
编辑 | X
近年来,自然语言处理(NLP)模型,特别是 Transformer 模型,已应用于像 SMILES 这样的分子结构的文字表示。然而,关于这些模型如何理解化学结构的研究很少。
为了解决这个黑匣子,东京大学的研究人员使用代表性的 NLP 模型 Transformer 研究了 SMILES 的学习进度与化学结构之间的关系。研究表明,虽然 Transformer 可以快速学习分子的部分结构,但它需要扩展训练才能理解整体结构。
一致的是,从训练开始到结束,使用不同学习步骤的模型生成的描述符进行分子特性预测的准确性是相似的。此外,发现 Transformer 需要特别长时间的训练来学习手性,并且有时会因对映体的误解而停滞不前,性能低下。这些发现有望加深对化学领域 NLP 模型的理解。
该研究以「Difficulty in chirality recognition for Transformer architectures learning chemical structures from string representations」为题,于 2024 年 2 月 16 日发布在《Nature Communications》上。

论文链接:https://www.nature.com/articles/s41467-024-45102-8
机器学习的最新进展影响了化学领域的各种研究,例如分子性质预测、能量计算和结构生成。
要在化学中利用机器学习方法,我们首先需要让计算机识别化学结构。最流行的方法之一是使用化学语言模型,这是一种自然语言处理 (NLP) 模型,其中包含表示化学结构的字符串,例如 SMILES。
很少有人研究化学语言模型如何理解极其多样化的分子结构,以及如何将化学结构和描述符联系起来。
在此,东京大学的研究人员通过比较模型及其描述符在训练的各个步骤中的性能来解决这个黑匣子,这阐明了哪些类型的分子特征可以轻松地纳入描述符中,哪些类型则不能。特别是,专注于最流行的 NLP 模型 Transformer,这是当今用于描述符生成和其他化学语言任务的良好利用的架构。
