
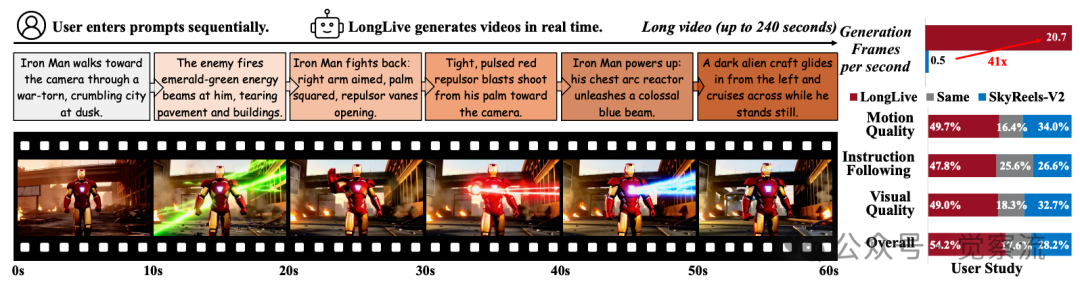
大家好,我是肆〇柒。最近视频生成挺火,刚好看到一个研究——LongLive实时交互式长视频生成框架。这项由NVIDIA、MIT、香港科技大学(广州)、香港大学和清华大学研究团队联合研发的创新技术,成功解决了困扰行业已久的"提示切换断层"难题,让创作者能够在生成过程中实时调整叙事方向,实现真正的"所想即所见"创作体验。在本文中,我们将探索LongLive如何以41倍于现有技术的效率,同时保持甚至提升视频质量,为长视频生成领域带来创新思考。
LongLive工作流程
想象这样一个场景:一位创作者正在实时生成一段60秒的视频。开始时,他描述"使徒保罗走在尘土飞扬的罗马时代小路上";10秒后,他添加"保罗走过路边低矮灌木丛,步伐稳定";20秒时,他决定引入新角色:"一个衣衫褴褛的灰衣男孩从灌木丛中探出头"。理想情况下,保罗的服装、表情和行走姿态应当保持连贯,新角色的出现应当自然融入场景,而不是突兀地"跳"出来。然而,这正是交互式长视频生成面临的核心挑战——如何在提示切换时保持视觉一致性与语义连贯性。
当前视频生成技术正从静态短片段向动态长视频演进,这一转变对创意、教育和影视应用至关重要。长视频不仅支持连贯叙事和丰富场景开发,还能展现比短片段更复杂的时序动态。然而,静态提示生成限制了生成过程中的适应性,用户难以一次性构思高度详细的长格式提示。交互式长视频生成技术应运而生,允许用户在运行时流式输入提示,实时引导叙事发展、调整视觉风格或引入新元素,使长视频生成更具可控性。
在这一领域,LongLive框架实现了突破性进展。数据显示,LongLive在单张NVIDIA H100 GPU上可持续保持20.7 FPS的推理速度,比SkyReels-V2快41倍,这意味着生成1秒视频只需约0.05秒,用户输入提示后几乎可以立即看到视频生成;而SkyReels-V2的0.49 FPS则意味着生成1秒视频需要约2秒,60秒视频需要约120秒等待时间。在VBench基准测试中,LongLive的总分达到84.87,超越了现有高质量视频生成模型。本文将系统对比LongLive与现有技术,揭示其在交互式长视频生成领域的技术演进与工程智慧。需要说明的是,LongLive并非首个交互式视频生成系统,但在效率与质量的平衡上取得了重大突破。
长视频生成的技术路线全景
当前长视频生成技术主要沿着三条技术路线发展:扩散模型路线、扩散-强制路线和因果自回归路线,每条路线各有优势与局限。
LongLive框架
