开源

谷歌nano banana正式上线:单图成本不到3毛钱,比OpenAI便宜95%
昨晚,神秘且强大的图像生成与编辑模型 nano banana 终于正式显露真身。 没有意外,它果然来自谷歌,并且也获得了一个正式但无趣的名字:gemini-2.5-flash-image-preview。 据介绍,该模型具有「SOTA 的图像生成与编辑能力、惊人的角色一致性以及闪电般的速度」。

最新智能体自动操作手机电脑,10个榜单开源SOTA全拿下|通义实验室
能自动操作手机、电脑的智能体新SOTA来了。 通义实验室推出Mobile-Agent-v3智能体框架,在手机端和电脑端的多个核心榜单上均取得开源最佳。 它不仅能做交互界面的问答、描述、定位,也能一条指令独立完成复杂任务,甚至可以在多智能体框架中无缝扮演不同角色。

马斯克掀桌子了,最强开源大模型诞生!Grok-2近万亿参数性能首曝
什么? 马斯克终于开源了Grok-2! 一大早,xAI正式官宣,向所有人开源Grok-2!

刚刚,马斯克开源Grok 2.5:中国公司才是xAI最大对手
就在刚刚,马斯克一手开源动作,引发了大伙儿的高度关注——xAI现在正式开源Grok 2.5,Grok 3将在半年后开源。 其实早在本月初的时候,马斯克就公开表示过:是时候开源Grok了,将会在下周。 虽然开源的时间已经超过了他说的节点,但也正如网友所说:迟到总比没有的好。

比GPT-5还准?AIME25飙到99.9%刷屏,开源模型首次!
如何让模型在思考时更聪明、更高效,还能对答案有把握? 最近,Meta AI与加州大学圣地亚哥分校的研究团队给出了一个令人振奋的答案——Deep Think with Confidence(DeepConf),让模型自信的深度思考。 论文地址::「置信度筛选」,不仅让模型在国际顶尖数学竞赛AIME 2025上拿下了高达99.9%的正确率。

AIBrix v0.4.0 发布:P/D 解耦与专家并行支持、KVCache v1 连接器、KV 事件同步与多引擎支持
AIBrix项目作为大模型推理的可扩展且高性价比的技术方案,项目于2025 年 2 月 21 日正式开源,并通过vLLM 官方博客官宣,为 vLLM 推理引擎提供可扩展且高性价比的控制面。 开源 72 小时内,AIBrix 收获的 GitHub Star 数已超 1K,96 小时突破 2K;开源一周左右,AIBrix 保持在 GitHub trending[1]榜第一的位置。 目前 GitHub Star 已超过 4K,贡献者超过 70 人。

DeepSeek开源新基础模型,但不是V4,而是V3.1-Base
昨晚,深度求索在用户群里宣布「DeepSeek 线上模型版本已升级至 V3.1,上下文长度拓展至 128k」并更新了 UI (去掉了 DeepThink 旁的 R1 标示)之后,在 Hugging Face 发布了一款新模型 DeepSeek-V3.1-Base。 模型地址:,该模型是 DeepSeek-V3 系列最新的基础模型。 至于为什么命名为 V3.1,而不是像之前以前命名为 V3 带四位日期数字的形式(如 V3-0324),尽管社区有诸多猜测,但深度求索官方尚未给出明确说明 —— 和该公司之前的操作一样,这一次同样是模型先行,说明和宣传还在后面。

