沿算法,让用户输入简单文本指令,就能快速生成逼真、流畅、复杂的3D动作,效果惊艳,标志着中国3D AIGC领域的重大突破。现在起,零经验创作者也能轻松上手

统一transformer与diffusion!Meta融合新方法剑指下一代多模态王者
本文引入了 Transfusion,这是一种可以在离散和连续数据上训练多模态模型的方法。一般来说,多模态生成模型需要能够感知、处理和生成离散元素(如文本或代码)和连续元素(如图像、音频和视频数据)。在离散模态领域,以预测下一个词为目标的语言模型占据主导地位,而在生成连续模态方面,扩散模型及其泛化形式则是当前最先进技术。研究者一直试图将语言模型与扩散模型结合,一种方法是直接扩展语言模型,使其能够利用扩散模型作为一个工具,或者将一个预训练的扩散模型嫁接到语言模型上。另一种替代方案是对连续模态进行量化处理,然后在离散的

机器人策略学习的Game Changer?伯克利提出Body Transformer
过去几年间,Transformer 架构已经取得了巨大的成功,同时其也衍生出了大量变体,比如擅长处理视觉任务的 Vision Transformer(ViT)。本文要介绍的 Body Transformer(BoT) 则是非常适合机器人策略学习的 Transformer 变体。我们知道,物理智能体在执行动作的校正和稳定时,往往会根据其感受到的外部刺激的位置给出空间上的响应。比如人类对这些刺激的响应回路位于脊髓神经回路层面,它们专门负责单个执行器的响应。起校正作用的局部执行是高效运动的主要因素,这对机器人来说也尤为重

首个全自动科学发现AI系统,Transformer作者创业公司Sakana AI推出AI Scientist
编辑 | ScienceAI一年前,谷歌最后一位 Transformer 论文作者 Llion Jones 离职创业,与前谷歌研究人员 David Ha共同创立人工智能公司 Sakana AI。Sakana AI 声称将创建一种基于自然启发智能的新型基础模型!现在,Sakana AI 交上了自己的答卷。Sakana AI 宣布推出 AI Scientist,这是世界上第一个用于自动化科学研究和开放式发现的 AI 系统!从构思、编写代码、运行实验和总结结果,到撰写整篇论文和进行同行评审,AI Scientist 开启

Falcon Mamba 7B 开源模型登顶:换掉 Transformer,任意长序列都能处理
只是换掉 Transformer 架构,立马性能全方位提升,问鼎同规模开源模型!(注意力机制不存在了)这就是最新 Falcon Mamba 7B 模型。它采用 Mamba 状态空间语言模型架构来处理各种文本生成任务。通过取消传统注意力机制,有效提升了模型处理长序列时计算效率低下的问题。它可以处理无限长序列,但内存需求不增加。无论上下文多长,生成每个 token 的时间基本一样。由此,Falcon Mamba 模型性能全方位提升,打败一众 Transformer 架构模型,如 Llama-3.1(8B)、Mistra

混合专家更有主见了,能感知多模态分情况行事,Meta提出模态感知型专家混合
混合专家,也得术业有专攻。对于目前的混合模态基础模型,常用的架构设计是融合特定模态的编码器或解码器,但这种方法存在局限:无法整合不同模态的信息,也难以输出包含多种模态的内容。为了克服这一局限,Meta FAIR 的 Chameleon 团队在近期的论文《Chameleon: Mixed-modal early-fusion foundation models》中提出了一种新的单一 Transformer 架构,它可以根据下一个 token 的预测目标,对由离散图像和文本 token 组成的混合模态序列进行建模,从而