扩散模型路线以Wan2.1、Phenaki、NUWA-XL、LaVie、SEINE和LCT为代表。这类方法虽然能生成高质量短片段,但依赖双向注意力机制,无法利用KV缓存技术,导致推理效率低下。例如,SkyReels-V2需要约50分钟在H100 GPU上生成60秒视频。尽管通过离散化压缩、级联管道等技术延长了生成长度,但双向注意力机制的根本限制使其实时交互难以实现。想象一下,如果创作者想在生成过程中调整使徒保罗场景中的细节,他们必须等待数分钟才能看到效果,这完全破坏了创作流程的连贯性。
扩散-强制(Diffusion-Forcing)路线结合了扩散模型的质量与自回归模型的效率,代表工作包括Diffusion-forcing、SkyReels-V2、Lumos-1、FramePack和StreamingT2V。这类方法在训练时结合了扩散和AR预测,但推理时仍无法高效利用KV缓存。例如,SkyReels-V2的推理速度仅为0.49 FPS,无法满足实时交互需求。此外,这些方法通常采用"train-short-test-long"策略,导致长视频质量逐渐下降。在赌场德州扑克场景中,当视频超过30秒后,角色面部细节和筹码堆叠的连贯性明显下降,影响了整体观感。
因果自回归(Causal AR)路线支持KV缓存,实现高效推理,代表工作包括CausVid、FAR、MAGI-1、Self-forcing等。这类模型虽然推理速度快,但长视频训练面临质量下降挑战。在交互式生成方面,MAGI-1虽然支持提示切换,但需要手动调整KV-cache窗口,操作复杂。在使徒保罗场景中,当需要添加灰衣男孩时,创作者必须精确计算在哪个帧切换KV-cache窗口,否则会导致视觉断层或提示不遵循。

KV缓存策略对比
交互式视频生成的核心难题在于提示切换时的视觉断层与语义滞后问题,上图直观展示了三种不同策略的效果:(a)无KV缓存时,新提示生效,但过渡突兀且视觉不连贯——在使徒保罗场景中,当切换到"灰衣男孩从灌木丛中探出头"时,保罗可能突然改变位置或表情;(b)保留KV缓存时,视觉连续但新提示不被遵循(延迟或忽略)——在赌场德州扑克场景中,即使提示要求"男子翻出获胜牌型",角色可能继续面向原方向,忽略新指令;(c)KV重缓存实现了平滑、视觉一致的过渡,同时完全符合新提示——这是LongLive的突破性解决方案。
这些技术路线的共同挑战在于:训练-推理不一致性导致长视频质量下降,以及提示切换时的视觉断层与语义滞后问题。LongLive的创新正是针对这些根本挑战,通过系统性设计实现训练-推理一致性与实时交互能力。
LongLive的核心技术突破
LongLive采用帧级自回归(AR)框架,为解决交互式长视频生成问题提供了系统性方案。与chunk-wise AR模型相比,帧级AR更适合细粒度交互,能更精确地控制生成过程。更重要的是,因果注意力机制使LongLive能够继承KV缓存机制,实现高效推理。在效率方面,LongLive达到20.7 FPS,远超扩散-强制模型的0.49 FPS,这意味着创作者可以在输入提示后立即看到视频变化,真正实现"所想即所见"的创作体验。
