编辑 | 萝卜皮
稀有细胞群是肿瘤进展和治疗反应的关键,提供了潜在的干预目标。然而,它们的计算识别和分析通常落后于主要细胞类型。
为了填补这一空白,山东大学的研究团队引入了 MarsGT:使用单细胞图 transformer 进行稀有群体推断的多组学分析。
它使用基于概率的异质图 transformer 对单细胞多组学数据识别稀有细胞群。MarsGT 在识别 550 个模拟数据集和 4 个真实人类数据集中的稀有细胞方面优于现有工具。
该研究以「MarsGT: Multi-omics analysis for rare population inference using single-cell graph transformer」为题,于 2024 年 1 月 6 日发布在《Nature Communications》。

多细胞生物包含多种特化细胞。识别这些细胞类型在免疫治疗和临床场景中至关重要,因为它阐明了免疫机制,有助于设计靶向治疗,并通过揭示每个患者独特的细胞构成来支持个性化医疗。然而,当遇到稀有或瞬时表达的细胞时,困难就会出现。尽管稀缺,但稀有细胞群在各种生物过程中发挥着至关重要的作用。精确掌握这些稀有细胞群,并进行详细的描述,将进一步加深人类对肿瘤微环境和引导免疫治疗反应的复杂机制的理解。
单细胞 RNA 测序 (scRNA-seq) 的出现极大地提高了科学家识别单个细胞类型的能力,提供高分辨率的分子图谱,阐明细胞多样性和特定细胞内基因表达的复杂动态。大多数现有的稀有细胞识别工具,例如 FIRE、GapClust、TooManyCells、GiniClust、RaceID 和 SCMER,都面临着一些挑战,例如推断稀有细胞群时的高假阳性、肿瘤活检单细胞数据等复杂样本的性能有限、无法同时识别主要和稀有细胞类型以及超稀有细胞类型(<1% 的样本)的准确性受到影响。
这些问题可能源于稀有细胞的有限代表性,当仅依赖基因表达数据时,这可能导致与更常见的细胞群的分组不准确。单细胞 ATAC 测序 (scATAC-seq) 等技术创新可以进一步加速这一追求。当与 scRNA-seq 协同使用时,这些方法提供了有关增强子区域的部分调控数据,这对于保留细胞类型身份至关重要。这些宝贵的信息可用于构建基因调控网络,从而揭示对稀有细胞群的性质和功能的重要见解。
