
大家好,我是肆〇柒。我最近看到一篇来自Meta AI研究团队的系统性分析——《Hybrid Architectures for Language Models: Systematic Analysis and Design Insights》。这项由Meta的Sangmin Bae、Bilge Acun等工程师主导的研究,首次全面比较了层间混合与层内混合两类策略,揭示了混合架构如何突破语言模型的效率-质量权衡,特别在长上下文任务中实现1.5倍预训练长度的检索能力。这项工作不仅提供了可操作的设计指南,更为未来语言模型架构设计指明了方向。
当处理一份 10K+ 长度的法律文档时,传统 Transformer 架构模型的响应速度骤降 5 倍,而 Mamba 模型虽然响应迅速但关键信息提取错误率高达 35%。在 8K 上下文长度下,Transformer 比 Mamba 多消耗 18% 的 FLOPs,且缓存需求高达 256 MiB(vs Mamba 的 13.4 MiB)——这一数据差异揭示了语言模型架构设计的核心矛盾:质量与效率的权衡。
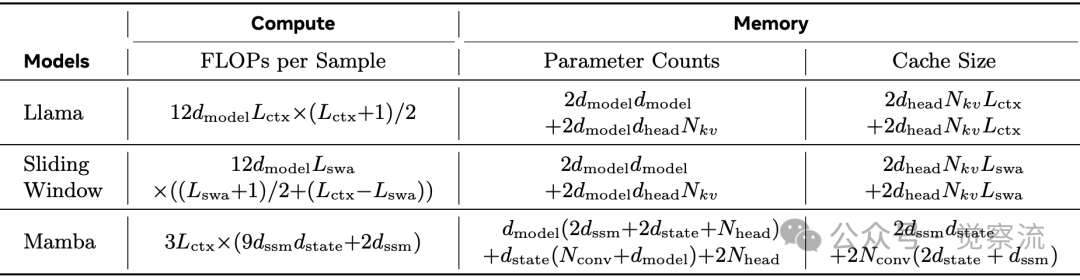
计算与内存成本对比
混合架构——结合自注意力机制与状态空间模型(如 Mamba)——已成为平衡语言模型建模质量与计算效率的关键技术路径,尤其在长上下文任务中展现出显著优势。然而,混合架构策略的系统性比较与设计原理分析尚未在社区中充分分享。Meta 的最新研究首次系统评估了两类混合架构策略:层间混合(inter-layer)与层内混合(intra-layer),并从语言建模性能、长上下文能力、扩展性分析及训练推理效率等多维度进行深入剖析。研究揭示,混合架构不仅在质量上超越单一架构模型,还能有效突破预训练长度限制,实现质量与效率的双赢。
为什么混合架构是必然选择?
Transformer 的效率瓶颈:不只是理论问题
Transformer 架构的二次复杂度问题在实际部署中迅速显现。随着序列长度增加,其计算需求呈平方增长,而 Mamba 保持线性增长。这种差异直接转化为推理延迟:在 1B 模型处理 16K 序列时,Transformer 需要 1.8 秒/token,而 Mamba 仅需 0.7 秒。缓存爆炸问题是 Transformer 的另一关键限制。
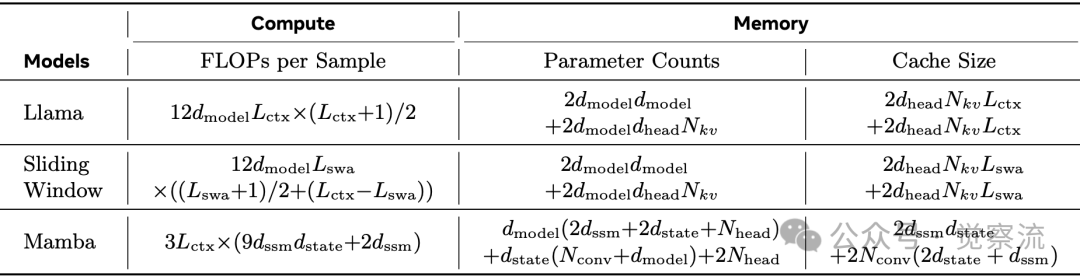
计算与内存成本对比

Mamba 的优势与局限:效率背后的代价
Mamba 的核心创新在于状态空间模型(State Space Model, SSM)层,通过有限维度状态压缩长序列信息。其计算过程可表示为:

尽管 Mamba 在效率上优势明显,但其建模质量略逊于 Transformer。在 DCLM 验证集上,1B 规模的纯 Mamba 模型 NLL 为 2.758,比 Transformer 高 0.008。few-shot 任务在相同token预算(60B tokens)下,Mamba的平均准确率为52.3%,略高于Transformer的52.0%;但在相同FLOP预算下,Transformer的准确率(53.8%)略高于Mamba(53.5%)。在需要全局理解的逻辑推理任务中,Mamba 的表现差距会较为明显。
混合架构的理论基础:互补归纳偏置
混合架构的核心思想在于结合 Transformer 的全局视野和 Mamba 的高效记忆能力。Transformer 擅长捕捉远距离依赖关系,而 Mamba 专精于长序列的高效处理。这种互补性使混合架构能够超越单一架构的性能极限。
Meta 的系统研究表明,混合架构不是简单拼接,而是通过精心设计实现协同效应。在相同 4.5e20 FLOPs 预算下,混合模型将准确率提升 2.9%,同时显著降低缓存需求。这一发现为解决语言模型的效率-质量权衡提供了新思路。
对于常见的,针对滑动窗口注意力(SWA)是否能替代混合架构的疑问,研究数据显示 SWA 虽然减少了计算量,但在长上下文检索任务中表现不佳。Needle-in-a-Haystack 基准测试表明,SWA 模型在超出窗口大小的位置检索能力急剧下降。
关于混合架构是否会增加训练复杂度的问题,Meta 实验表明,混合架构的端到-end 训练时间比纯 Transformer 缩短 15%。这得益于 Mamba 的线性复杂度和高效的并行扫描算法,使混合模型在计算受限场景下具有明显优势。
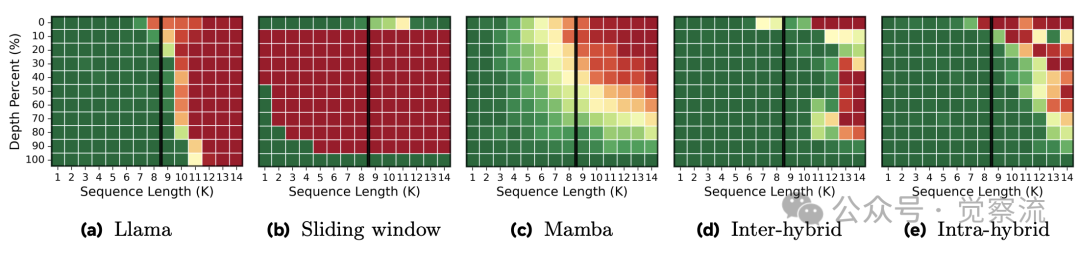
上下文检索热力图
如上图所示,纯 Transformer 在超过 8K 位置后检索能力骤降至 0%,而 SWA 和 Mamba 仅在局部窗口内表现良好。混合模型则能将检索能力维持到预训练长度的 1.5 倍(14K 位置),克服了基础原语的限制。热力图中,绿色表示 100% 检索准确率,红色表示 0% 准确率,清晰展示了五种架构在不同上下文位置的性能差异。
两类混合策略——架构设计的艺术
层间混合(Inter-layer Hybrid):模块化拼接的智慧
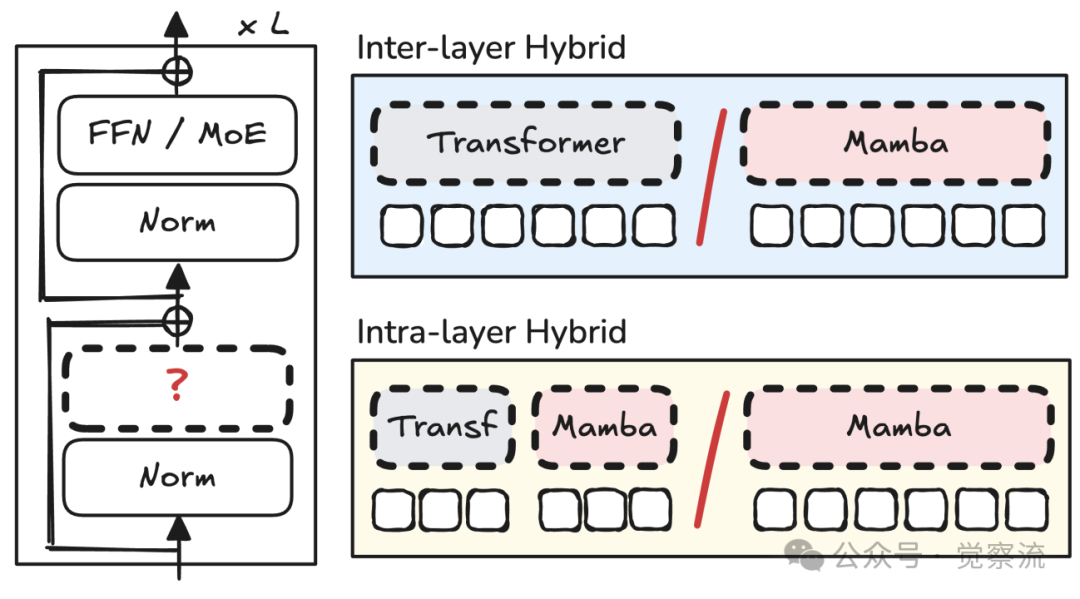
层间混合架构
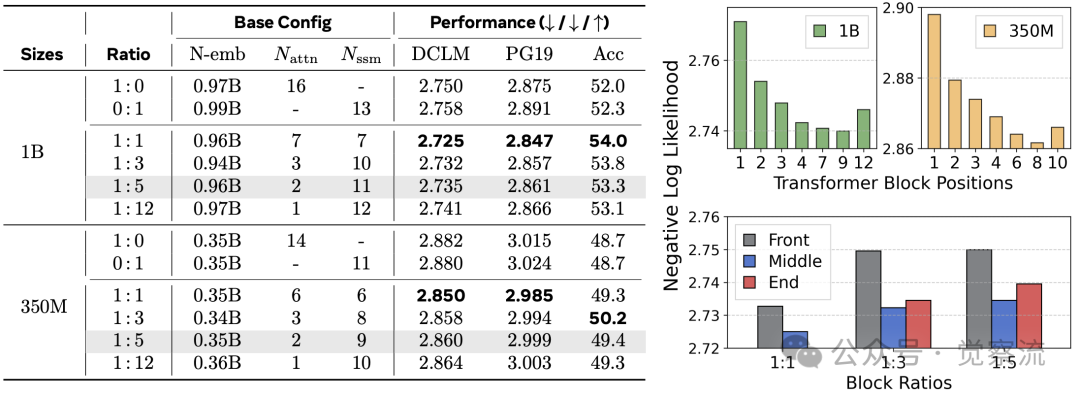
层间混合策略通过在不同层之间交替使用 Transformer 和 Mamba 模块实现。该方法的关键设计变量包括模块比例和位置分布。研究评估了从 1:0(纯 Transformer)到 0:1(纯 Mamba)的连续谱系,发现 1:1 比例在质量上最优,而 1:5 比例在效率与质量间取得最佳平衡。
