视频生成
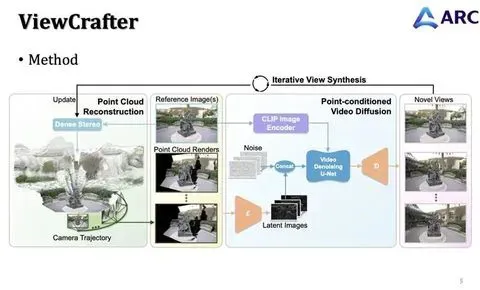
腾讯 ARC Lab 胡文博:“如何实现三维感知的视频世界模型,这非常值得探索”|GAIR 2025
作者丨齐铖湧编辑丨马晓宁世界模型的研究尚处于起步阶段,共识尚未形成,有关该领域的研究形成了无数支流,过去一年多,Sora为代表的视频生成模型,成为继大语言模型(LLM)后新的学术热点。 本质上讲,当下火爆的视频生成模型,是一种世界模型,其核心目的是生成一段逼真、连贯的视频。 要达到这样的目的,模型必须在一定程度上理解这个世界的运作方式(比如水往低处流、物体碰撞后的运动、人的合理动作等)。
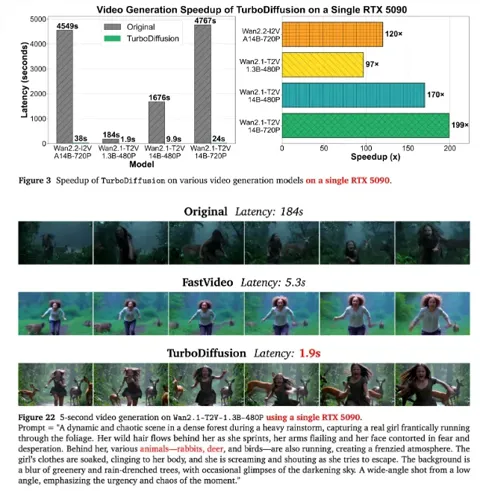
生数科技与清华大学联合推出 TurboDiffusion 视频生成加速框架
近日,生数科技与清华大学的 TSAIL 实验室共同发布了一个名为 TurboDiffusion 的视频生成加速框架,并将其开源。 这个新框架的发布引起了广泛关注,许多人期待它能为视频生成技术带来突破性进展。 根据官方介绍,TurboDiffusion 在几乎不影响生成质量的情况下,能够实现最高达200倍的视频生成推理加速。

告别抽卡!一手实测字节刚放出的视频模型Seedance 1.5 pro
编辑|杜伟、杨文结果在2025年底,视频生成再次热闹起来,多个新模型接连登场。 我们发现,在国内的头部厂商中,火山发动机的豆包系列视频生成模型已经很长时间没有大的版本更新了。 前代 Seedance 1.0 pro 的问世已经过去半年时间了,这也让我们对其下一代 Seedance 1.5 的关注度越来越高。

美国视频生成老炮儿,入局世界模型
鹭羽 发自 凹非寺. 量子位 | 公众号 QbitAI世界模型赛道,又有老面孔新鲜入局! 就在刚刚,Runway发布旗下首个通用世界模型GWM-1。

5天连更5次,可灵AI年末“狂飙式”升级
允中 发自 凹非寺. 量子位 | 公众号 QbitAI12月伊始,可灵AI接连放出大招。 全球首个统一的多模态视频及图片创作工具“可灵O1”、具备“音画同出”能力的可灵2.6模型、可灵数字人2.0功能…….

美团杀入视频生成模型赛道,LongCat-Video 136亿参数媲美顶尖模型,效率提升10倍
又是美团! 美团最近在AI领域的开源动作,真是令人刮目相看。 刚刚,美团LongCat团队发布了LongCat-Video的基础视频生成模型,它拥有136亿的参数量,能在数分钟内生成720p、30帧每秒的高质量视频,并且在文本转视频、图像转视频和长视频续写等多个任务上都表现出色。

「世界理解」维度看AI视频生成:Veo3和Sora2水平如何?新基准来了
近年来,Text-to-Video(T2V)模型取得显著进展——从静态帧质量到连贯的视频叙事,模型能力大幅提升,尤其是最近Sora2的爆火,让人们开始想象,T2V Model是否已经是一个真正的“世界模型”? 然而,传统基准主要考察图像质量与语义一致性,并不能系统衡量模型对事件因果、物理规律与常识的理解,而这些正是“世界模型”的核心能力。 为此,中山大学、香港理工大学、清华大学与OPPO Research Institute合作,在港理工Chair Professor张磊教授的指导下提出了一种新的评测框架——VideoVerse。

SIGGRAPH Asia 2025|电影级运镜一键克隆!港中文&快手可灵团队发布CamCloneMaster
本文第一作者罗亚文,香港中文大学 MMLab 博士一年级在读,研究方向为视频生成,导师为薛天帆教授。 个人主页:,你是否曾梦想复刻《盗梦空间》里颠覆物理的旋转镜头,或是重现《泰坦尼克号》船头经典的追踪运镜? 在 AI 视频生成中,这些依赖精确相机运动的创意,实现起来却往往异常困难。

