鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
Transformer的提出者谷歌,刚刚上来给了Transformer梆梆就两拳(doge)。
两项关于大模型新架构的研究一口气在NeurIPS 2025上发布,通过“测试时训练”机制,能在推理阶段将上下文窗口扩展至200万token。

两项新成果分别是:
- Titans:兼具RNN速度和Transformer性能的全新架构;
- MIRAS:Titans背后的核心理论框架。
核心要解决的,就是Transformer架构在处理超长上下文时的根本局限:计算成本会随着序列长度的增加而猛增。
不得不说,从Nano Banana到Gemini 3 Pro,再到基础研究方面的进展,谷歌最近一段时间就是一个穷追猛打的架势。
也难怪奥特曼要给OpenAI拉“红色警报”了。
现在AI领域已经达成共识的是,Transformer虽好,但自注意力机制的效率问题正在日益凸显:每个token都要“关注”其他所有token,导致计算量和内存消耗与序列长度的平方成正比(O(N2))。
学界已经探索了多种解决方案,比如线性循环网络(RNNs)和状态空间模型(SSMs)等。
这类模型通过将上下文压缩到固定大小来实现快速线性扩展。问题是,这种方法仍然无法充分捕捉超长序列中的丰富信息。
Titans + MIRAS,是谷歌提出的新架构和理论蓝图,目的是将RNN的速度和Transformer的性能结合到一起。
其中Titans可以理解为具体的工具,而MIRAS则是理论框架。两者共同推进了测试时记忆的概念:
即模型在运行过程中,无需专门的离线重新训练,就能通过整合更多信息来维持长期记忆。
本质上,可以说这个新架构的重点,是重新定义Transformer的“记忆模式”,将其进化为一种更强大的混合架构。
具体来说,Titans引入了一种新的神经长期记忆模块。
与传统RNN中固定大小的向量或矩阵记忆不同,该模块本质上是一个在测试时动态更新权重的多层感知机(MLP)。
其独特之处就在于,通常模型训练完后,权重就固定了,但在Titans中,这个记忆模块在推理阶段依然在更新。
MAC(Memory as Context)是Titans架构的一种主要变体,设计思路是,将长期记忆作为一种额外的上下文信息,直接“喂”给注意力机制。
MAC并没有改变注意力机制本身的计算方式,而是改变了注意力机制的输入来源。它把从长期记忆中提取的信息,当作是历史信息的“摘要”,与当前的短期输入一起进行处理。
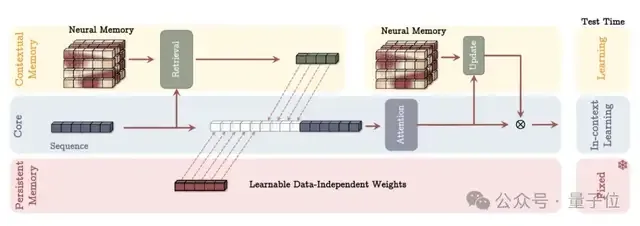
△MAC架构
研究人员发现,这个新的记忆模块能显著提升模型的表达能力,使其在不丢失重要上下文的情况下概括并理解大量信息。
更为重要的是,Titans并非被动地存储数据,而是能在输入数据中,主动学习如何识别并保留连接各个token的重要关系和概念。其中的关窍是“意外”。
在人类心理学中,我们很容易忘记一些常规的、预期之内的事情,但往往对“意外事件”印象深刻。
对于Titans也存在类似的情况。研究人员将其定义为“惊喜指标”(surprise metric):指模型检测到当前记忆的内容和新输入内容之间存在较大差异。