八问八答搞懂Transformer内部运作原理
七年前,论文《Attention is all you need》提出了 transformer 架构,颠覆了整个深度学习领域。如今,各家大模型都以 transformer 架构为基础,但 transformer 内部运作原理,仍是一个未解之谜。去年,transformer 论文作者之一 Llion Jones 宣布创立人工智能公司 Sakana AI。近期,Sakana AI 发表了一篇题为《Transformer Layers as Painters》的论文,探究了预训练 transformer 中的信息流,并
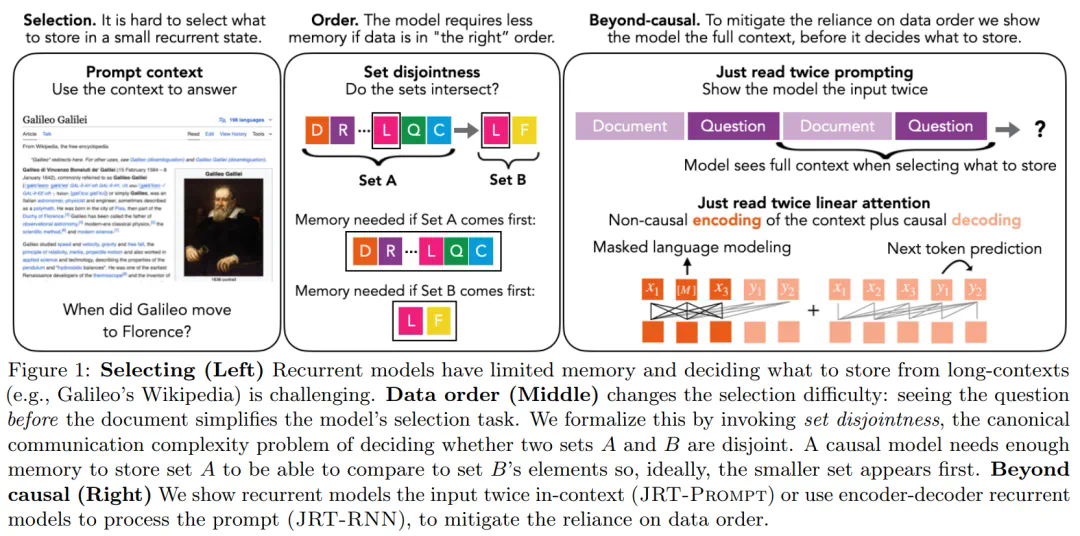
小技巧大功效,「仅阅读两次提示」让循环语言模型超越Transformer++
在当前 AI 领域,大语言模型采用的主流架构是 Transformer。不过,随着 RWKV、Mamba 等架构的陆续问世,出现了一个很明显的趋势:在语言建模困惑度方面与 Transformer 较量的循环大语言模型正在快速进入人们的视线。令人兴奋的是,这些架构在推理期间使用了恒定量的内存。不过,受制于有限的内存,循环语言模型(LM)无法记忆并使用长上下文中的所有信息,这导致了上下文学习(in-context learning,ICL)质量的不佳。因此,获得高效大语言模型的关键挑战在于选择存储或者丢弃哪些信息。在最
大脑如何处理语言?普林斯顿团队对Transformer模型进行分析
编辑 | 萝卜皮在处理语言时,大脑会部署专门的计算来从复杂的语言结构中构建含义。基于 Transformer 架构的人工神经网络是自然语言处理的重要工具。普林斯顿大学的研究人员探讨了 Transformer 模型和人类大脑在语言处理中的功能特殊化问题。Transformer 通过结构化电路计算整合单词间的上下文信息。不过,当前的研究主要集中于这些电路生成的内部表征(「嵌入」)。研究人员直接分析电路计算:他们将这些计算解构为功能专门的「transformations」,将跨词语的上下文信息整合在一起。利用参与者聆听自

彻底改变语言模型:全新架构TTT超越Transformer,ML模型代替RNN隐藏状态
从 125M 到 1.3B 的大模型,性能都有提升。难以置信,这件事终于发生了。一种全新的大语言模型(LLM)架构有望代替至今在 AI 领域如日中天的 Transformer,性能也比 Mamba 更好。本周一,有关 Test-Time Training(TTT)的论文成为了人工智能社区热议的话题。论文链接:、加州大学伯克利分校、加州大学圣迭戈分校和 Meta。他们设计了一种新架构 TTT,用机器学习模型取代了 RNN 的隐藏状态。该模型通过输入 token 的实际梯度下降来压缩上下文。该研究作者之一 Karan

全球首款 Transformer 专用 AI 芯片 Sohu 登场:每秒可处理 50 万个 tokens,比英伟达 H100 快 20 倍
Etched 公司宣布完成 1.2 亿美元(IT之家备注:当前约 8.73 亿元人民币) A 轮融资,将用于开发和销售全球首款 Transformer 专用集成电路(ASIC)芯片 Sohu。IT之家查询公开资料,Etched 公司由两名哈佛大学辍学生加文・乌伯蒂(Gavin Uberti)和克里斯・朱(Chris Zhu)创立,成立时间不到 2 年。Sohu 芯片最大的亮点在于直接把 Transformer 架构蚀刻到芯片中,乌伯蒂称 Sohu 采用台积电的 4 纳米工艺制造,推理性能大大优于 GPU 和其他通用