流式长微调流程
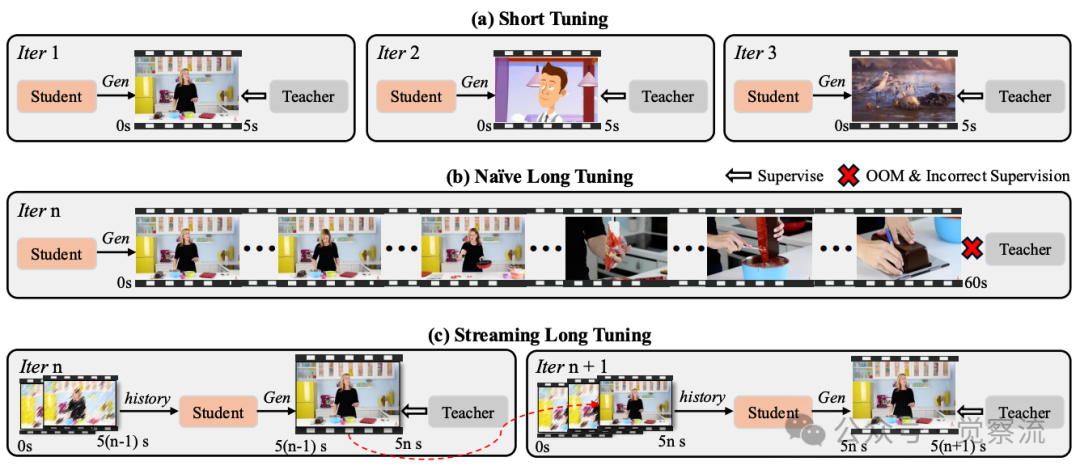
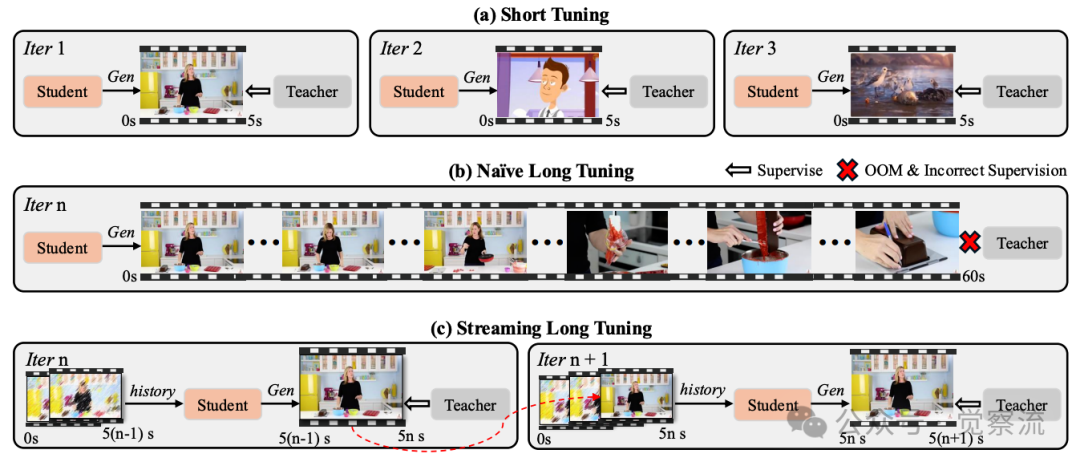
上图清晰展示了三种方法的本质区别:(a) Short Tuning仅监督5秒片段,导致长视频质量下降;(b) Naive Long Tuning直接扩展序列导致OOM和错误监督;(c) Streaming Long Tuning通过重用历史KV缓存生成下一段5秒视频。在Naive Long Tuning中,教师模型无法可靠监督整个长序列,因为教师模型本身仅针对短片段训练;而在Streaming Long Tuning中,教师模型仅对当前短片段提供可靠监督(这是它擅长的),而各片段的监督组合为完整序列提供全局指导。

KV缓存策略对比
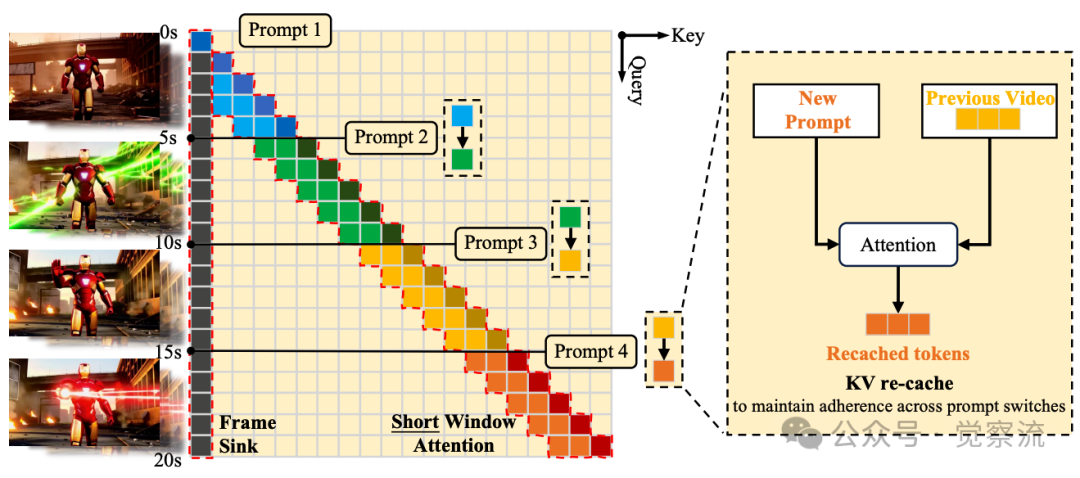
KV-recache是LongLive解决提示切换难题的创新方案。研究发现,提示切换困难的原因在于:在DiT架构中,交叉注意力层和自注意力层交替出现。生成过程中,大量来自先前提示的信息通过交叉注意力层反复注入,并通过自注意力向前传播,使提示信号写入运行中的KV缓存。当提示切换时,模型仍携带旧提示的残余语义。
LongLive引入KV recache技术,在提示切换边界重新计算KV缓存。具体而言,在第一个切换后帧,LongLive将已生成的视频前缀编码为视觉上下文,并与新提示配对重建缓存;后续步骤则使用此刷新缓存正常进行。这样,缓存保留了视频的视觉状态,但提示语义现在清晰对应于活动提示,从而在不破坏视觉连续性的情况下实现语义对齐。
在使徒保罗行走场景中,当从"保罗走过路边低矮灌木丛"切换到"灰衣男孩从灌木丛中探出头"时,KV recache确保了保罗的服装、表情和行走姿态的连贯性,同时准确引入了新角色。在赌场德州扑克场景中,当从"男子紧握底牌"切换到"他将牌翻到桌面上"时,KV recache保持了角色面部表情和手部动作的连贯性,同时准确呈现了新动作。

KV重缓存对比
KV重缓存的实际效果在多个场景中得到验证。在"0s-5s: 年轻美丽的女孩唱歌..."切换到"5s-10s: 一个女孩伸手整理头发..."时,KV重缓存确保了人物身份和场景的连贯性,同时准确反映了新动作;而在"0s-5s: 一个冒着热气的汉堡..."切换到"5s-10s: 新鲜胡椒撒在热汉堡肉饼上..."时,KV重缓存保持了汉堡的视觉一致性,同时准确呈现了新添加的胡椒元素。相比之下,无KV缓存导致视觉不连贯,而保留KV缓存则使模型无法及时响应新提示。