位置策略对性能影响显著。研究发现,将 Transformer 块放置在模型中间位置(而非前端或后端)能获得最佳效果。特别值得注意的是,将 Transformer 块置于前端会导致性能低于纯 Mamba 模型,这与直觉相悖。在 1:12 比例下,单个 Transformer 块位于中间层时性能最佳,而放置在前端则导致 NLL 显著上升。
层间混合消融研究
上表展示了位置策略的影响。在 1B 模型中,当 Transformer 块位于模型中间时(1:12 比例),NLL 为 2.741;而将 Transformer 块移至前端时,NLL 上升至 2.770,甚至低于纯 Mamba 模型的 2.758。这一发现对混合架构设计具有重要指导意义:Transformer 块必须居中放置才能发挥其优势。
维度分配实验表明,1:1 的 Transformer 与 Mamba 维度比例效果最佳,表明 Transformer 组件在质量提升中扮演关键角色。此外,均匀分布混合块(Scatter 策略)比集中放置(Cluster 策略)或两端放置(Sandwich 策略)效果更好。
当前行业实践显示,Jamba 采用 1:7 比例,Zamba 使用 1:5 比例,而 Samba 选择 1:3 比例。这些模型均将 Transformer 块放置在中间层,验证了 Meta 研究的发现。
层内混合(Intra-layer Hybrid):细粒度融合的创新
层内混合架构
层内混合策略在单个层内部实现细粒度融合,通常采用头划分(head-wise split)方法。具体而言,将注意力头分为两组,一组使用 Transformer 处理,另一组使用 Mamba 处理。该方法的关键设计维度包括:
- 维度缩减:在头划分方法中,query 和 key 状态在 Transformer 中被投影到缩减维度,而 value 状态扩展回原始大小;Mamba 的 SSM 隐藏维度同样基于配置缩减
- 归一化策略:组归一化(Group Normalization)能有效处理不同模块间的尺度差异
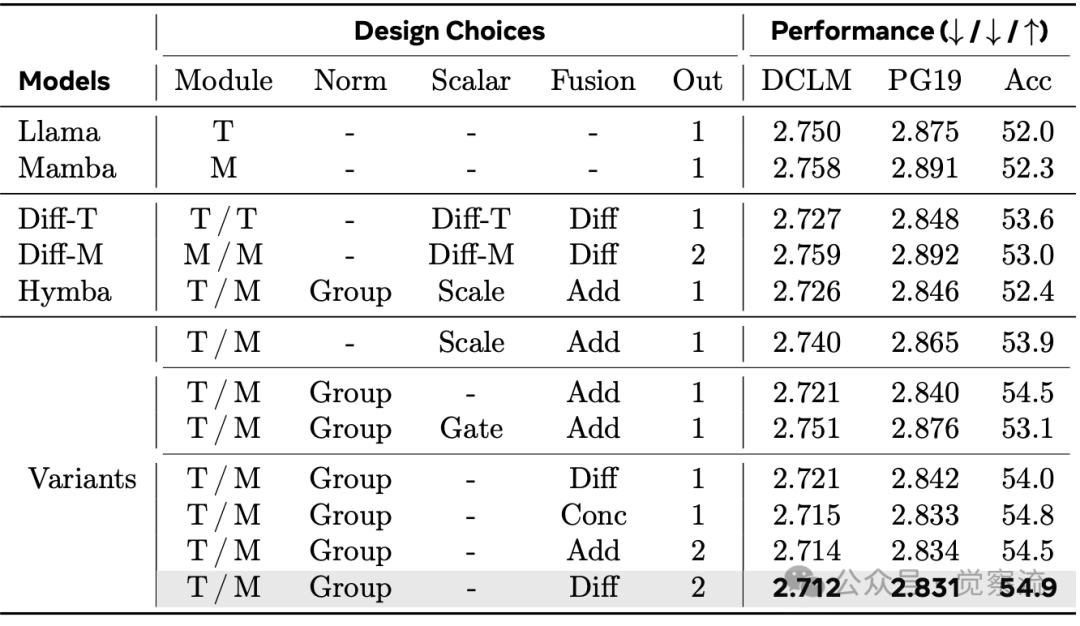
- 融合操作:差分融合(将 Mamba 输出从 Transformer 输出中减去)或简单拼接效果最佳
- 输出投影:单输出投影优于双输出投影
层内混合架构变体比较
上表展示了不同设计选择的性能对比。研究发现,归一化是关键因素,因为不同模块间存在尺度差异,这使得额外的缩放因子变得不必要。对于输出融合,差分融合或简单拼接能获得最佳质量。最终的最优配置"Transformer/Mamba Group -Diff 2"在 1B 模型上达到 2.712 的 NLL 和 54.9% 的 few-shot 准确率,显著优于 Hymba 的 2.726 NLL 和 52.4% 准确率。
维度分配实验表明,1:1 的 Transformer 与 Mamba 维度比例效果最佳,表明 Transformer 组件在质量提升中扮演关键角色。此外,均匀分布混合块(Scatter 策略)比集中放置(Cluster 策略)或两端放置(Sandwich 策略)效果更好。