在这里,山东大学的研究人员开发了 MarsGT(Multi-omics analysis for rare population inference using single-cell Graph Transformer),这是一种端到端深度学习模型,用于从 scMulti-omics 数据中识别稀有细胞群。
MarsGT 整合了 scRNA-seq 和 scATAC-seq 数据,同时产生初级和稀有细胞群及其各自的调控关系。根据初始 scRNA-seq 和 scATAC-seq 数据构建包含细胞、基因和增强子的异质图,细胞内基因和峰的存在表示为边。
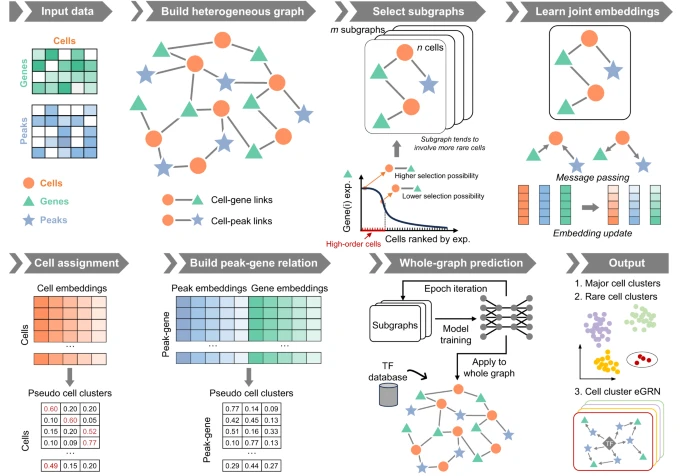
图示:MarsGT 架构。(来源:论文)
该团队认为,与仅在特定亚群中表达的基因相比,普遍表达的基因对于识别稀有细胞不太可能起关键作用。为了辨别稀有细胞,必须识别在目标细胞中高表达但在其他细胞中低表达或无表达的基因或峰。研究人员将此类基因和峰定义为稀有相关基因和峰。
根据表达/可及性的第一个四分位数,将细胞内的基因/峰分割成高或低选择区域。对于给定的细胞,基因/峰的选择概率由高选择区域中基因/峰表达/可达性的比例决定。在他们的多头注意力图 transformer 中,此类稀有相关基因和峰有更高的概率被采样到稀有细胞的关键特征。
多头注意力机制有助于更新采样子图上的细胞、基因和峰值的联合嵌入。细胞分配概率矩阵和峰基因链接分配概率矩阵是学习后联合嵌入预测的。同时确定并迭代更新子图中的峰值基因关系和稀有细胞群以进行模型训练。此外,为了确保与主要细胞相关的特征不被削弱,正则化项被纳入训练过程中。随后将经过充分训练的模型应用于整个异质图,并结合转录因子(TF)数据库来构建细胞簇增强子基因调控网络(eGRN)。
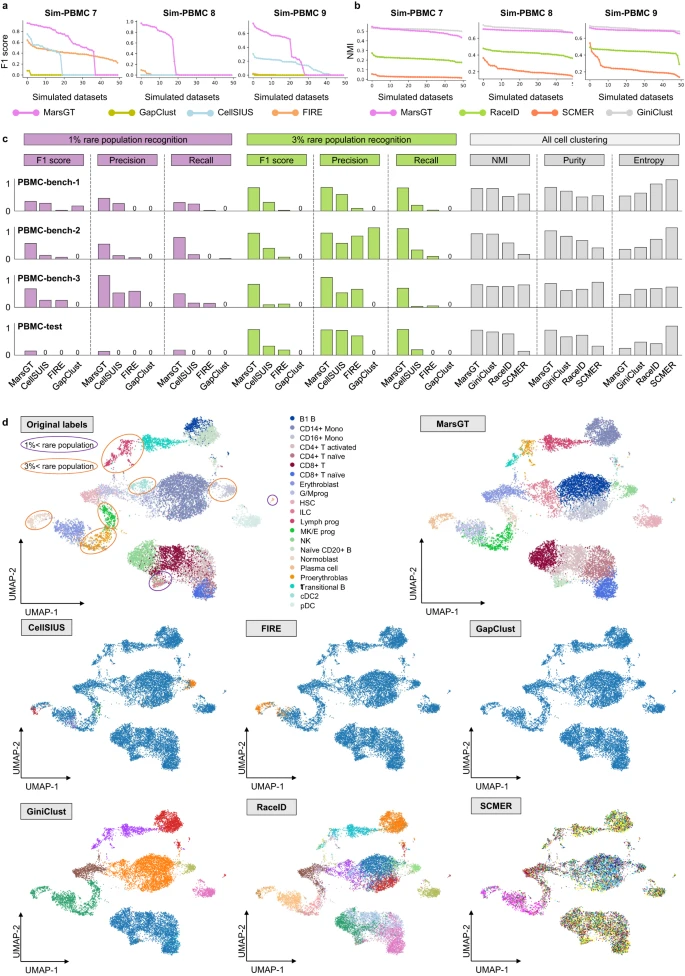