值得注意的是,KV recache仅在训练样本中每个长序列的一次提示切换中调用,因此额外成本最小;对于10秒包含一次切换的视频,recaching仅引入约6%的额外时间成本。虽然训练中仅包含一次提示切换,但该机制在推理时能有效支持多次切换:给定n+1个提示和n个切换点,生成器因果地展开,在每个切换边界应用KV recaching,继续生成与活动提示语义对齐的帧,同时保持平滑过渡。
流式长微调流程
为确保训练-推理一致性,LongLive提出Streaming Long Tuning策略。在第一次迭代中,生成器从零开始采样一个短视频片段(如5秒),并对该片段应用DMD(Distribution Matching Distillation)。在后续迭代中,生成器基于前一次迭代存储的历史KV缓存扩展短片段,生成下一个条件化的5秒片段,然后仅对该新生成片段应用DMD。这一过程重复进行,直到视频达到预设的最大长度,然后获取新批次并重新开始。
在使徒保罗场景中,Streaming Long Tuning确保了从0-10秒到50-60秒的整个60秒视频都保持高质量。在赌场德州扑克场景中,该技术避免了角色面部细节和筹码堆叠的退化,使视频在60秒内保持连贯性和细节质量。
在每一步中,已生成帧被分离,充当恒定因果上下文,梯度仅针对当前生成片段计算,从而将内存使用限制在片段持续时间内,避免OOM问题。这种设计使模型在训练时就接触扩展的、自我生成的、逐渐退化的帧,减轻错误累积以提高保真度和一致性。
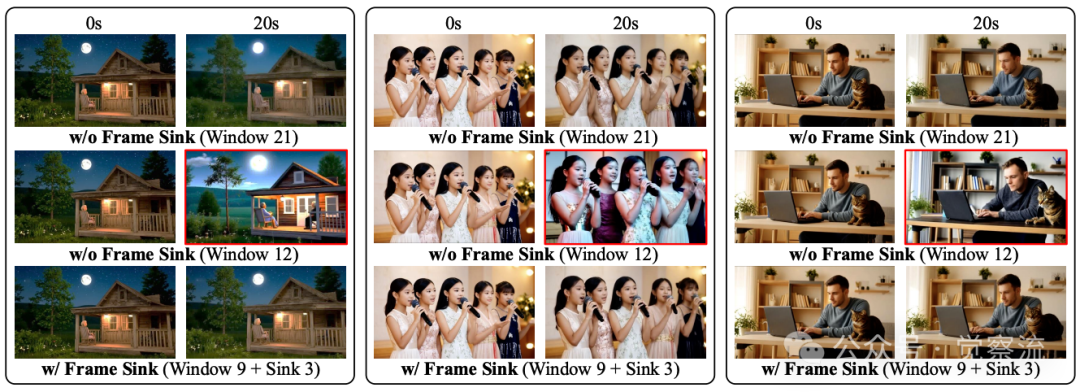
20秒视频生成对比
短窗口注意力与帧级注意力sink的组合是LongLive实现高效推理的关键。在长视频生成中,密集因果注意力的成本随序列长度呈二次方增长,使朴素推理在长视频上不可行。受视频生成中时间局部性的启发——附近帧对预测下一帧贡献更大,LongLive在推理和流式调优期间采用局部窗口注意力。将注意力限制在固定时间窗口内减少了计算和内存。注意力复杂度与窗口大小成正比,而不是增长的序列长度,KV缓存每层所需内存也与窗口而非总视频成比例。
然而,窗口大小引入了质量-效率权衡。实验表明,较大窗口保留更多时序上下文,产生更强的长程一致性,但会增加延迟和内存。缩小窗口提高效率,但会以一致性为代价,因为远处但关键的线索从感受野中消失。为解决此问题,LongLive引入帧级注意力sink(frame sink),作为持久全局锚点,显著提高长程时序一致性,从而缓解使用短窗口注意力时的质量-效率权衡。