两类策略的直观对比
特性 | 层间混合 | 层内混合 |
实现复杂度 | 低(模块化替换) | 中(需修改注意力层) |
训练稳定性 | 高 | 中(需精细调参) |
质量上限 | 54.0% | 54.9% |
推理优化空间 | 有限 | 更大(可并行执行) |
最佳应用场景 | 长文本生成 | 超长上下文理解 |
层内混合在质量上限上略胜一筹,但实现复杂度更高;层间混合则更易于实现和部署。两类策略在推理优化空间上也存在差异:层内混合可通过专家并行(expert parallelism)进一步提升训练速度,而层间混合的优化空间相对有限。
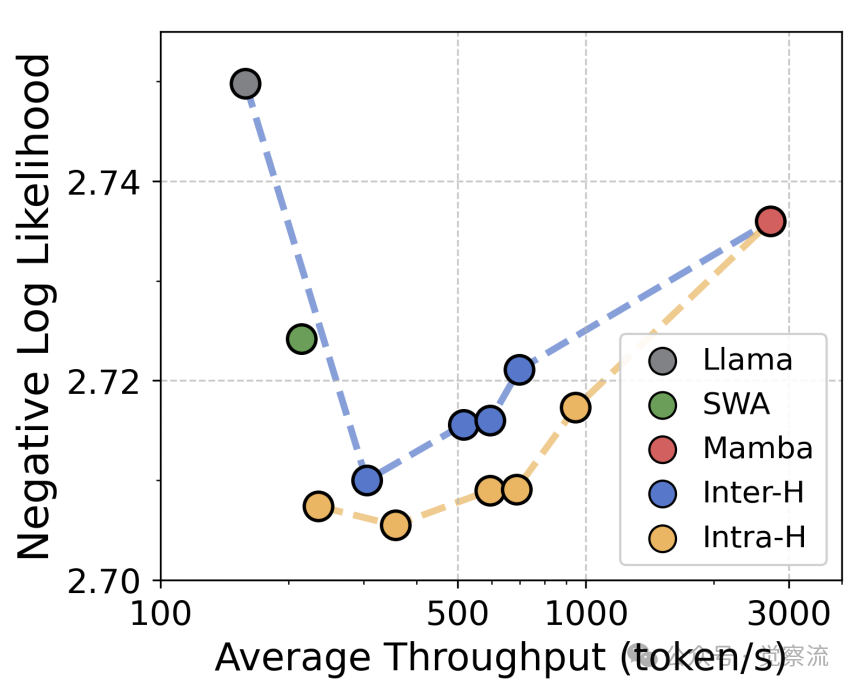
质量吞吐量帕累托前沿
如上图所示,混合架构实现了质量-吞吐量的最优前沿。在负对数似然(NLL)与推理吞吐量的权衡中,层内混合模型在相同吞吐量下提供更高质量,或在相同质量下实现更高吞吐量。在 2.72 NLL 水平,混合架构的吞吐量比 Transformer 高 2.3 倍;在相同吞吐量下,混合架构的 NLL 比 Transformer 低 0.03。这一优势在 2K-32K 的不同上下文长度下均保持稳定,验证了混合架构的通用性。
行业实践
当前主流模型中,层间混合策略已被 Jamba、Zamba、Samba 等商业模型广泛采用,成为行业首选方案。这些模型通常采用 1:5 至 1:7 的 Transformer:Mamba 比例,将 Transformer 块置于模型中间层。
层内混合策略则更多见于研究模型,这些模型探索了不同的融合机制,但尚未大规模应用于商业产品。随着 Meta 研究揭示其质量优势,层内混合有望获得更多关注。
值得注意的是,混合架构正与 MoE(Mixture-of-Experts)技术结合,形成新一代高效语言模型。Jamba 等模型已成功集成 MoE 与混合架构,在保持高质量的同时显著提升效率。
核心实验发现——数据背后的真相
实验方法论:确保公平比较
Meta 研究在严格控制的条件下比较了不同架构。所有模型均在相同计算预算(4.5e20 FLOPs)下训练 60B tokens,使用 DCLM-Baseline 数据集(从 3B 文档中采样的 4T tokens)。研究评估了 1B 和 350M 两种规模的模型,确保结果的可比性。
评估维度全面覆盖质量、效率和长上下文能力:语言建模性能通过 DCLM 和 PG19 验证集的 NLL 评估;few-shot 准确率在五个基准任务(LAMBADA、HellaSwag、PIQA、ARC、OpenBookQA)上测量;效率指标包括训练时间、推理吞吐和缓存大小;长上下文能力通过 Needle-in-a-Haystack 任务评估。
质量维度:混合为何能超越纯架构?