英伟达开源9B参数小模型,比Qwen3快6倍
小模型也开始卷起来了! 在麻省理工学院衍生公司Liquid AI发布了一款小到可以装在智能手表上的新AI视觉模型,以及谷歌发布了一款可以在智能手机上运行的小型模型之后,英伟达也加入了这场浪潮,推出了自己的新型小型语言模型(SLM):Nemotron Nano v2。 这款9B的“小”模型在复杂推理基准测试上的准确率与Qwen3-8B相当或更高,速度快6倍。
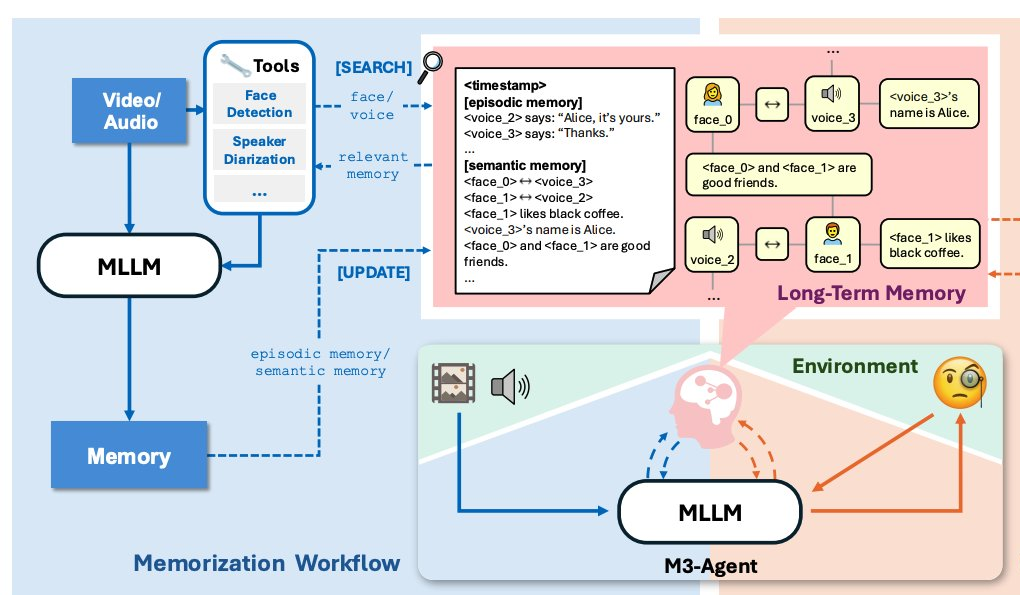
字节Seed开源长线记忆多模态Agent,像人一样能听会看
不圆 发自 凹非寺. 量子位 | 公众号 QbitAI字节Seed发布全新多模态智能体框架——M3-Agent。 像人类一样能听会看、具备长期记忆,并且免费开源!

Meta刚刚开源DINOv3,横扫60+任务,无标注封神!
今天凌晨,全球社交、科技巨头Meta开源了,最新视觉大模型DINOv3。 DINOv3的主要创新使用了自我监督学习,无需标注数据就能大幅度降低训练所需要的时间和算力资源。 并且与前一代相比,DINOv3的训练数据大12倍扩大至17亿张图像以及大7倍的70亿参数。

OpenAI没开源的gpt-oss基础模型,他去掉强化学习逆转出来了
前些天,OpenAI 少见地 Open 了一回,发布了两个推理模型 gpt-oss-120b 和 gpt-oss-20b。 但是,这两个模型都是推理模型,OpenAI 并未发布未经强化学习的预训练版本 gpt-oss 基础模型。 然而,发布非推理的基础模型一直都是 AI 开源 / 开放权重社区的常见做法,DeepSeek、Qwen 和 Mistral 等知名开放模型皆如此。

机器人上下文协议首次开源:阿里达摩院一口气放出具身智能「三大件」
8 月 11 日,在世界机器人大会上,阿里达摩院宣布开源自研的 VLA 模型 RynnVLA-001-7B、世界理解模型 RynnEC、以及机器人上下文协议 RynnRCP ,推动数据、模型和机器人的兼容适配,打通具身智能开发全流程。 开源链接:机器人上下文协议 RynnRCP - 语言 - 动作模型 RynnVLA-001 RynnEC ,但仍面临开发流程碎片化,数据、模型与机器人本体适配难等重大挑战。 达摩院将 MCP(Model Context Protocol)理念引入具身智能,首次提出并开源了 RCP(Robotics Context Protocol)协议以推动不同的数据、模型与本体之间的对接适配。