再战Transformer!原作者带队的Mamba 2来了,新架构训练效率大幅提升
自 2017 年被提出以来,Transformer 已经成为 AI 大模型的主流架构,一直稳居语言建模方面 C 位。但随着模型规模的扩展和需要处理的序列不断变长,Transformer 的局限性也逐渐凸显。一个很明显的缺陷是:Transformer 模型中自注意力机制的计算量会随着上下文长度的增加呈平方级增长。几个月前,Mamba 的出现打破了这一局面,它可以随上下文长度的增加实现线性扩展。随着 Mamba 的发布,这些状态空间模型 (SSM) 在中小型规模上已经实现了与 Transformers 匹敌,甚至超越

单GPU训练一天,Transformer在100位数字加法上就达能到99%准确率
乘法和排序也有效。自 2017 年被提出以来,Transformer 已成为 AI 大模型的主流架构,一直稳站 C 位。但所有研究者都不得不承认的是,Transformer 在算数任务中表现非常糟糕,尤其是加法,这一缺陷在很大程度上源于 Transformer 无法跟踪大范围数字中每个数字的确切位置。为了解决这个问题,来自马里兰大学、CMU 等机构的研究者向这一问题发起了挑战,他们通过在每个数字中添加一个嵌入来解决这个问题,该嵌入编码数字相对于开头的位置。该研究发现,只用一天时间在单个 GPU 上训练 20 位数字

Bengio等人新作:注意力可被视为RNN,新模型媲美Transformer,但超级省内存
序列建模的进展具有极大的影响力,因为它们在广泛的应用中发挥着重要作用,包括强化学习(例如,机器人和自动驾驶)、时间序列分类(例如,金融欺诈检测和医学诊断)等。在过去的几年里,Transformer 的出现标志着序列建模中的一个重大突破,这主要得益于 Transformer 提供了一种能够利用 GPU 并行处理的高性能架构。然而,Transformer 在推理时计算开销很大,主要在于内存和计算需求呈二次扩展,从而限制了其在低资源环境中的应用(例如,移动和嵌入式设备)。尽管可以采用 KV 缓存等技术提高推理效率,但 T
研究人员推出 xLSTM 神经网络 AI 架构:并行化处理 Token、有望迎战 Transformer
研究人员 Sepp Hochreiter 和 Jürgen Schmidhuber 在 1997 年共同提出了长短期记忆(Long short-term memory,LSTM)神经网络结构,可用来解决循环神经网络(RNN)长期记忆能力不足的问题。而最近 Sepp Hochreiter 在 arXiv 上发布论文,提出了一种名为 xLSTM(Extended LSTM)的新架构,号称可以解决 LSTM 长期以来“只能按照时序处理信息”的“最大痛点”,从而“迎战”目前广受欢迎的 Transformer 架构。IT之家
原作者带队,LSTM真杀回来了!
LSTM:这次重生,我要夺回 Transformer 拿走的一切。20 世纪 90 年代,长短时记忆(LSTM)方法引入了恒定误差选择轮盘和门控的核心思想。三十多年来,LSTM 经受住了时间的考验,并为众多深度学习的成功案例做出了贡献。然而,以可并行自注意力为核心 Transformer 横空出世之后,LSTM 自身所存在的局限性使其风光不再。当人们都以为 Transformer 在语言模型领域稳坐江山的时候,LSTM 又杀回来了 —— 这次,是以 xLSTM 的身份。5 月 8 日,LSTM 提出者和奠基者 Se

DeepMind升级Transformer,前向通过FLOPs最多可降一半
引入混合深度,DeepMind 新设计可大幅提升 Transformer 效率。Transformer 的重要性无需多言,目前也有很多研究团队致力于改进这种变革性技术,其中一个重要的改进方向是提升 Transformer 的效率,比如让其具备自适应计算能力,从而可以节省下不必要的计算。正如不久前 Transformer 架构的提出之一、NEAR Protocol 联合创始人 Illiya Polosukhin 在与黄仁勋的对话中说到的那样:「自适应计算是接下来必须出现的。我们要关注,在特定问题上具体要花费多少计算资
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