- 低意外度:比如新词是“猫”,而模型的记忆状态已经预测到会有一个动物词,那么梯度(意外度)就很低。这时模型仅将这个词作为短期记忆来处理即可。
- 高意外度:如果模型的记忆状态是正在总结一份严肃的财务报告,而新的输入是香蕉皮的图片(意外事件),则意外度将非常高。这表明新的输入很重要或异常,需要优先将其存储到长期记忆模块中。
这样对“意外”的判断使得Titans架构能够有选择地更新长期记忆,从而保持快速和高效。
实验表明,Titans的MAC变体能够有效将上下文窗口扩展到200万,并在“大海捞针”任务中保持高准确率。
如果说Titans是跑车,那么MIRAS就是背后的核心引擎。
MIRAS核心目标是让模型在推理阶段也能进行学习。其独特之处在于,它不把不同的架构视为不同问题的解决方法,而是将其视为解决同一问题的不同途径:
高效地将新信息与旧信息相结合,同时又不遗漏关键概念。
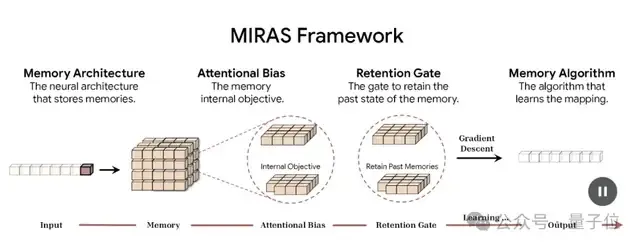
MIRAS将任意序列模型结构为4个关键设计选择:
- 内存架构:存储信息的结构(如向量、矩阵,或Titans中的MLP)。
- 注意力偏差:模型优化的内部学习目标,决定模型优先考虑的内容。
- 保留门控(Retention Gate):即“遗忘机制”,用于平衡“学习新知识”与“保留旧记忆”。
- 记忆算法:用于更新记忆状态的优化算法。
现有的序列模型大多依赖均方误差(MSE)或点积相似度来更新记忆。
MIRAS的另一个创新,是引入非欧几里得目标函数,允许使用更复杂的数学惩罚机制。
谷歌的研究人员基于MIRAS,创建了三个特定的无注意力模型:
- YAAD:使用更温和Huber Loss来处理错误,对异常值(如文档中的拼写错误)不敏感,鲁棒性更强。
- MONETA:使用Generalized Norms(广义范数),通过更严格的规则来管理注意力和遗忘,提升记忆稳定性。
- MEMORA:强制记忆像概率图一样运作,确保信息整合过程的受控和平衡。
实验结果显示,基于Titans和MIRAS的模型性能优于最先进的线性循环模型(如Mamba 2),以及规模相近的Transformer基线模型。
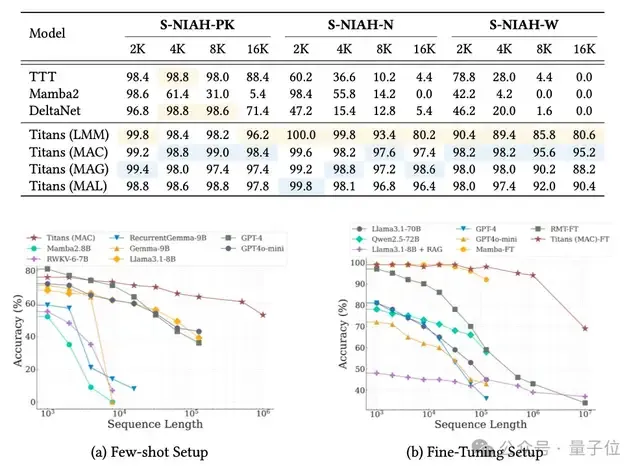
更显著的优势在于,新架构能够处理极长上下文,在参数规模小得多的情况下,性能优于GPT-4等大规模模型。
超越Transformer的探索还在继续,但不可否认的是,Transformer依然是大模型时代的理论基石。
那么,曾经一度在竞争中落后的谷歌,是否会后悔公开了Transformer的研究呢?
同样是在NeurIPS 2025上,Jeff Dean回答了诺奖得主、图灵奖得主Hinton提出的这个问题:
不,它对世界产生了巨大的积极影响。
这格局,谷谷人人又希希了。
参考链接:[1]https://research.google/blog/titans-miras-helping-ai-have-long-term-memory[2]https://arxiv.org/abs/2501.00663[3]https://arxiv.org/abs/2504.13173


