Transformer

直接扩展到无限长,谷歌Infini-Transformer终结上下文长度之争
不知 Gemini 1.5 Pro 是否用到了这项技术。谷歌又放大招了,发布下一代 Transformer 模型 Infini-Transformer。Infini-Transformer 引入了一种有效的方法,可以将基于 Transformer 的大型语言模型 (LLM) 扩展到无限长输入,而不增加内存和计算需求。使用该技术,研究者成功将一个 1B 的模型上下文长度提高到 100 万;应用到 8B 模型上,模型能处理 500K 的书籍摘要任务。自 2017 年开创性研究论文《Attention is All Yo
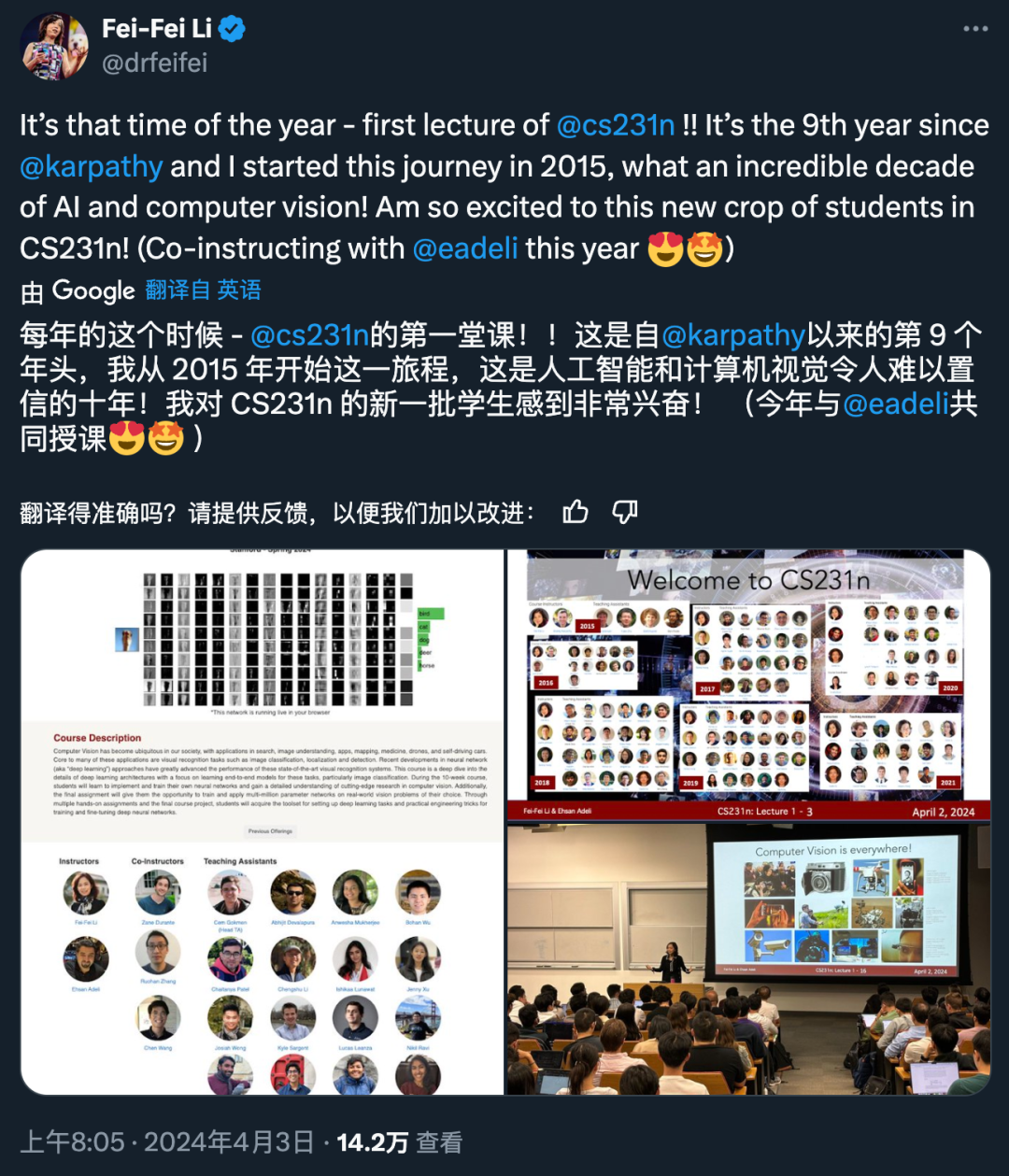
李飞飞主讲,斯坦福2024 CS231n开课,依旧座无虚席
「这是自 Karpathy 和我 2015 年启动这门课程以来的第 9 个年头,这是人工智能和计算机视觉令人难以置信的十年!」知名 AI 科学家李飞飞的计算机视觉「神课」CS231n,又一次开课了。总共 600 多位学生报名,第一堂课的现场座无虚席:从 2015 年到如今,CS231n 已经走到九个年头,也成为了一代计算机视觉专业学生心中的「必修课」:虽然课程代码不变,但可以猜到,2024 年的课程相比 2021 年版本的课程有不少新增内容,这还要归因于视觉生成技术三年来的巨大飞跃。在今年初的国际消费类电子产品展览