具体而言,LongLive将视频的第一个帧块固定为全局sink tokens;这些tokens永久保留在KV缓存中,并连接到每个注意力块的键和值中,即使使用局部窗口注意力,也能使它们全局可访问。KV缓存的其余部分使用短滚动窗口并正常驱逐。在训练中,保持(i)先前上下文最后W帧的KV缓存(无梯度)和(ii)当前监督片段T帧的完整KV缓存(有梯度)。同时维护S个sink tokens(前两帧),这些tokens永不驱逐,并连接到每层KV中,使其全局可访问。因此,每步驻留KV大小为O(W+T+S),不随总视频长度增长,防止超长rollout中的OOM问题。
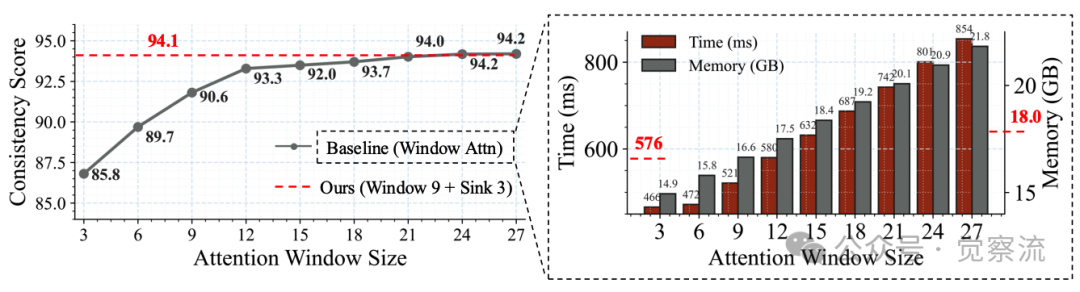
短窗口大小与帧级sink消融实验
上图的实验数据清晰展示了短窗口与帧级sink的协同效应。随着注意力窗口从3帧增至27帧,一致性逐渐提高并在24帧窗口处趋于饱和。9局部帧+3sink帧的配置(有效窗口大小12)实现了接近21帧窗口的一致性,同时保留了短窗口的速度和内存优势。实验证明,注意力sink tokens单独并不能防止视频模型中的长rollout崩溃,但一旦通过流式长微调解决长rollout崩溃,注意力sink变得有效。
在使徒保罗场景中,帧级注意力sink确保了从开始到结束的60秒视频中,保罗的服装颜色、面部特征和行走姿态保持一致;在赌场德州扑克场景中,它保证了角色面部表情和筹码堆叠的连贯性,即使在60秒的长视频中也不会出现质量下降。

LoRA预算与性能对比
LoRA高效微调技术帮助LongLive突破长上下文训练的计算瓶颈。LongLive采用LoRA调优,发现有效长程生成需要相对较高的适配器秩;在设置中,结果适配器需要256秩,使模型约27%的参数可训练。如上表显示,随着LoRA预算的增加,质量提高直至饱和点:32秩(44M参数)时总分为81.08;64秩(87M参数)时提升至82.68;128秩(175M参数)时为82.98;256秩(350M参数)时达到最佳83.12;512秩(700M参数)时略有下降至83.04;而全模型微调(1.3B参数)得分为83.52。这表明256秩的LoRA配置在训练参数远少于全微调的情况下达到了接近最佳效果。
LoRA大幅减少了训练足迹,将参数/优化器状态减少至全微调的约27%(即节省73%)。这一设计使LongLive能在仅32 GPU天内完成1.3B参数模型的微调,实现了高效的长视频生成能力。
INT8量化技术进一步优化了LongLive的部署效率。通过后训练量化(PTQ),LongLive将模型大小从2.7GB减少到1.4GB(减少1.9倍),吞吐量从12.6 FPS提升至16.4 FPS(提高1.3倍),同时VBench总分仅从84.87略微降至84.31,语义分数从86.97降至86.20,扩散分数从76.47升至76.74,质量损失极小。值得注意的是,INT8量化不仅减少了模型大小,还提高了吞吐量,使得LongLive在资源受限的设备上也能高效运行,为更多创作者提供了使用这项技术的可能性。