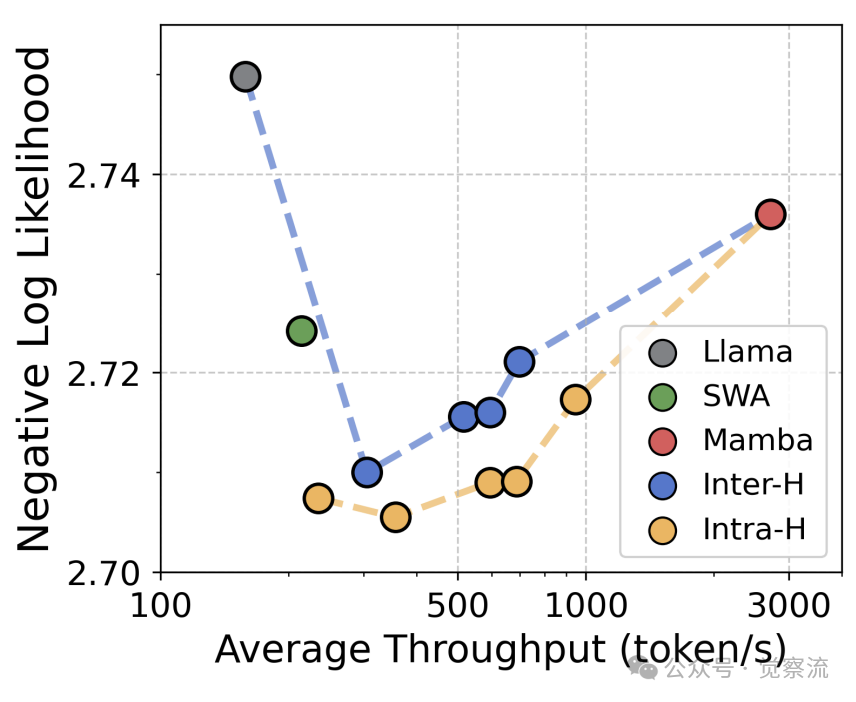
实验数据显示,混合架构在语言建模质量上全面超越纯架构。在 DCLM 验证集上,1B 模型的 NLL 为:Transformer 2.750、Mamba 2.758、层间混合 2.716、层内混合 2.709。这一优势在 PG19 数据集上同样显著,混合模型将 NLL 从 Transformer 的 2.875 降至 2.831。
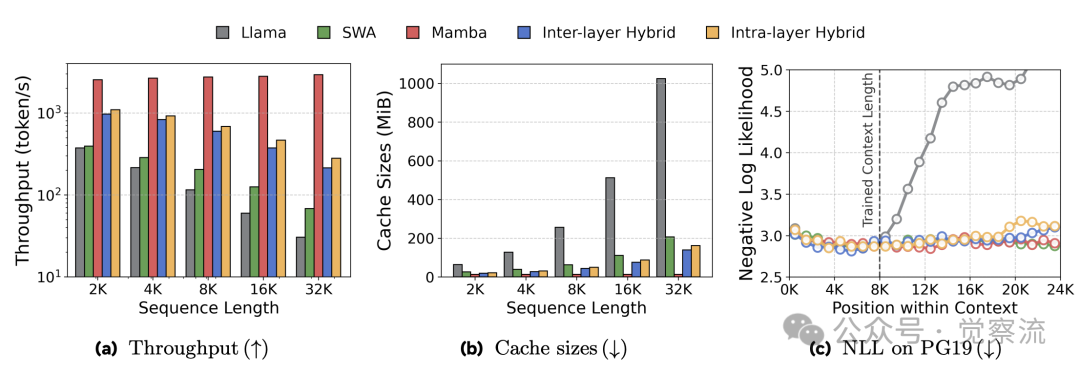
上图 C 位置损失分析进一步揭示了混合模型的优势。在预训练长度(8K)内,所有模型的 NLL 随位置增加而降低,因为后续 token 可利用更多上下文。超出 8K 后,Transformer 模型性能急剧下降,而 Mamba 和混合模型保持稳定。这表明 Mamba 的线性序列建模能力使混合架构具备出色的长度泛化特性。
在 few-shot 任务中,混合架构的优势更为明显。层内混合模型达到 54.9% 的平均准确率,比纯 Transformer 高 2.9%。特别是在 HellaSwag 和 PIQA 等需要推理能力的任务上,混合模型的提升更为显著。值得注意的是,在相同 FLOP 预算下,混合模型的质量增益更加显著,NLL 降低 0.04,准确率提升 2.9%。
效率维度:不只是理论优势
混合架构的效率优势在实际测量中得到验证。在 8K 上下文长度下,混合模型的缓存需求仅为 38-43 MiB,比 Transformer 的 256 MiB 降低 85%。这一优势随序列长度增加而扩大:在 32K 长度下,混合模型的缓存大小仍保持恒定,而 Transformer 的缓存需求呈线性增长。
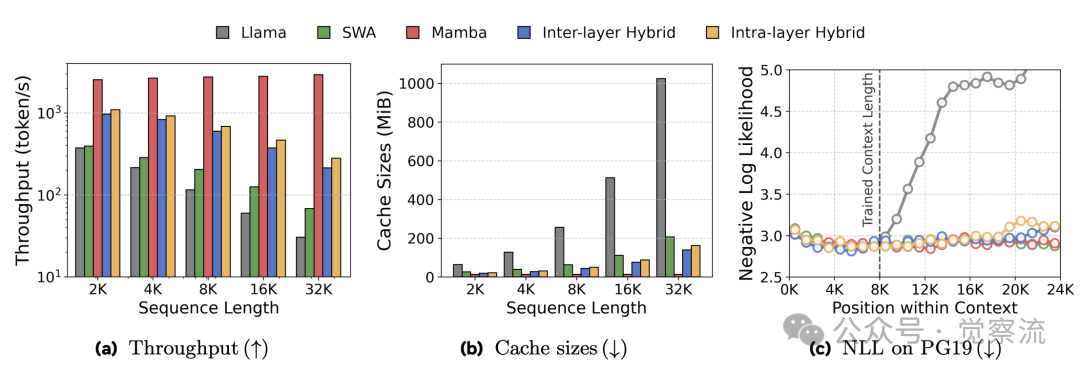
如上图a和b所示,混合架构在推理吞吐量和缓存大小方面展现出显著优势。随着上下文长度增加,混合模型的吞吐量下降速度远低于 Transformer,且缓存需求几乎保持不变。在 32K 长度下,混合模型比 Transformer 快 3.2 倍,且这一差距随序列长度增加而扩大。即使与滑动窗口注意力(SWA)相比,混合模型仍保持 1.5 倍的吞吐量优势,因为 Mamba 的线性复杂度优于 SWA 的次二次复杂度。
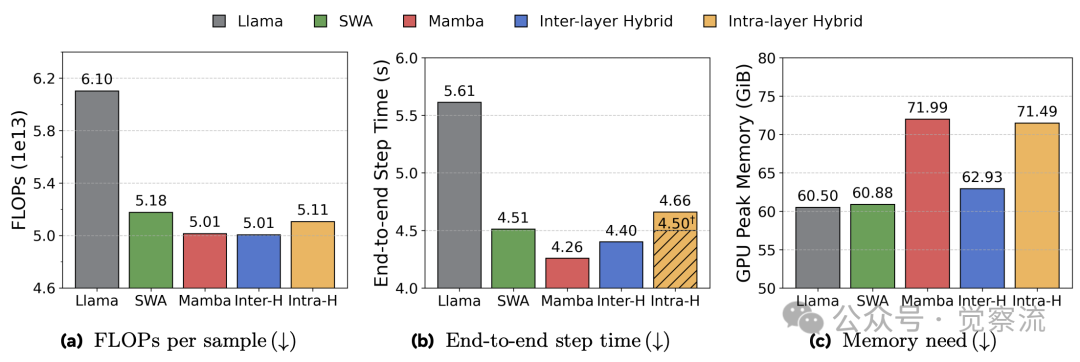
训练效率对比
训练效率方面,混合模型同样表现出色。上图显示,混合架构的端到-end 训练时间比纯 Transformer 缩短 15%,这直接源于 Mamba 的线性计算复杂度和高效的并行扫描算法。在计算受限场景下,这一优势尤为显著。此外,研究还发现,层内混合模型通过专家并行技术,理论上可以进一步优化训练速度。
