让视频生成提速50倍,不穿模还不糊字。
新蒸馏范式让Wan2.1 14B仅需4步就生成吃火锅视频:

这是清华大学朱军教授团队, NVIDIA Deep Imagination研究组联合提出的一种全新的大规模扩散模型蒸馏范式——
分数正则化连续时间一致性模型 (Score-Regularized Continuous-Time Consistency Model, rCM)。

该方法首次将连续时间一致性蒸馏成功扩展至百亿参数级别的文生图和文生视频模型,解决了现有方法在真实应用场景中的瓶颈。
通过引入前向-反向散度联合优化框架,rCM在大幅提升推理速度(高达50倍)的同时,兼顾了生成结果的高质量与高多样性。

下面具体来看。
连续时间一致性蒸馏:从学术“刷点”到应用落地
近年来,以扩散模型为代表的生成模型取得了巨大成功,但其迭代采样的慢推理速度始终是阻碍其广泛应用的核心障碍。
为解决此问题,模型蒸馏技术应运而生,其中,OpenAI近期提出的连续时间一致性模型 (sCM),因其理论的优雅性和在学术数据集上的良好表现而备受关注。
今年5月份,何恺明加持的MeanFlow,作为sCM的热门变体,在学术界掀起了研究热潮。
然而,尽管相关研究层出不穷,但它们大多局限于在ImageNet等学术数据集上进行“小打小闹”式的验证,距离真实世界中动辄数十亿、上百亿参数的大规模文生图、文生视频应用场景相去甚远。
究其原因,sCM/MeanFlow依赖的雅可比-向量积 (Jacobian-Vector Product, JVP) 计算在现有深度学习框架下存在巨大的工程挑战,尤其是在与FlashAttention-2、序列并行等大模型训练“标配”技术结合时,这使得sCM迟迟未能在大模型时代兑现其潜力。
同时,学术界关心的FID等指标,往往不能很好的衡量真实应用场景下的细节生成,如文生图时对细小文字的渲染。因此,sCM/MeanFlow在大规模应用中的效果亟待验证。
rCM:前向-反向散度联合优化,实现质量与多样性“双赢”