INT8量化结果
全面性能对比
在短视频生成能力方面,LongLive在VBench基准测试中表现出色。
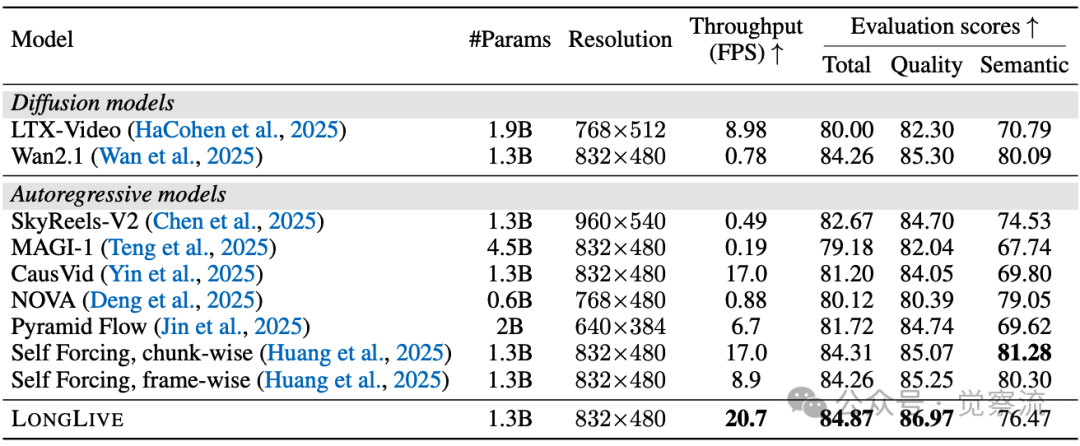
与相关基线的对比
数据显示,LongLive的总分达到84.87,语义分数为86.97,扩散分数为76.47,与最强基线模型相匹配,证明了其出色的短片段质量和稳定性。同时,得益于短窗口注意力设计,LongLive在所有方法中速度最快,达到20.7 FPS,实现了实时推理。
在长视频生成能力方面,LongLive在VBench-Long测试中取得最佳成绩。下表数据显示,LongLive的总分为83.52,质量分数为85.44,语义分数为75.82,显著优于SkyReels-V2的75.29和Self-Forcing的81.59。LongLive能够维持高质量直到视频结束,而其他方法在长视频中质量逐渐下降。
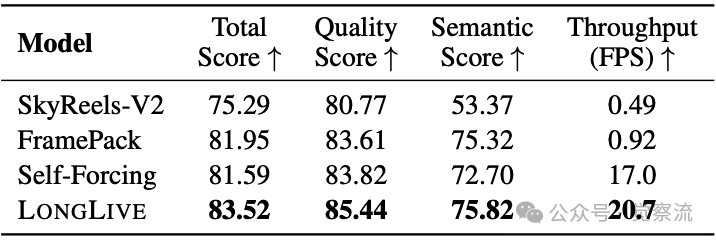
单提示30秒长视频评估
在交互式长视频生成能力方面,LongLive在定制测试集上表现突出。下表数据显示,LongLive的质量分数为84.38,CLIP分数在各个10秒片段上保持稳定(28.85-24.32),而SkyReels-V2和Self-Forcing的CLIP分数波动更大且更低。这表明LongLive在提示切换时能够保持更高的语义一致性。

交互式长视频评估
60秒交互式视频案例进一步验证了LongLive的能力。在使徒保罗行走场景中,六个连续提示无缝衔接。KV recache确保了保罗的服装、表情和行走姿态的连贯性,同时准确引入了新角色。特别是"20-30s: 一个衣衫褴褛的灰衣男孩从灌布丛中探出头"与前序场景的过渡自然流畅,既符合新提示要求,又与保罗先前的行走动作保持连贯。在传统方法中,这种角色添加往往会导致视觉断层或角色特征不一致。

交互式60秒视频示例
在赌场德州扑克场景中,六个连续提示也实现了高质量的连贯生成。例如,"30-40s: 他坐直并有条不紊地堆叠筹码,动作整齐、有条理"与前序"20-30s: 他翻出获胜牌型;附近一名顾客鼓掌,掌声响起"场景无缝衔接,角色表情、动作和场景细节保持高度一致性,展示了KV recache如何在保持视觉连续性的同时,精确遵循新提示的语义要求。
LongLive不仅支持交互式长视频生成,还能生成高质量的单提示超长视频。在240秒序列上的实验表明,LongLive能够平滑一致地生成这种超长视频,质量几乎没有下降。上图展示了三个60秒单提示视频示例,包括蝙蝠侠与小丑打斗场景、雪中跳舞的熊猫以及森林暴雨中的女孩奔跑场景,这些视频在长时间跨度内保持了高度的视觉一致性和细节质量。