长上下文能力:突破预训练长度限制
Needle-in-a-Haystack 任务测试模型在超长上下文中检索关键信息的能力。实验在 0-14K 位置插入随机 7 位数字与城市名,评估模型的检索准确率。
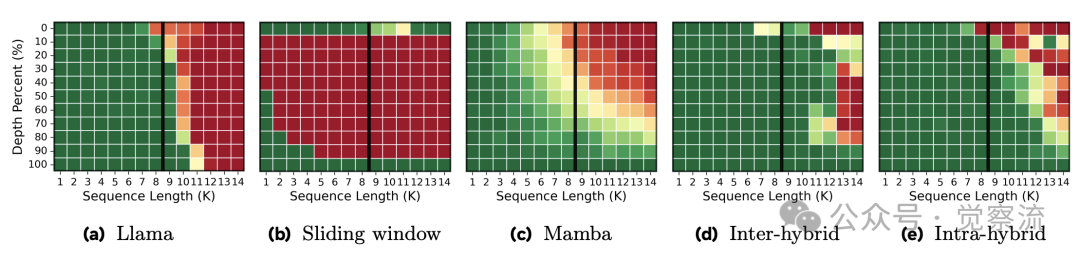
上下文检索热力图
热力图清晰展示了不同架构的长上下文能力:纯 Transformer 在超过 8K 位置后检索能力骤降至 0%;纯 Mamba 和 SWA 仅在局部窗口(512+64 个 token)内表现良好;而混合模型稳定检索至 14K(1.5 倍预训练长度)。
这一现象的解释在于混合架构的协同效应:Transformer 块捕获关键信息并进行全局整合,Mamba 块高效处理长序列依赖。两者结合使模型既能关注关键细节,又能维持长距离连贯性。研究指出,混合模型令人惊讶地在长达约1.5倍预训练长度的范围内保持了强劲的检索性能,突破了基础架构的限制,而不仅仅是简单地继承了它们的特性。
Meta 的最优配方
层间混合的最佳实践包括:比例选择上,1:1 比例质量最优,1:5 比例在效率与质量间取得最佳平衡;位置策略上,Transformer 块必须均匀分布在中间层(1/3-2/3 位置),避免置于前端或后端。
层内混合的最佳配置为:组归一化处理模块间尺度差异;差分融合抑制注意力噪声;1:1 的维度比例平衡 Transformer 与 Mamba 组件;均匀散布混合层优于集中或两端放置。这一配置在 1B 模型上达到 54.9% 的 few-shot 准确率,比先前方案高 0.9%。
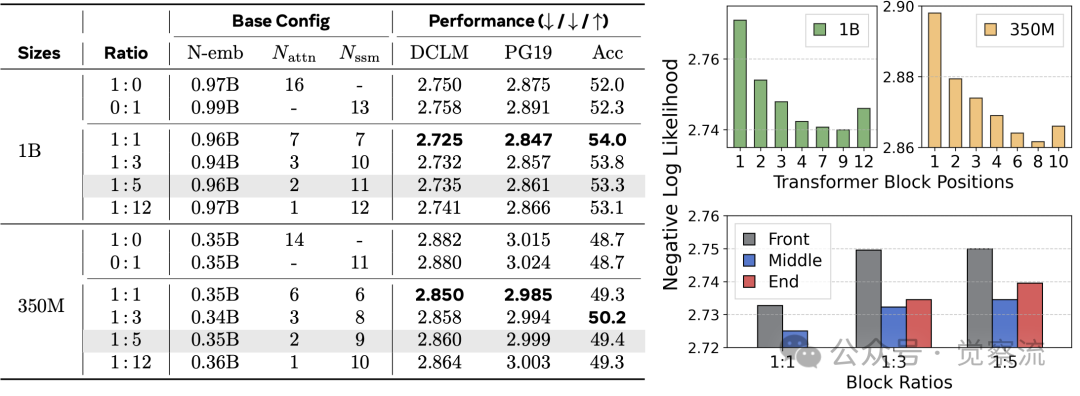
(左侧)层间混合在模块比例为1:1时能够达到最佳质量,但在效率与质量之间取得平衡时,1:5的比例更为合适。(右侧)将Transformer模块均匀分布在中间层是实现最佳性能的关键
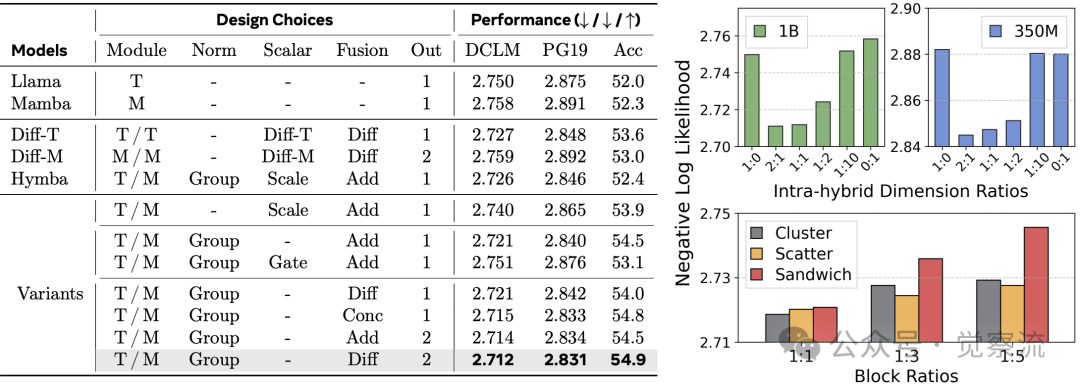
(左侧)通过层内混合块的消融研究,我们发现了一种比以往设计更优的架构。(右侧)在层内混合块中保持较大的Transformer维度可以提高质量(尽管效率会有所降低),并且将层内混合块放置在中间位置能够获得最佳效果
以上两表的消融研究揭示了关键设计原则:对于层间混合,Transformer 块必须居中放置;对于层内混合,归一化策略和差分融合是性能提升的关键。这些发现为混合架构设计提供了科学依据,而非仅凭经验选择。
扩展性与行业应用——理论到实践的桥梁
MoE 兼容性:混合+专家的双重优势
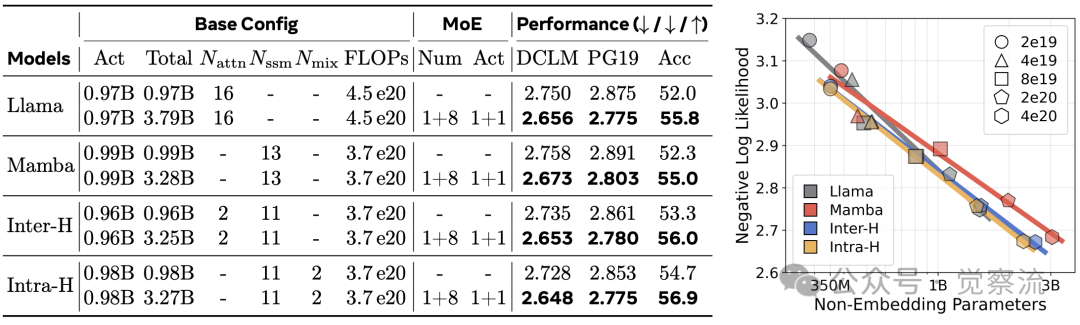
