开源

文本已死,视觉当立!Karpathy狂赞DeepSeek新模型,终结分词器时代
DeepSeek再次让全世界大吃一惊! 他们最新成果DeepSeek-OCR,从根本上改变了游戏规则——文本并非通用的输入。 反而,视觉将取而代之!

告别「偏科」,UniVid实现视频理解与生成一体化
在视频生成与理解的赛道上,常常见到分头发力的模型:有的专注做视频生成,有的专注做视频理解(如问答、分类、检索等)。 而最近,一个开源项目 UniVid,提出了一个「融合」方向:把理解 生成融为一体 —— 他们希望用一个统一的模型,兼顾「看懂视频」 「生成视频」的能力。 这就像把「看图识物」和「画图创作」两件事,交给同一个大脑去做:理解一段文字 理解已有视频内容 → 再「画」出新的、连贯的视频 —— 这在技术上挑战极大。

Nature点赞!哈佛MIT最新作:AI科学家时代来了
随着近期大模型和智能体的飞速发展,这条路径正在通向一种全新的阶段:「AI科学家」。 在AI赋能科研的前沿,我们正见证一个重要的里程碑:从证明AI智能体「能否」解决特定科学问题,转向思考如何让它「高效、可靠、规模化」地参与整个研究过程。 Nature近期发布的新闻解析, 报道了由哈佛大学Marinka Zitnik和高尚华团队与MIT发布的首款大规模工具开源框架ToolUniverse。

英伟达4段简短提示词,IOI夺金!开源模型也能征服最难编程竞赛
IOI(国际信息学奥林匹克)是全球中学生算法编程竞赛的最高殿堂,每年只有不到10%选手能拿到金牌。 比赛要求选手在两天内各5小时独立解决3道高难度算法题,全程断网、不能借助外部资料,每题最多允许50次提交尝试。 要拿金牌,既要有过硬的算法思维,又得策略得当、在有限提交内调优代码。

超越纯视觉模型!不改VLM标准架构,实现像素级深度预测
在当前多模态AI发展浪潮中,视觉语言模型(Vision Language Models, VLMs)因其能通过「看图 文字交互」处理多样任务而备受关注。 然而,尽管在语义理解、视觉问答、图像指令等任务上表现优异,它们在从 2D 图像理解 3D 空间结构方面仍显薄弱。 相比之下,纯视觉模型(pure vision models)在 绝对深度估计(metric depth estimation) 等三维理解任务上,凭借专门设计的网络结构与损失函数,早已达到了超越人类的精度。
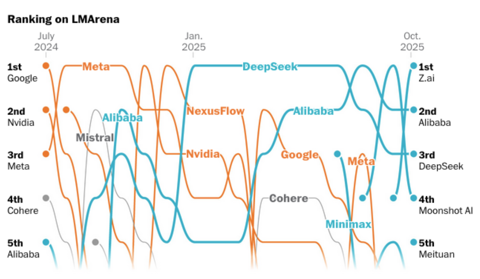
开源模型TOP5,被中国厂商包圆了
鱼羊 发自 凹非寺. 量子位 | 公众号 QbitAI开源大模型,进入中国时间。 10月,公开数据显示,来自中国的开源大模型已经牢牢占据榜单前五。

清华&巨人网络首创MoE多方言TTS框架,数据代码方法全开源
无论是中文的粤语、闽南话、吴语,还是欧洲的荷兰比尔茨语方言、法国奥克语,亦或是非洲和南美的地方语言,方言都承载着独特的音系与文化记忆,是人类语言多样性的重要组成部分。 然而,许多方言正在快速消失,语音技术如果不能覆盖这些语言,势必加剧数字鸿沟与文化失声。 在当今大模型引领的语音合成时代,通用 TTS 系统已展现出令人惊叹的能力,但方言 TTS 依然是相关从业者难以触及的「灰色地带」。
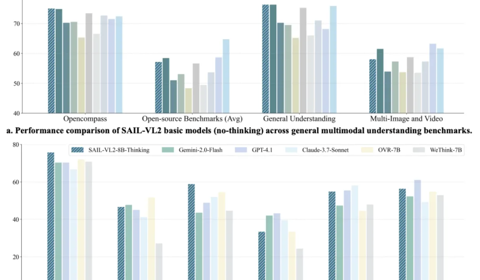
抖音&LV-NUS开源多模态新模,以小博大刷新SOTA,8B推理比肩GPT-4o
SAIL-VL2团队 投稿. 量子位 | 公众号 QbitAI2B模型在多个基准位列4B参数以下开源第一。 抖音SAIL团队与LV-NUS Lab联合推出的多模态大模型SAIL-VL2。
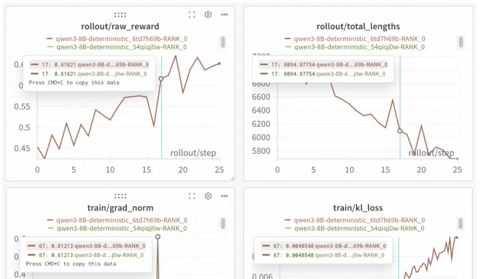
首个开源实现100%可复现的稳定RL训练框架来了!2次结果完全重合
开源框架实现100%可复现的稳定RL训练! 下图是基于Qwen3-8B进行的重复实验。 两次运行,一条曲线,实现了结果的完美重合,为需要高精度复现的实验场景提供了可靠保障。

刚刚,LeCun团队开源首款代码世界模型!能像程序员一样思考的LLM来了
就在今天,Meta官宣发布了一款名为代码世界模型(Code World Model, CWM)的LLM,探索如何使用世界模型改进AI代码生成性能。 Yann LeCun也亲自下场转发撑场子了。 CWM究竟有哪些创新点?