Attention isn’t all you need!Mamba混合大模型开源:三倍Transformer吞吐量
Mamba 时代来了?自 2017 年开创性研究论文《Attention is All You Need》问世以来,transformer 架构就一直主导着生成式人工智能领域。然而,transformer 架构实际上有两个显著缺点:内存占用大:Transformer 的内存占用量随上下文长度而变化。这使得在没有大量硬件资源的情况下运行长上下文窗口或大量并行批处理变得具有挑战性,从而限制了广泛的实验和部署。 随着上下文长度的增加,推理速度会变慢:Transformer 的注意力机制随序列长度呈二次方扩展,并且会降低吞

谁将替代 Transformer?
Transformer 由于其处理局部和长程依赖关系的能力以及可并行化训练的特点,一经问世,逐步取代了过去的 RNN(循环神经网络)与 CNN(卷积神经网络),成为 NLP(自然语言处理)前沿研究的标准范式。 今天主流的 AI 模型和产品——OpenAI 的ChatGPT、谷歌的 Bard、Anthropic 的 Claude,Midjourney、Sora到国内智谱 AI 的 ChatGLM 大模型、百川智能的 Baichuan 大模型、Kimi chat 等等——都是基于Transformer 架构。 Transformer 已然代表了当今人工智能技术无可争议的黄金标准,其主导地位至今无人能撼动。

OpenAI 公关跳起来捂他嘴:Transformer 作者公开承认参与 Q*!
Transformer 作者中唯一去了 OpenAI 的那位,公开承认了:他参与了 Q * 项目,是这项新技术的发明者之一。这几天除了英伟达老黄组局把 Transformer 作者聚齐,他们中的几位还接受了连线杂志的采访,期间出了这么一个小插曲。当记者试图询问 Lukasz Kaiser 更多关于 Q * 的问题时时,OpenAI 的公关人员几乎跳过桌子去捂他的嘴。结合阿尔特曼在接受采访时,毫不迟疑地拒绝了相关提问,“我们还没准备好谈论这个话题”。神秘 Q*,成了 OpenAI 当前最需要保守的秘密之一。不过对于

如何应对Transformer的计算局限?思维链推理提高神经网络计算
编辑 | 白菜叶你的小学老师可能没有教你如何做 20 位数字的加减法。但如果你知道如何加减较小的数字,你所需要的只是纸和铅笔以及一点耐心。从个位开始,一步步向左,很快你就能轻松地积累出千万亿的数字。像这样的问题对人类来说很容易解决,但前提是我们用正确的方式解决它们。「我们人类解决这些问题的方式并不是『盯着它然后写下答案』。」哈佛大学机器学习研究员 Eran Malach 表示,「我们实际上是走过这些台阶的。」这一见解启发了研究人员研究为 ChatGPT 等聊天机器人提供支持的大型语言模型。这些系统可以解决涉及少量算