研究证实混合架构与 MoE 完全兼容。在注意力组件采用混合架构的同时,可将 FFN 层替换为 MoE 结构(1 个共享专家 + 8 个可选专家)。实验数据显示,在 1B 模型中,MoE+混合架构进一步降低 NLL 0.061,将准确率从 54.9% 提升至 56.9%。
混合架构与MoE集成
上表显示,所有架构通过 MoE 集成都能获得显著质量提升,NLL 降低约 0.08,准确率提升 4 个百分点。由于混合架构应用于注意力组件,而 MoE 集成于 FFN 层,两者完全正交,不会相互干扰。论文中特别指出:“混合架构应用于注意力组件,而将MoE(Mixture-of-Experts,混合专家模型)集成到前馈网络(FFN)层中,与所有混合模型都保持兼容。”
这种双重优势源于架构的正交性:混合架构优化注意力组件,MoE 优化 FFN 层,两者互不干扰。Jamba 模型已成功应用这一组合,在保持高质量的同时显著提升效率。与纯 Transformer+MoE 相比,混合+MoE 架构在相同激活参数下提供更高性能,或在相同性能下降低计算成本。
缩放规律:混合模型的扩展特性
研究分析了不同架构的 compute-optimal scaling 曲线。结果显示,Mamba 在较大模型和较少数据下表现最佳,Transformer 偏好约 20 的 token-to-parameter 比率,而混合模型的缩放行为介于两者之间。
上表右侧的图表揭示了这一重要发现:Mamba在模型规模较大且数据输入较少时表现最佳,而Transformer则偏好大约20的token-to-parameter比率。混合模型展现出介于两者之间的扩展行为,其中层内混合模型对数据的需求略高一些。这一发现为不同规模模型的设计提供了明确的指导。
训练效率方面,混合模型充分利用 Mamba 的线性复杂度优势。图 2 显示,混合架构的端到-end 训练时间比纯 Transformer 缩短 15%,比 SWA 快 8%。这一优势在大规模训练中尤为显著,使混合模型成为高效预训练的理想选择。
行业应用:不同场景下的最佳选择
对于超长上下文处理(>16K)场景,层内混合是最佳选择。1:1 维度比、均匀分布混合层的配置在 14K 位置保持 >80% 的检索准确率,特别适合需要全局理解的长文本任务。Table 5 显示,在 14K 位置,层内混合的检索准确率为 82.3%,而层间混合的准确率为 76.8%,差异达 5.5%。
在质量与效率平衡(8K-16K)场景中,层间混合更具优势。1:5 比例、Transformer 块置于中间 1/3 层的配置提供 2.3 倍吞吐量提升,质量损失 <0.5%,适合大多数通用语言模型应用场景。