为了打破这一僵局,团队首先从底层“硬骨头”啃起。
通过自研FlashAttention-2 JVP CUDA算子并兼容序列并行等分布式训练策略,首次成功将连续时间一致性蒸馏应用到Cosmos和Wan2.1等业界领先的大模型上。
然而,初步的实验暴露出单纯sCM的深层问题:模型在生成精细纹理(如文字)和保证视频的时序稳定性方面存在明显缺陷。
理论分析指出,这是由于sCM所依赖的前向散度(Forward Divergence)优化目标具有“模式覆盖(mode-covering)”的倾向,会因误差累积导致生成样本质量下降。
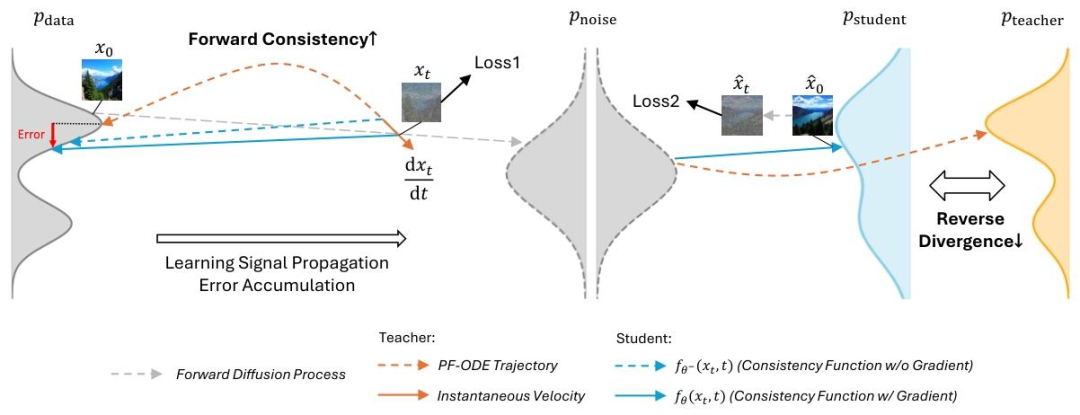
受此启发,团队创新性地提出了rCM。
rCM 在sCM的基础上,引入了基于分数蒸馏的反向散度(Reverse Divergence)作为正则项,构建了一个前向-反向联合蒸馏框架。
- 前向散度(sCM)训练数据为真实数据或教师合成的高质量数据,保证模型能覆盖真实数据的全部模式,从而确保生成结果的高多样性。
- 反向散度(Score Distillation)学生模型只在自己生成的样本上被监督,强制模型聚焦于高密度(高质量)数据区域,具有“模式寻求(mode-seeking)”的特性,从而显著提升生成结果的高质量。
这种联合优化,使得rCM能够取长补短,在保持sCM高多样性优势的同时,有效修复其质量短板,最终实现“鱼与熊掌兼得”。
实验:2-4步媲美教师模型,多样性超越SOTA
rCM在多个大规模文生图和文生视频任务中展现了卓越的性能,将教师模型上百步的采样过程压缩至惊人的1-4步,实现了15-50倍的推理加速。
- 性能媲美甚至超越教师模型在T2I任务的GenEval评测和T2V任务的VBench评测中,4步采样的rCM模型在多个指标上追平甚至超越了需要数百步采样的教师模型。
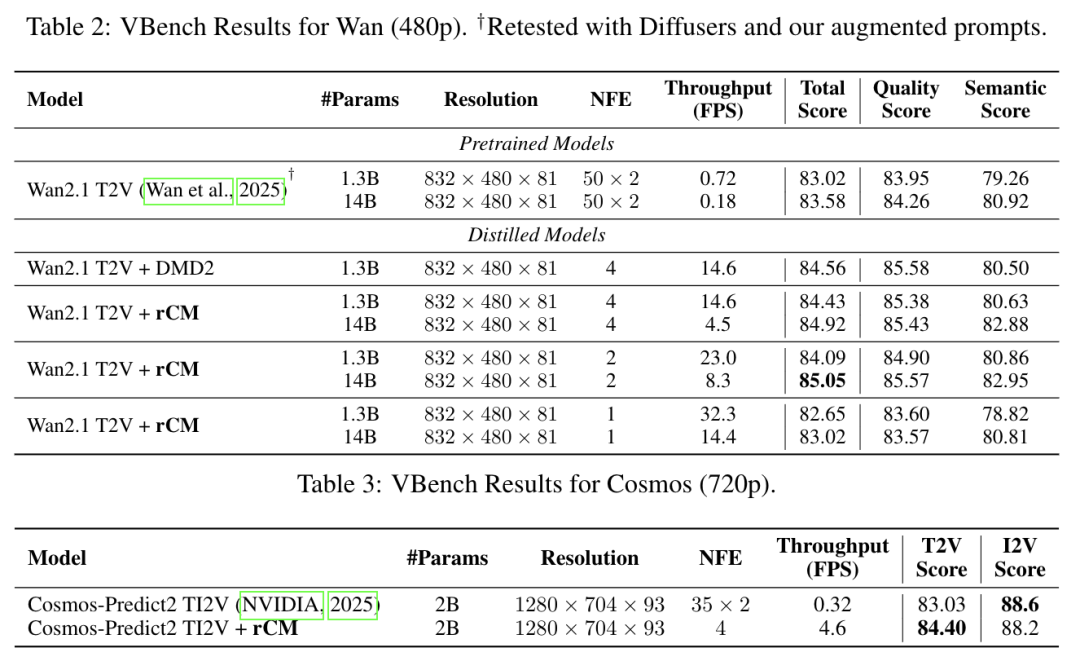
同时,rCM在细节文字渲染等方面表现良好。

- 多样性显著优势相较于先前的SOTA蒸馏方法DMD2,rCM生成的视频内容(如怪兽的姿态、烛光的位置)展现出明显更高的多样性,有效避免了“模式坍缩”问题。这证明了联合利用前向-反向散度的巨大潜力。
 △Wan2.1 1.3B使用不同算法蒸馏后的4步生成结果
△Wan2.1 1.3B使用不同算法蒸馏后的4步生成结果- 极致的少步数生成即便在1-2步的极限采样设置下,rCM依然能产出高质量、细节丰富的图像和视频。具体地,对于简单的图像提示词只需1步生成,复杂的图像和视频则需2-4步。

rCM不仅提供了一个无需多阶段训练与复杂超参搜索的高效蒸馏方案,还揭示了结合前向与反向散度是提升生成模型性能的统一范式。
rCM未来将被更广泛地应用在NVIDIA的Cosmos系列世界模型中。
感兴趣的朋友可到原文查看更多细节~
论文地址:https://arxiv.org/abs/2510.08431
代码地址:https://github.com/NVlabs/rcm