KV重缓存消融研究
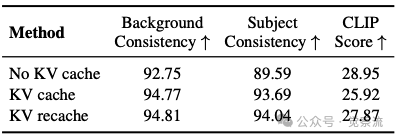
消融实验分析了各组件的贡献度。KV recache在背景一致性和主体一致性方面均优于其他策略:No KV cache得分为92.75和89.59;KV cache得分为94.77和93.69;KV recache得分为94.81和94.04。这表明KV recache在保持视觉连续性的同时,也改善了对新提示的遵循。在使徒保罗场景中,KV recache确保了背景中的罗马时代小路和滚动 hills 在提示切换后保持一致;在赌场场景中,它维持了桌面布局和周围环境的连贯性。
短窗口与帧级sink的组合(9帧窗口+3帧sink)在一致性上接近21帧窗口,但效率显著提升,证明了其在质量-效率权衡中的优势。这种组合使LongLive在保持高质量的同时,将端到端计算时间减少28%,峰值内存降低17%,为实时交互提供了坚实基础。
效率对比方面,LongLive的优势尤为显著。LongLive的推理速度为20.7 FPS,比SkyReels-V2的0.49 FPS快41倍,甚至略快于Self-Forcing。这一巨大差距源于技术路线的根本区别:扩散模型依赖双向注意力,无法利用KV缓存技术,导致冗余计算和长视频的不可接受延迟;而LongLive的因果注意力机制支持KV缓存,结合短窗口注意力设计,实现高效推理。INT8量化进一步将模型大小减少1.9倍,吞吐量提高1.3倍。训练效率方面,LongLive仅需32 GPU天即可微调1.3B参数模型,实现高质量分钟级视频生成。
技术局限与未来方向
LongLive作为基于预训练模型的高效微调方案,其最终性能受限于基础模型的容量和质量。LongLive采用自监督微调策略,不引入额外真实视频数据,这提高了效率和可扩展性,但也限制了其纠正基础模型系统性错误或偏差的能力。因此,任何短片段(如每10秒片段)的质量不太可能持续超越基础模型,即使长时域一致性或指令遵循有所改善。这意味着LongLive的收益主要在于适应和稳定,而非绝对质量上限。
用户研究评估了四个维度:Overall Quality(整体质量)、Motion Quality(运动质量)、Instruction Following(指令遵循)和Visual Quality(视觉质量)。每个问题中,参与者被展示一对视频和相应提示,并要求选择Model A、Model B或Same(无明显差异)。研究共收集30位参与者的26份有效回复,总计1,248个判断。参与者被指示仔细观看两个视频,必要时重播,然后做出选择。结果显示,LongLive在所有四个维度上均显著优于对比方法,特别是在指令遵循方面表现突出。