解开化学语言模型中的「黑匣子」,Transformer可快速学习分子的部分结构,但手性学习困难
编辑 | X近年来,自然语言处理(NLP)模型,特别是 Transformer 模型,已应用于像 SMILES 这样的分子结构的文字表示。然而,关于这些模型如何理解化学结构的研究很少。为了解决这个黑匣子,东京大学的研究人员使用代表性的 NLP 模型 Transformer 研究了 SMILES 的学习进度与化学结构之间的关系。研究表明,虽然 Transformer 可以快速学习分子的部分结构,但它需要扩展训练才能理解整体结构。一致的是,从训练开始到结束,使用不同学习步骤的模型生成的描述符进行分子特性预测的准确性是相

补齐Transformer规划短板,田渊栋团队的Searchformer火了
Transformer 强大的泛化能力再次得到证明!最近几年,基于 Transformer 的架构在多种任务上都表现卓越,吸引了世界的瞩目。使用这类架构搭配大量数据,得到的大型语言模型(LLM)等模型可以很好地泛化用于真实世界用例。尽管有如此成功,但基于 Transformer 的架构和 LLM 依然难以处理规划和推理任务。之前已有研究证明 LLM 难以应对多步规划任务或高阶推理任务。为了提升 Transformer 的推理和规划性能,近些年研究社区也提出了一些方法。一种最常见且有效的方法是模拟人类的思考过程:先生
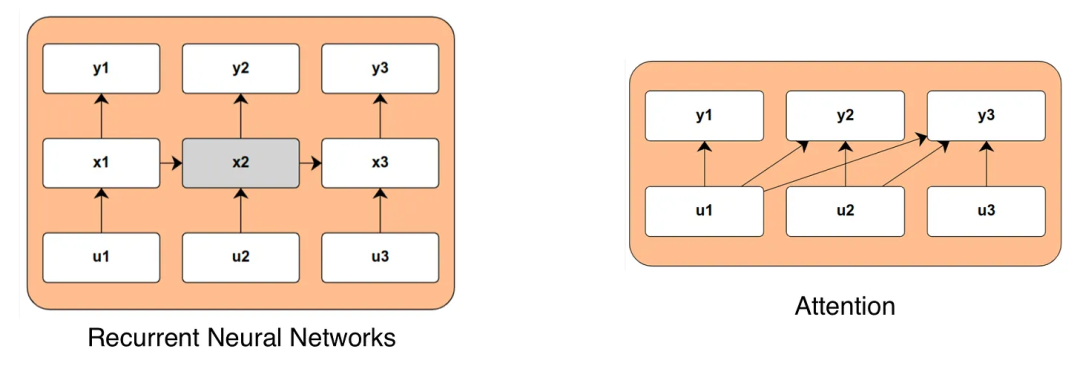
我们还需要Transformer中的注意力吗?
状态空间模型正在兴起,注意力是否已到尽头?最近几周,AI 社区有一个热门话题:用无注意力架构来实现语言建模。简要来说,就是机器学习社区有一个长期研究方向终于取得了实质性的进展,催生出 Mamba 两个强大的新模型:Mamba 和 StripedHyena。它们在很多方面都能比肩人们熟知的强大模型,如 Llama 2 和 Mistral 7B。这个研究方向就是无注意力架构,现在也正有越来越多的研究者和开发者开始更严肃地看待它。近日,机器学习科学家 Nathan Lambert 发布了一篇题为《状态空间 LLM:我们需
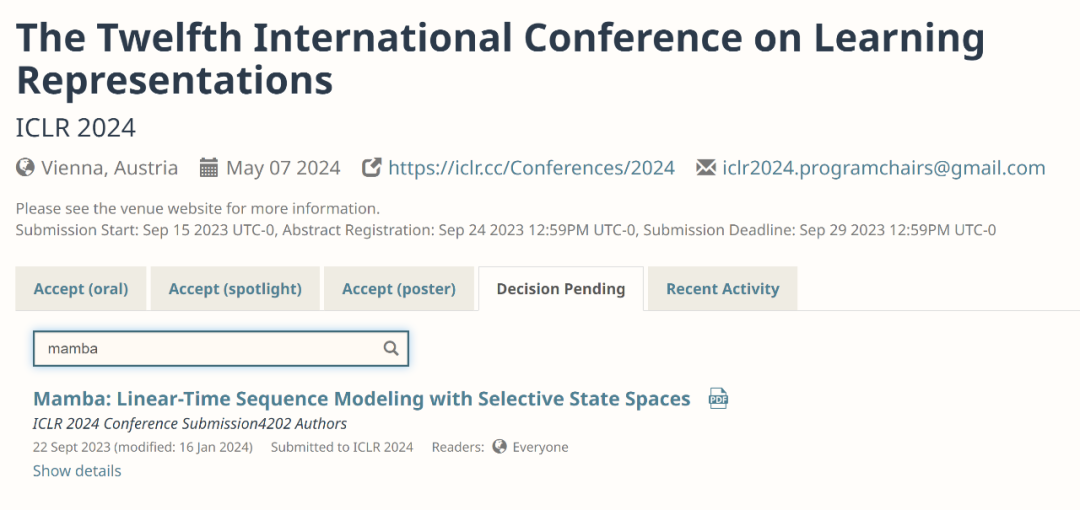
Mamba论文为什么没被ICLR接收?AI社区沸腾了
基于 Mamba 的创新正不断涌现,但原论文却被 ICLR 放到了「待定区」。2023 年,Transformer 在 AI 大模型领域的统治地位被撼动了。发起挑战的新架构名叫「Mamba」,它是一种选择性状态空间模型( selective state space model),在语言建模方面可以媲美甚至击败 Transformer。而且,它可以随上下文长度的增加实现线性扩展,其性能在实际数据中可提高到百万 token 长度序列,并实现 5 倍的推理吞吐量提升。在发布之后的一个多月里,Mamba 逐渐展现出自己的影