图示:MarsGT 在稀有细胞群鉴定方面的基准测试。(来源:论文)
MarsGT作为一种基于概率的子图采样方法,可以在异质图中突出显示罕见的细胞相关基因和峰值。研究人员进行了广泛的模拟 (n = 550),以彻底测试 MarsGT 在识别稀有细胞群方面的准确性和稳健性。
MarsGT 的性能经过500个模拟数据和四个人外周血单核细胞数据集的验证,在 F1 评分和归一化互信息 (NMI) 指标方面超越了现有方法。
为了进一步展示MarsGT的应用能力,研究人员将MarsGT应用于三个scMulti-omics案例研究:
(1)在小鼠视网膜数据中,它揭示了罕见双极细胞和穆勒神经胶质细胞亚群的独特亚群。
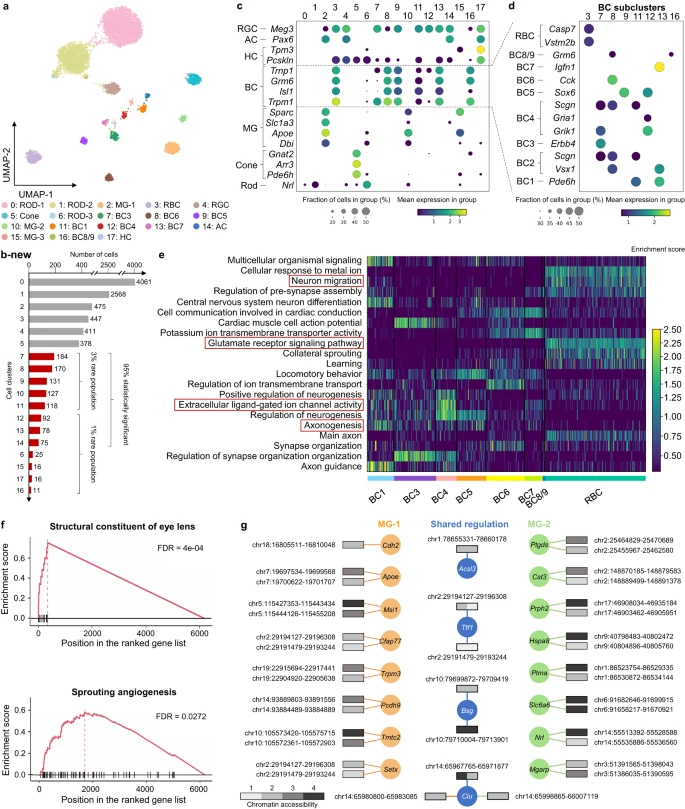
图示:MarsGT 有效地捕获了差异调节机制,并揭示了其他工具经常遗漏的具有生物学意义的稀有细胞群。(来源:论文)
(2)在人类淋巴结数据中,MarsGT 检测到可能充当淋巴瘤前体的中间 B 细胞群。
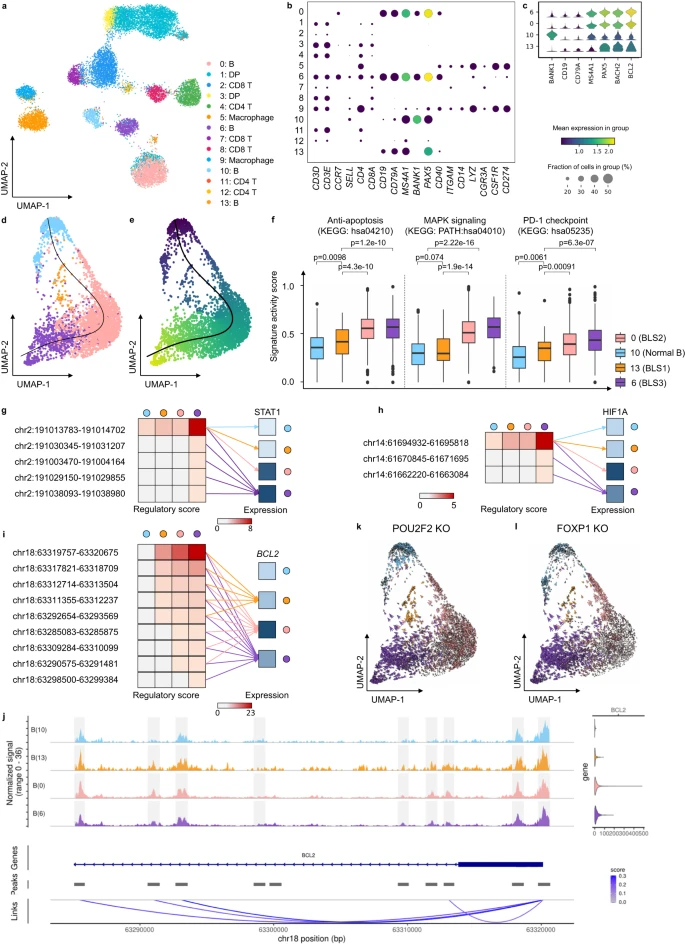
图示:MarsGT 在 B 淋巴瘤数据中识别出处于中间过渡状态的稀有细胞。(来源:论文)
(3)在人类黑色素瘤数据中,它识别出受高 IFN-I 反应影响的罕见 MAIT 样群体,并揭示了免疫治疗的机制。
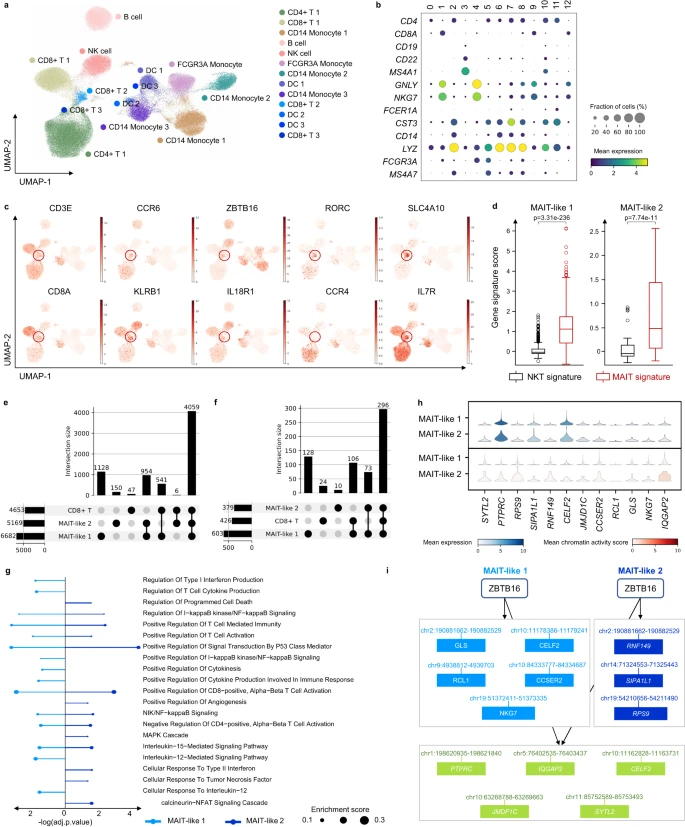
图示:MarsGT 在多样本黑色素瘤 scRNA-seq 和 scATAC-seq 中识别出类似 MAIT 的稀有细胞群和 eGRN。(来源:论文)
结果表明,MarsGT 可以区分独特的稀有细胞群(这是其他计算工具无法实现的壮举),并为早期临床检测和免疫阻断剂的开发提供策略。
总之,MarsGT 代表了鉴定稀有细胞群以及阐明微环境和免疫治疗机制的工具。它通过发现与疾病相关的稀有细胞群并揭示可为免疫治疗策略提供信息的内在调节机制,为精准医学开辟了一条充满希望的轨迹。
论文链接:https://www.nature.com/articles/s41467-023-44570-8


