Meta挖走OpenAI大批员工后,又用OpenAI的技术搞出新突破。
这是什么杀人又诛心(doge)?
新架构名为2-Simplicial Transformer,重点是通过修改标准注意力,让Transformer能更高效地利用训练数据,以突破当前大模型发展的数据瓶颈。
而核心方法,就是基于OpenAI提出的Triton,将标准点积注意力推广到三线性函数。

实验结果显示,在同等参数量和数据量下,相较于传统Transformer,新架构在数学、编程、推理等任务上均有更好的表现。
并且,2-Simplicial Transformer的缩放指数高于传统Transformer——这意味着随着参数增加,新架构加持下的模型性能提升更快,更适用于有限数据的场景。
传统Transformer的核心机制是点积注意力,其计算复杂度较低,但对复杂任务(如逻辑推理、数学运算等)表达能力有限。
针对于此,Meta的这项研究,重点放在将点积注意力从二元线性操作扩展到三元线性操作。
简单来说,就是在计算注意力时引入第三个向量,来增加模型对复杂模式的表达能力。
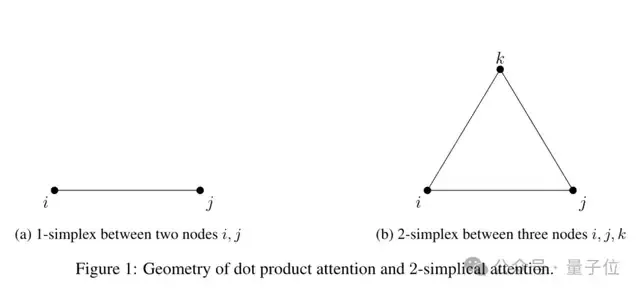
这第三个向量,是一个新的Key,写为K’,通过三元线性函数计算得到。
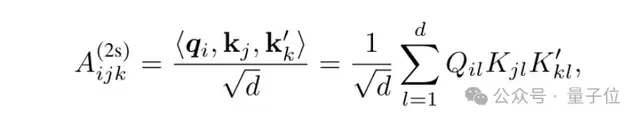
K’引入了额外的维度,使得注意力机制能够捕获更加丰富的关系。
举个例子,在处理推理任务时,可以用查询向量Q表示当前问题,用键向量K表示第一个参考信息,用K’表示第二个参考信息。
其中关键的一点在于,相比于点积,三元计算更为复杂。为此,这项研究引入了Triton来实现核心运算。
Triton是一种高效的GPU编程框架,最早由OpenAI提出。它旨在让研究人员无需CUDA经验,就能用较少的代码实现接近于手写CUDA的性能。
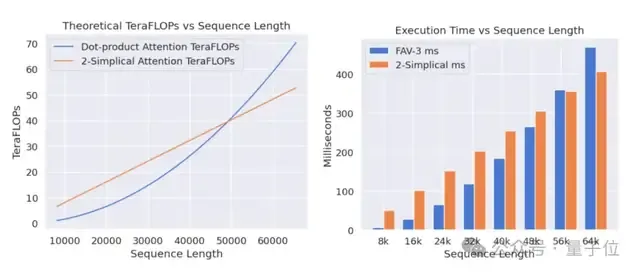
研究人员通过Triton实现了520TFLOPS(每秒万亿次浮点运算)的性能。
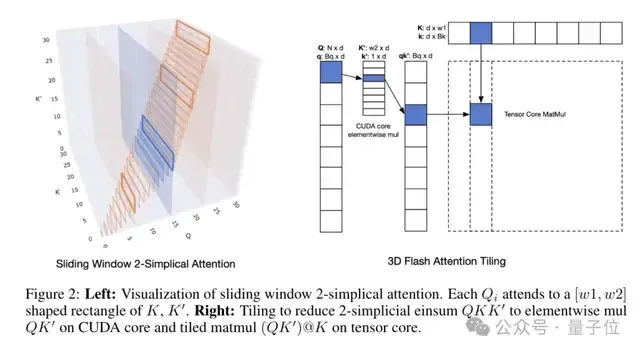
另外,论文还引入了滑动窗口(Sliding Window)机制,通过限制注意力的计算范围,来降低计算成本,同时保持较好的性能。
研究人员训练了一系列MoE模型来验证2-Simplicial Transformer的有效性。
模型规模从活跃参数10亿、总参数570亿,到活跃参数35亿、总参数1760亿不等。
在不同任务和模型规模上对比2-Simplicial Transformer和传统Transformer的负对数似然(值越小,说明模型对数据的预测越准确),结果如下:
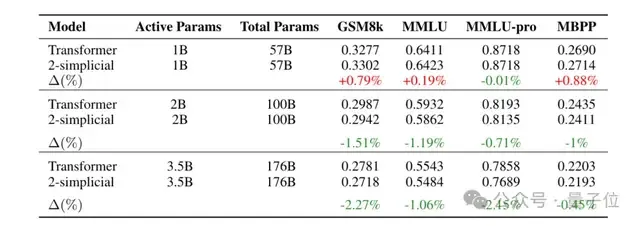
可以看到,在小模型(1B)上,2-Simplicial Transformer改进有限,在GSM8k、MBPP等任务中甚至出现了较为明显的性能下降。
但在较大模型上,2-Simplicial Transformer表现显著优于传统Transformer。
论文还分析了缩放指数的变化。

2-Simplicial Transformer的缩放指数α明显高于传统Transformer,说明模型性能随参数量、数据量的增加,变强速度更快。这也意味着,2-Simplicial Transformer在数据有限场景下优势会更加明显。
不过,研究人员也提到,目前,2-Simplicial Transformer的计算复杂度和延迟仍然较高,Triton虽然高效,但仍需进一步优化以适配生产环境。
新注意力机制引发讨论,而背后的Triton这次也牢牢吸引住了网友们的目光。


合着Meta的论文,这次算是给OpenAI的技术做了宣传了(doge)。
不过反过来也可以说,Meta这波不仅挖走了OpenAI的人,也玩转了OpenAI的技术。

论文地址: https://arxiv.org/abs/2507.02754
— 完 —