岩芯数智推出非Attention机制大模型,支持离线端侧部署
1月24日,上海岩芯数智人工智能科技有限公司对外推出了一个非Attention机制的通用自然语言大模型——Yan模型。岩芯数智发布会上称,Yan模型使用了全新自研的“Yan架构”代替Transformer架构,相较于Transformer,Yan架构的记忆能力提升3倍、速度提升7倍的同时,实现推理吞吐量的5倍提升。岩芯数智CEO刘凡平认为,以大规模著称的Transformer,在实际应用中的高算力和高成本,让不少中小型企业望而却步。其内部架构的复杂性,让决策过程难以解释;长序列处理困难和无法控制的幻觉问题也限制了大

MoE与Mamba强强联合,将状态空间模型扩展到数百亿参数
性能与 Mamba 一样,但所需训练步骤数却少 2.2 倍。状态空间模型(SSM)是近来一种备受关注的 Transformer 替代技术,其优势是能在长上下文任务上实现线性时间的推理、并行化训练和强大的性能。而基于选择性 SSM 和硬件感知型设计的 Mamba 更是表现出色,成为了基于注意力的 Transformer 架构的一大有力替代架构。近期也有一些研究者在探索将 SSM 和 Mamba 与其它方法组合起来创造更强大的架构,比如机器之心曾报告过《Mamba 可以替代 Transformer,但它们也能组合起来使