通义DeepResearch开源发布:首个匹敌OpenAI的全栈Web Agent
大家好,我是肆〇柒。 在AI飞速发展的今天,AI Agent正经历从简单对话机器人向自主智能体的重大转变。 就在上周,通义实验室(Tongyi Lab)开源了最新的研究成果——通义DeepResearch,并随开源发布了六篇论文,被社区戏称为“腹泻式发论文”。

Qwen开源版Banana来了!原生支持ControlNet
Qwen版Banana来了! 刚刚,Qwen推出了新图像编辑模型——Qwen-Image-Edit-2509。 不仅支持多图融合,提供“人物 人物”,“人物 商品”,“人物 场景” 等多种玩法,还增强了人物、商品、文字等单图一致性。

超越规模神话:WebSailor-V2 的数据-环境协同之道
大家好,我是肆〇柒。 本文要和大家分享的是来自阿里通义实验室(Tongyi Lab, Alibaba Group)的一项重磅研究成果——WebSailor-V2。 这项工作不仅刷新了开源Web智能体的性能上限,更关键的是,它揭示了一个被长期忽视的真相:决定Agent能力边界的,或许不是模型参数,而是数据质量与训练生态系统的构建方式。

阿里通义深夜炸场:全球首个端到端全模态 AI 模型 Qwen3-Omni 发布开源,文本、图像、音视频全统一
9 月 23 日消息,又是熟悉的深夜,阿里云今日发布并开源了全新的 Qwen3-Omni、Qwen3-TTS,以及对标谷歌 Nano Banana 图像编辑工具的 Qwen-Image-Edit-2509。 Qwen3-Omni 是业界首个原生端到端全模态 AI 模型,能够处理文本、图像、音频和视频多种类型的输入,并可通过文本与自然语音实时流式输出结果,解决了长期以来多模态模型需要在不同能力之间进行权衡取舍的难题。 Qwen3-Omni 是原生端到端的多语言全模态基础模型,其核心特性主要包括:跨模态最先进表现:通过早期以文本为核心的预训练和混合多模态训练,模型具备原生多模态能力。

阿里新开源提出建设性安全对齐方案,向“让用AI的人安全”新范式跃迁
正如牡蛎历经磨砺,在坚实的外壳内将沙砾孕育成一颗温润的珍珠。 AI也可以如此,不是一个只会紧紧封闭抵御风险的系统,而是一个有底线、有分寸、也有温度的伙伴。 阿里巴巴集团安全部联合清华大学、复旦大学、东南大学、新加坡南洋理工等高校,联合发布技术报告;其理念与最近OpenAI发布的GPT-5 System Card放在首位的“From Hard Refusals to Safe-Completions”理念不谋而合。

阿里王牌Agent横扫SOTA,全栈开源力压OpenAI!博士级难题一键搞定
阿里又双叒叕上大分了! 就在昨天,阿里旗下首个深度研究Agent模型——通义DeepResearch正式开源。 在多项权威基准上,通义DeepResearch狂飙SOTA,仅依靠30B参数(激活3B)就能大杀四方!

通义DeepResearch震撼发布!性能比肩OpenAI,模型、框架、方案完全开源
通义 DeepResearch 重磅发布,让 AI 从 “能聊天” 跃迁到 “会做研究”。 在多项权威 Deep Research benchmark 上取得 SOTA,综合能力对标并跑赢海外旗舰模型,同时实现模型、框架、方案全面开源,把深度研究的生产力真正带到每个人手里。 相比于海外的旗舰模型昂贵和限制的调用,通义 DeepResearch 团队做到了完全开源!

终结数据荒!智源开源首个Deep Research数据合成框架InfoSeek
近日,北京智源人工智能研究院(简称「智源研究院」)发布开源数据集InfoSeek,成为首个面向深度研究(Deep Research)场景的大规模开源数据集。 在这一工作中,智源研究团队揭示了深度研究问题与层级约束满足问题(Hierarchical Constraint Satisfaction Problem)之间的数学等价关系,并由此提出了基于「扩散-回溯」过程的数据合成方法,实现了深度研究训练数据的大规模自动扩增。 利用上述方法,研究团队总计合成了包含5万条训练样本的数据集InfoSeek,并据此训练出参数规模仅3B的智能体模型。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI绘画
大模型
AI新词
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
智能体
技术
Gemini
英伟达
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
代码
AI for Science
苹果
算法
腾讯
Agent
Claude
芯片
Stable Diffusion
具身智能
xAI
蛋白质
开发者
人形机器人
生成式
神经网络
机器学习
AI视频
3D
RAG
大语言模型
字节跳动
Sora
百度
研究
GPU
生成
工具
华为
AGI
计算
大型语言模型
AI设计
生成式AI
搜索
视频生成
亚马逊
AI模型
DeepMind
特斯拉
场景
深度学习
Transformer
架构
Copilot
MCP
编程
视觉