具体来说,研究人员训练一个 Transformer 模型来翻译 SMILES 字符串,然后比较不同训练步骤中预测与目标之间分子指纹的完美一致性和相似性。还利用模型在训练的不同步骤生成的描述符进行了 6 个分子性质预测任务,并研究了哪些类型的任务容易解决。
研究进一步发现,Transformer 的翻译准确率有时会在较低水平上停滞一段时间,然后突然飙升。为了弄清楚其原因,研究人员比较了 SMILES 每个字符的翻译准确性。最后,寻找并找到了防止停滞和稳定学习的方法。
主要研究结果如下:
1、为了了解 Transformer 模型如何学习不同的化学结构,研究人员首先通过比较不同训练步骤的模型来研究学习过程与模型性能之间的关系。在 Transformer 模型中,在训练的早期阶段就可以识别分子的部分结构,而识别整体结构则需要更多的训练。结合之前关于 RNN 模型的研究,这一发现可以推广到使用 SMILES 字符串的各种 NLP 模型。因此,使 Transformer 模型能够将整体结构信息作为其结构中的辅助任务来引用,将有助于改进描述符生成模型。
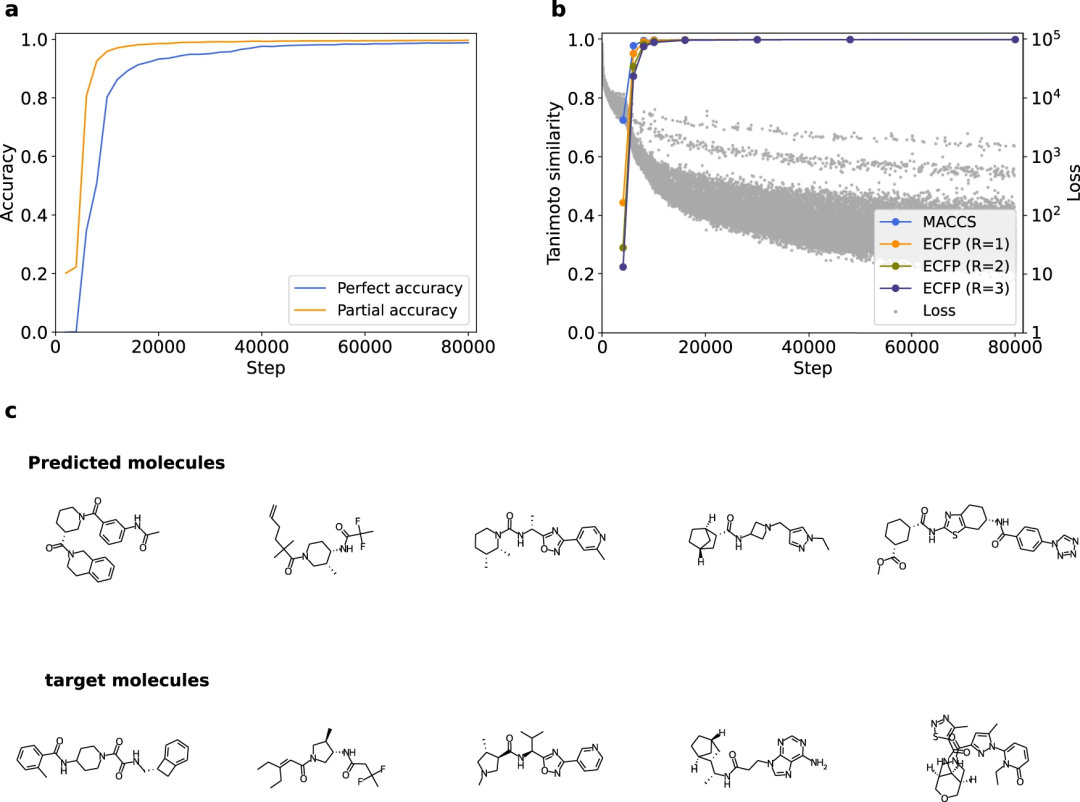
图 1:学习过程中 Transformer 的部分/整体结构识别。(来源:论文)
2、对于分子性质预测,Transformer 模型生成的描述符的性能在训练之前可能已经饱和,并且在后续的训练中没有得到改善。这表明初始模型的描述符已经包含了足够的下游任务信息,这可能是分子的部分结构。另一方面,也有可能下游任务,如分子的性质预测,对于 Transformer 来说太容易了,不适合评估基于 Transformer 的描述符生成方法。
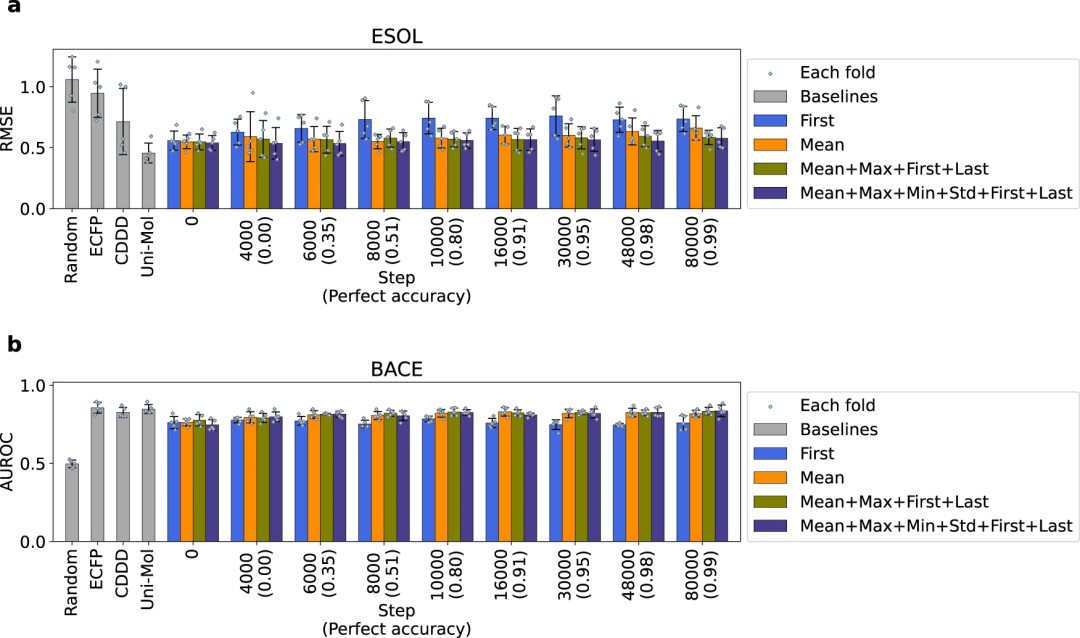
图 2:描述符在分子性质预测中的性能。(来源:论文)
3、与其他因素(例如整体结构或其他部分结构)相比,Transformer 在手性方面的翻译性能提升相对较慢,并且模型有时会长时间对手性产生混淆,导致整体结构识别持续停滞。这表明,向模型「教授」手性的额外结构或任务可以改善模型及其描述符的性能。