在使徒保罗场景中,LongLive在"Instruction Following"维度的优势确保了每个新提示都能被准确执行,同时保持视觉连贯性;在赌场德州扑克场景中,它在"Motion Quality"维度的领先使角色动作更加流畅自然,没有抖动或不连贯现象。
未来研究可能探索与监督学习方法的结合,利用真实长视频数据提升质量,避免质量边界限制。人机协作生成,结合人类反馈优化关键场景,也是潜在方向。LongLive与其他技术路线的融合也值得探索,如结合扩散模型的高质量与AR的高效性,或整合音频、动作捕捉等多模态输入源。
针对特定应用(如教育、电影制作)的领域适应,以及超长视频生成(240秒以上)的质量保持策略,都是未来技术演进的可能方向。多提示并行处理和低资源设备部署的进一步优化也将拓展LongLive的应用场景。例如,在教育场景中,教师可以实时生成教学视频,根据学生反应即时调整内容;在电影制作中,导演可以快速预览不同叙事走向的效果,而不必等待漫长的渲染过程。
总结
LongLive代表了交互式长视频生成技术发展的重要标志,通过解决效率与质量的平衡问题,实现了真正的实时交互式长视频生成。其核心价值在于训练-推理一致性对长视频生成的重要性,以及工程智慧如何将理论创新转化为实用系统。
LongLive的成功不仅在于技术组件的创新组合,更在于对训练-推理一致性的深刻理解。通过将recache操作集成到训练流程、采用流式长微调策略、以及在训练和推理中使用相同的短窗口注意力,LongLive消除了长期困扰长视频生成领域的训练-推理不匹配问题。这一思路不仅适用于视频生成,也为其他长序列生成任务提供了重要启示:只有当训练条件与推理条件高度一致时,模型才能在长序列上保持高质量输出。
在使徒保罗和赌场德州扑克这两个案例中,LongLive展示了如何将技术突破转化为实际创作体验:创作者可以实时调整叙事方向,添加新角色或改变场景,而不会破坏视觉连贯性或忽略新提示。这种"所想即所见"的创作体验,正是LongLive技术价值的集中体现。
LongLive展示了长视频训练不仅是长视频生成性能的关键,也是高效推理策略(如窗口注意力与帧级注意力sink)的前提条件。对开发者而言,选择技术路线应考虑应用场景:若需要高质量短片段,扩散模型可能更合适;若需要实时交互式长视频,因果自回归框架更具优势。
随着技术的不断演进,视频生成将从工具逐渐转变为创意伙伴,帮助用户实时构建动态叙事。LongLive的技术突破不仅解决了当前挑战,也为未来研究指明了方向,展示了工程创新如何推动AI生成内容向更实用、更可控的方向发展。在创意、教育和影视应用中,LongLive使创作者能够以前所未有的方式探索叙事可能性,将想象力直接转化为连贯、高质量的长视频内容。