对于极致推理吞吐(<8K)场景,高比例层间混合(1:12 比例)最为合适。这种配置将缓存需求减少 90%,吞吐量提升 3.5 倍,特别适合边缘设备上的轻量级模型部署。Table 4 显示,在 1:12 比例下,当 Transformer 块位于中间层时,NLL 为 2.741;而将 Transformer 块移至前端时,NLL 上升至 2.770。
行业趋势与未来方向
当前,大型语言模型正从纯 Transformer 向混合架构迁移。越来越多的商业模型(如 Jamba、Zamba)和开源项目采用混合设计,表明这一趋势已成行业共识。
技术演进路径显示,混合架构正从简单模块拼接向精细化设计发展。未来可能的创新方向包括:动态混合(根据输入长度自动调整混合比例)、硬件协同设计(针对混合架构优化 GPU 内存访问模式),以及与更多先进计算原语的结合。
混合架构的未来与行业影响
混合架构研究揭示了三大关键发现:首先,通过互补归纳偏置,混合架构实现了质量与效率的双赢;其次,层内混合在质量上限上略胜一筹,达到 54.9% 的 few-shot 准确率,比层间混合高 0.9%;最后,位置策略比比例选择更为关键——Transformer 块必须置于模型中间位置才能发挥最佳效果。
对行业而言,混合架构正在成为新一代 LLM 的标准设计范式。这一转变不仅影响模型开发流程,还改变了硬件需求格局。缓存需求的显著降低使更多应用场景能够在现有硬件上高效运行,降低了部署门槛。
然而,这篇研究是具有当前局限性的,这份研究仅限于1B规模的模型,这些模型是在60B tokens上进行预训练的。由于单独的Mamba模型在大规模情况下常常表现出收益递减的情况,因此,验证这篇研究中的混合模型在更长时间的训练以及更大规模上的性能优势是否依然存在,是需要研究团队未来进行更多实践验证的。
此外,混合架构与更先进组件的兼容性也值得进一步探索:这篇研究结合了基础的Transformer和Mamba模块,而近期的模型已经开始采用更先进的变体……一个关键问题是,meta的设计洞见是否仍然适用于这些新型的混合架构,以及当这些组件结合时,各自的优势是否能够得以保留。
从当下的视角来看,混合架构的潜力远远超出了语言模型的范畴。在多模态领域,混合架构有望解决视频序列的tokenization问题,从而实现更高效的长视频理解。要实现超级智能,模型必须超越语言,通过视频模态来内化支配我们世界的物理定律。这种向多模态学习(例如,视频、音频)的转变,加剧了对能够支持tokenization-free 处理并克服长上下文瓶颈的架构的需求。
混合架构的兴起代表了 AI 模型设计思维的根本转变:单一技术难以解决复杂问题,多元化融合才是 AI 发展的必然趋势。这一理念不仅适用于语言模型,也将影响整个 AI 领域的架构设计哲学,推动技术向更高效、更智能的方向演进。