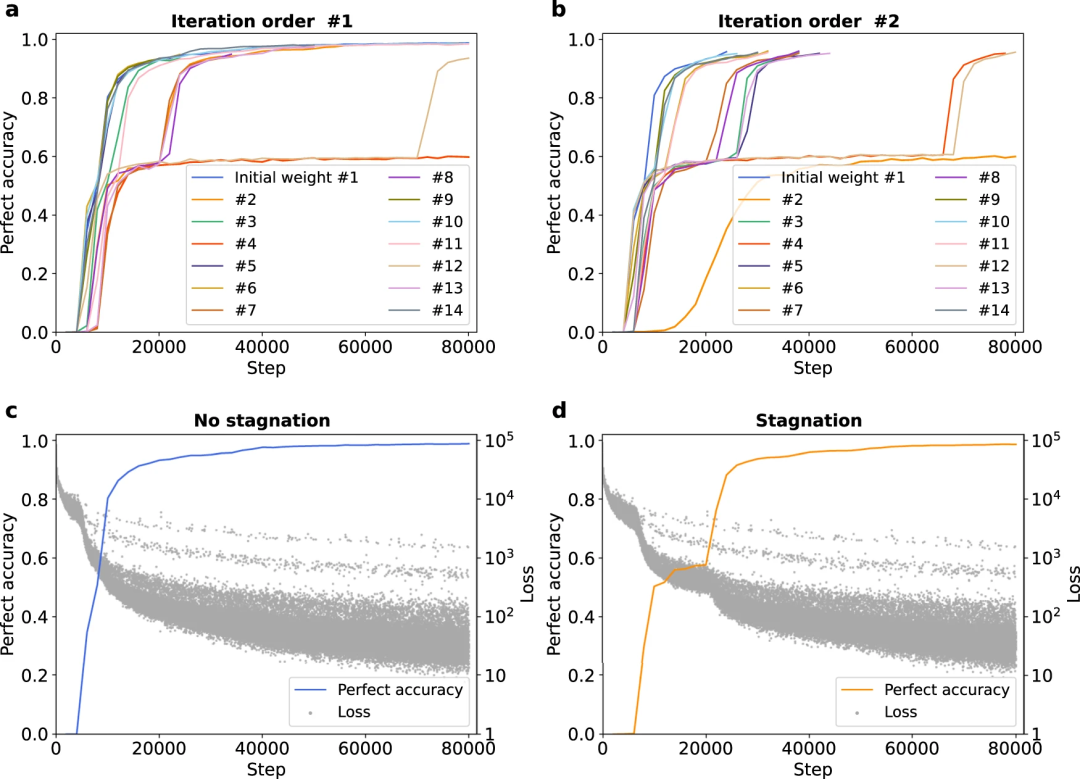
图 3:不同初始权重下完美精度的停滞。(来源:论文)
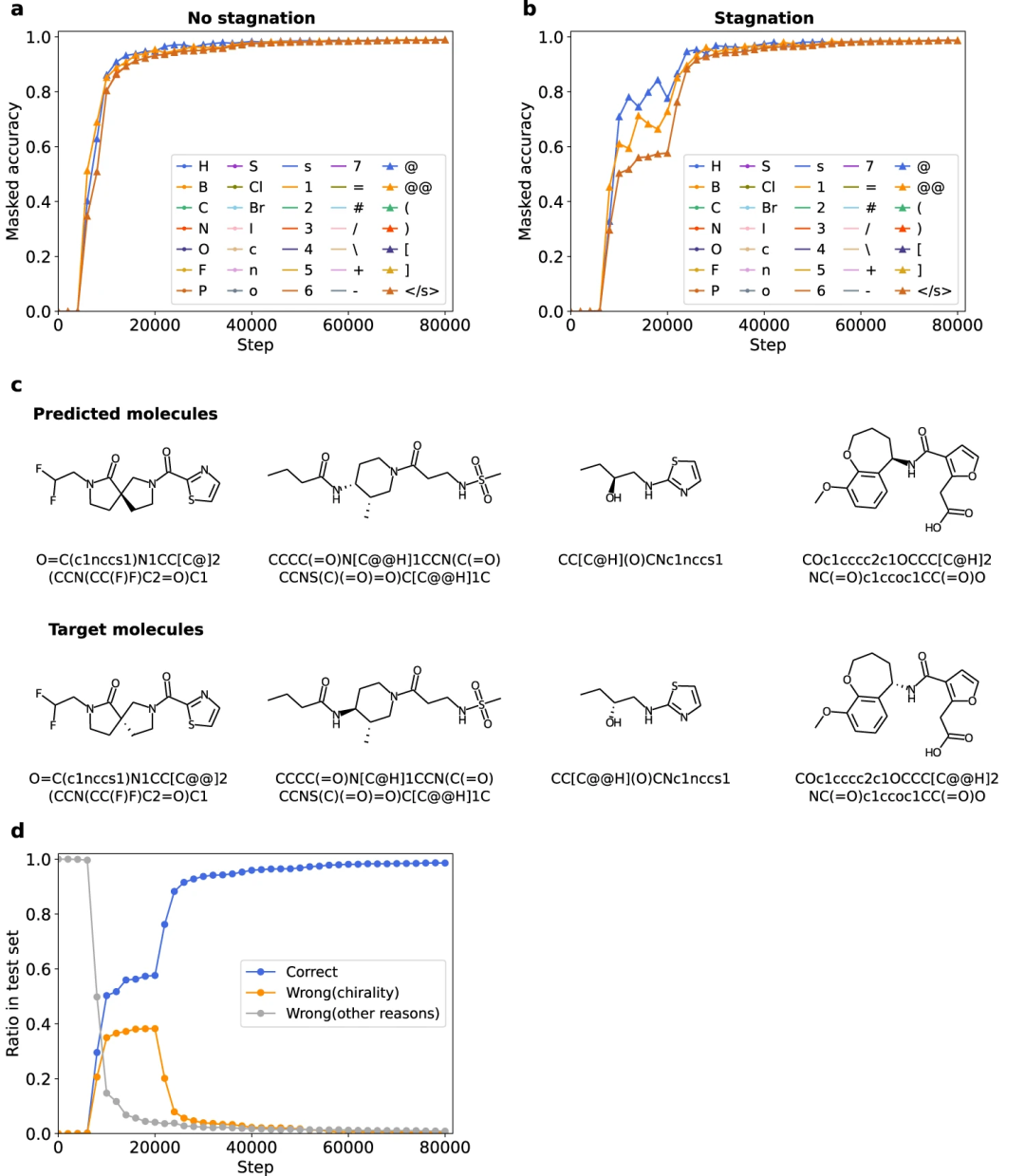
图 4:Transformer 的手性学习困难。(来源:论文)
4、引入pre-LN 结构可以加速并稳定学习,包括手性。
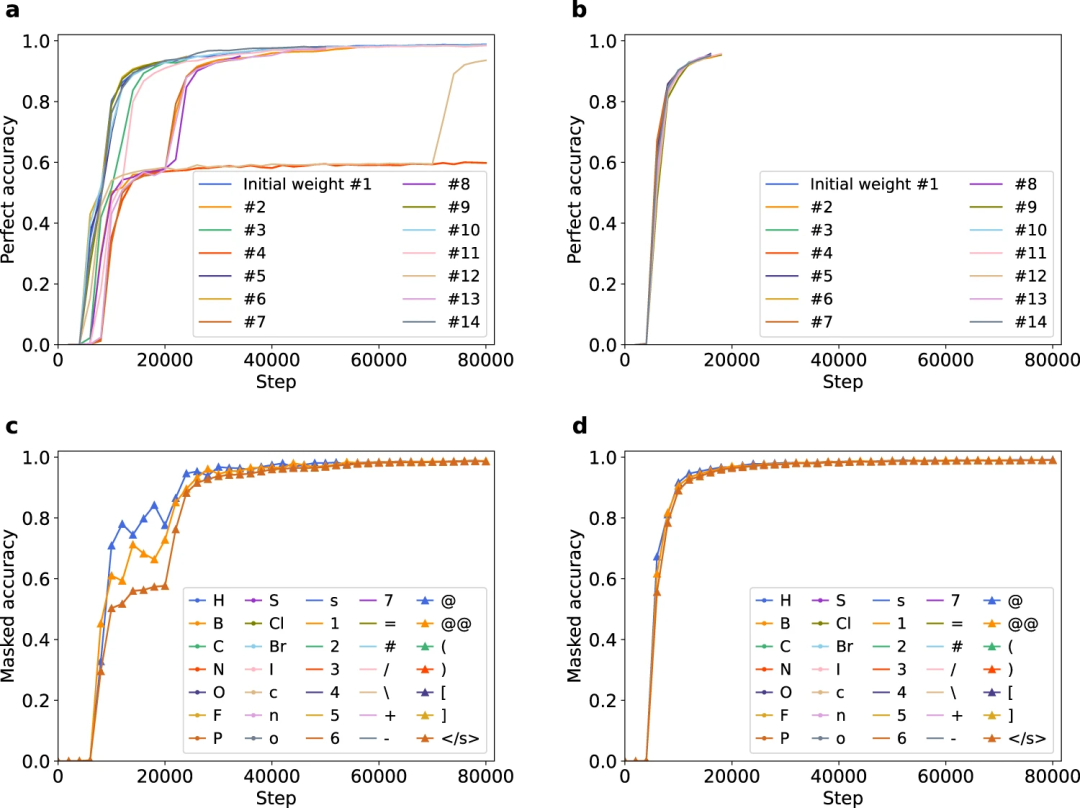
图 5:通过引入 pre-LN 改善停滞和手性识别。(来源:论文)
最后,为了阐明关于 Transformer 的研究结果的普遍性,研究人员使用另一种分子表达来训练模型。使用 InChI 代替 SMILES,这是一些化学语言模型化学信息学研究中采用的分子的替代文字表示。
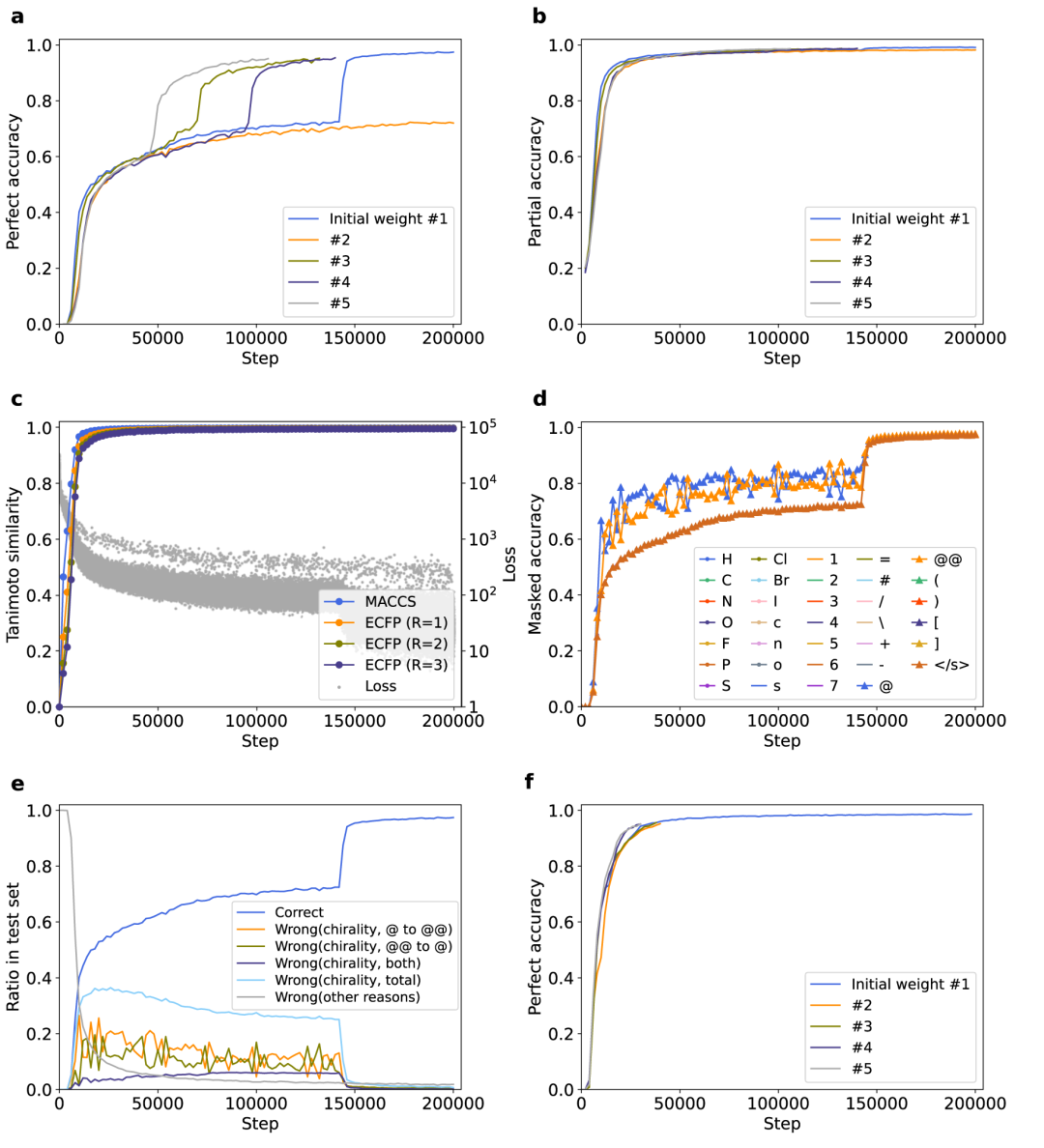
图 6:通过 InChI-to-SMILES 翻译训练的 Transformer 模型的实验。(来源:论文)
结果显示,与完全精度和损失函数相比,部分精度和指纹相似度早期饱和,表明在 InChI 到 SMILES 翻译中,部分结构的识别比整体结构更容易。下游任务的性能并没有通过训练得到改善。
结果还表明,InChI 到 SMILES 的翻译确实出现了停滞,区分对映体的混乱导致了停滞。此外,pre-LN 的引入缓解了停滞现象。
这些发现有助于澄清化学语言模型中的黑箱,并有望激活这一领域。研究这些发现是否适用于具有监督性质的其他应用(例如结构生成和端到端属性预测)的化学语言模型是一项有趣的未来任务。
由于 NLP 是深度学习中最先进的领域之一,化学语言模型将得到越来越多的发展。另一方面,与化学领域流行的神经网络模型(如图神经网络)相比,语言模型与化学结构之间的关系存在许多未知因素。
对 NLP 模型与化学结构之间关系的进一步基础研究,有望进一步澄清 NLP 模型如何进化和识别化学结构的黑盒子,从而促进化学中各种任务的化学语言模型的发展和性能的提高。