清华联手英伟达打造扩散模型新蒸馏范式!视频生成提速50倍,四步出片不穿模
让视频生成提速50倍,不穿模还不糊字。 新蒸馏范式让Wan2.1 14B仅需4步就生成吃火锅视频:这是清华大学朱军教授团队, NVIDIA Deep Imagination研究组联合提出的一种全新的大规模扩散模型蒸馏范式——分数正则化连续时间一致性模型 (Score-Regularized Continuous-Time Consistency Model, rCM)。 该方法首次将连续时间一致性蒸馏成功扩展至百亿参数级别的文生图和文生视频模型,解决了现有方法在真实应用场景中的瓶颈。

SIGGRAPH Asia 2025|电影级运镜一键克隆!港中文&快手可灵团队发布CamCloneMaster
本文第一作者罗亚文,香港中文大学 MMLab 博士一年级在读,研究方向为视频生成,导师为薛天帆教授。 个人主页:,你是否曾梦想复刻《盗梦空间》里颠覆物理的旋转镜头,或是重现《泰坦尼克号》船头经典的追踪运镜? 在 AI 视频生成中,这些依赖精确相机运动的创意,实现起来却往往异常困难。

41倍实时交互:LongLive如何突破长视频生成的效率与质量困局
大家好,我是肆〇柒。 最近视频生成挺火,刚好看到一个研究——LongLive实时交互式长视频生成框架。 这项由NVIDIA、MIT、香港科技大学(广州)、香港大学和清华大学研究团队联合研发的创新技术,成功解决了困扰行业已久的"提示切换断层"难题,让创作者能够在生成过程中实时调整叙事方向,实现真正的"所想即所见"创作体验。

训练成本暴降99%,35秒出1分钟高清视频!英伟达MIT等引爆视频AI革命
27帧每秒的实时视频生成、35秒合成1分钟高清视频——这不是遥远的未来,而是刚刚由英伟达联合MIT与港大团队带来的现实。 全新一代视频扩散模型SANA-Video横空出世,凭借革命性的线性DiT架构与恒定显存KV缓存机制,不仅速度超越所有同类模型,更以高达720p的分辨率与分钟级时长生成,重新定义了AI视频生成的效率极限。 SANA-Video不仅在速度和性能上表现出色,生成的图像质量也非常高。

紧急应对Sora 2,谷歌推出Veo 3.1版本:一手实测
刚刚,谷歌Veo 3进行了更新,最新版本Veo 3.1,可以在这里体验,fast模式每次生成耗费20积分,相比sora 2 看起来贵很多,sora 2到目前为止都是无限制生成,完全免费我第一时间就做了一个Veo 3.1和sora 2的初步对比测试,测试下来,Veo 3.1审美以及提示词遵循能力还是不如sora 2,不过好处是,Veo 3.1支持上传人像进行创作,sora 2 目前图生视频不支持人像废话不多说,看玩法:上手测试1.图生视频:nanobanana Veo 3.1先用nanobanana生成一个超高清小姐姐提示词:复制进入:,提示词:展示穿搭。

实测“清华特奖版Sora”:一图一prompt直接生成视频,堪称嘴强王者
那边OpenAI的Sora2还没全面开放,这边国内团队已经上线了自己的“特色打法”。 清华特奖选手创办的Sand.ai,上线了音画同步视频模型GAGA-1。 你可以把它理解为:一个专门练“嘴功”和“表演感”的视频生成模型:怎么样,奥特曼看了这视频都得说一句:好家伙!

Sora 2深夜来袭,OpenAI直接推出App,视频ChatGPT时刻到了
没想到吧,在别家节前卷大模型时,OpenAI 悄悄发布了 Sora2。 而且,这次是直接产品化,推出了 App,甚至还有配套的视频推送算法,声称可以防成瘾。 这是要做自己的 TikTok?

生数科技获数亿元融资,视频生成引领AI商业化新潮流
近日,多模态 AI 领域的先锋企业生数科技宣布成功完成数亿元人民币的 A 轮融资。 这轮融资由博华资本领投,老股东百度战投、北京市人工智能产业投资基金等多个投资方继续跟进,显示出市场对生数科技的高度认可。 公司计划利用这笔资金进一步推动模型研发和技术创新,探索多模态大模型的潜力,进而加速产品拓展和用户服务。

刚刚,李飞飞空间智能新成果震撼问世!3D世界生成进入「无限探索」时代
就在今天,斯坦福大学教授李飞飞的创业公司 World Labs 发布了新成果 —— 限量开放的测试预览版空间智能模型 Marble。 「只需一张图片,就能生成持久存在的 3D 世界,比以往更宏大、更震撼! 」我们先看下面一段视频 demo: 李飞飞对此表示,「这是一个使用我们的 3D 世界生成模型创建的极其庞大的世界,它令我惊叹不已!

英伟达新GPU,超长上下文/视频生成专用
老黄对token密集型任务下手了。 刚刚,在AI Infra Summit上,英伟达宣布推出专为处理百万token级别的代码生成和生成式视频应用的全新GPU——NVIDIA Rubin CPX GPU。 老黄表示:Rubin CPX是首款为超大上下文AI量身定制的CUDA GPU,可以让模型“一口气”推理数百万token。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