视觉Mamba模型的Swin时刻,中国科学院、华为等推出VMamba
Transformer 在大模型领域的地位可谓是难以撼动。不过,这个AI 大模型的主流架构在模型规模的扩展和需要处理的序列变长后,局限性也愈发凸显了。Mamba的出现,正在强力改变着这一切。它优秀的性能立刻引爆了AI圈。上周四, Vision Mamba(Vim)的提出已经展现了它成为视觉基础模型的下一代骨干的巨大潜力。仅隔一天,中国科学院、华为、鹏城实验室的研究人员提出了 VMamba:一种具有全局感受野、线性复杂度的视觉 Mamba 模型。这项工作标志着视觉 Mamba 模型 Swin 时刻的来临。论文标题:V

Transformer的无限之路:位置编码视角下的长度外推综述
在自然语言处理(Natural Language Processing,NLP)领域,Transformer 模型因其在序列建模中的卓越性能而受到广泛关注。然而,Transformer 及在其基础之上的大语言模型(Large Language Models,LLMs)都不具备有效长度外推(Length Extrapolation)的能力。这意味着,受限于其训练时预设的上下文长度限制,大模型无法有效处理超过该长度限制的序列。文本续写和语言延展是人类语言的核心能力之一,与之相对的,长度外推是语言模型智能进化的重要方向,
Nat.Commun.|山东大学团队基于图transformer开发了一种稀有细胞群组学分析方法
编辑 | 萝卜皮稀有细胞群是肿瘤进展和治疗反应的关键,提供了潜在的干预目标。然而,它们的计算识别和分析通常落后于主要细胞类型。为了填补这一空白,山东大学的研究团队引入了 MarsGT:使用单细胞图 transformer 进行稀有群体推断的多组学分析。它使用基于概率的异质图 transformer 对单细胞多组学数据识别稀有细胞群。MarsGT 在识别 550 个模拟数据集和 4 个真实人类数据集中的稀有细胞方面优于现有工具。该研究以「MarsGT: Multi-omics analysis for rare po

面向超长上下文,大语言模型如何优化架构,这篇综述一网打尽了
作者重点关注了基于 Transformer 的 LLM 模型体系结构在从预训练到推理的所有阶段中优化长上下文能力的进展。ChatGPT 的诞生,让基于 Transformer 的大型语言模型 (LLM) 为通用人工智能(AGI)铺开了一条革命性的道路,并在知识库、人机交互、机器人等多个领域得到应用。然而,目前存在一个普遍的限制:由于资源受限,当前大多 LLM 主要是在较短的文本上进行预训练,导致它们在较长上下文方面的表现较差,而长上下文在现实世界的环境中是更加常见的。最近的一篇综述论文对此进行了全面的调研,作者重点

你没有看过的全新版本,Transformer数学原理揭秘
近日,arxiv 上发布了一篇论文,对 Transformer 的数学原理进行全新解读,内容很长,知识很多,十二分建议阅读原文。2017 年,Vaswani 等人发表的 《Attention is all you need》成为神经网络架构发展的一个重要里程碑。这篇论文的核心贡献是自注意机制,这是 Transformers 区别于传统架构的创新之处,在其卓越的实用性能中发挥了重要作用。事实上,这一创新已成为计算机视觉和自然语言处理等领域人工智能进步的关键催化剂,同时在大语言模型的出现中也起到了关键作用。因此,了解

谁能撼动Transformer统治地位?Mamba作者谈LLM未来架构
自 2017 年被提出以来,Transformer 已成为 AI 大模型的主流架构,未来这种情况是一直持续,还是会有新的研究出现,我们不妨先听听身处 AI 圈的研究者是怎么想的。在大模型领域,一直稳站 C 位的 Transformer 最近似乎有被超越的趋势。这个挑战者就是一项名为「Mamba」的研究,其在语言、音频和基因组学等多种模态中都达到了 SOTA 性能。在语言建模方面,无论是预训练还是下游评估,Mamba-3B 模型都优于同等规模的 Transformer 模型,并能与两倍于其规模的 Transforme
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