智谱终于发布GLM-4.5技术报告,从预训练到后训练,细节大公开
就在上个月底,智谱放出重磅炸弹 —— 开源新一代旗舰模型 GLM-4.5 以及轻量版 GLM-4.5-Air。 其不仅首次突破性地在单个模型中实现了推理、编码和智能体能力的原生融合,还在 12 项全球公认的硬核测试中取得了全球第三的综合成绩。 这个成绩在所有国产模型和开源模型中均排名第一!
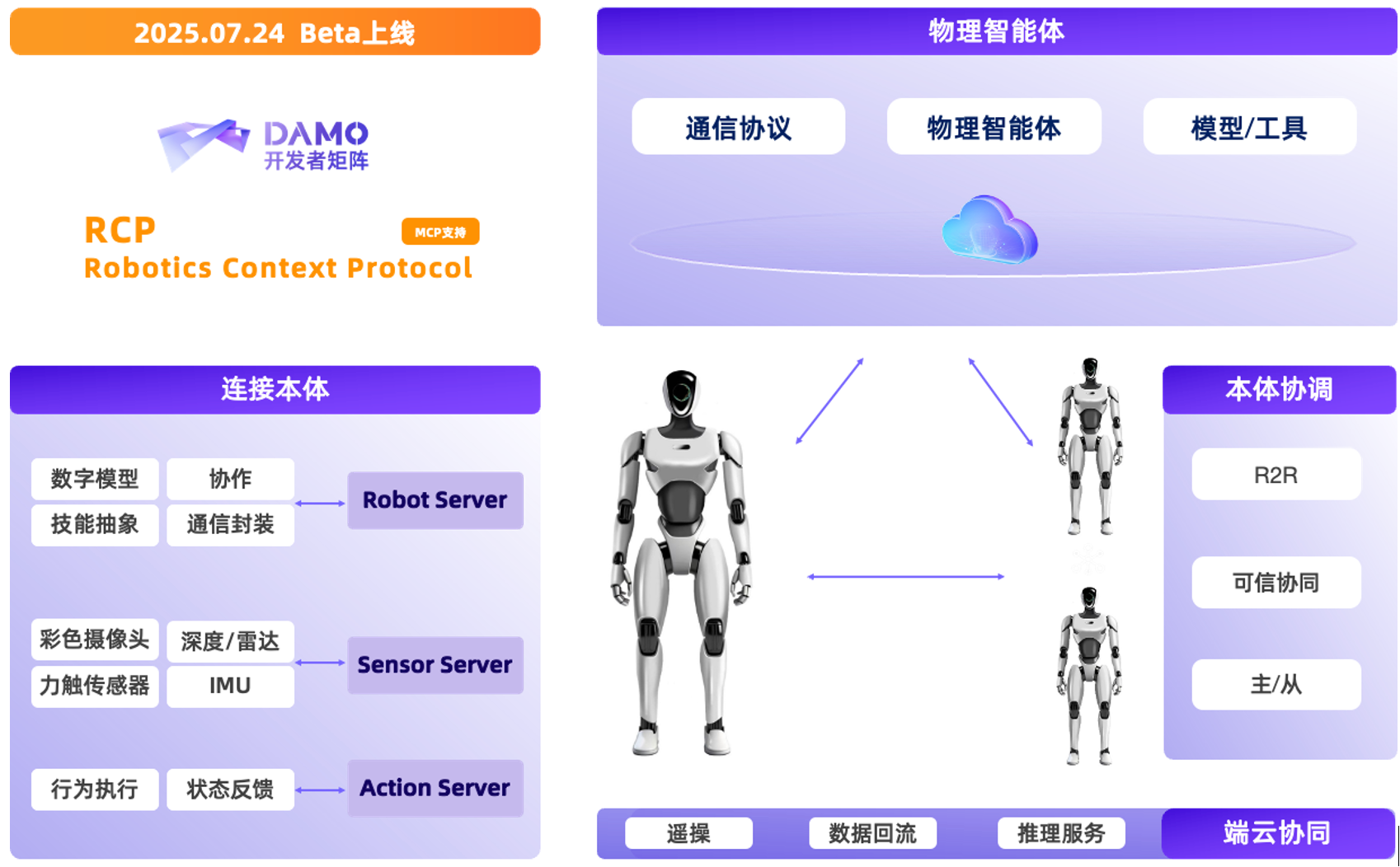
达摩院开源具身智能“三大件”,机器人上下文协议首次开源
8月11日消息,在世界机器人大会上,阿里达摩院宣布开源自研的 VLA 模型RynnVLA-001-7B、世界理解模型RynnEC、以及机器人上下文协议RynnRCP ,推动数据、模型和机器人的兼容适配,打通具身智能开发全流程。 具身智能领域飞速发展,但仍面临开发流程碎片化,数据、模型与机器人本体适配难等重大挑战。 达摩院将MCP(Model Context Protocol)理念引入具身智能,首次提出并开源了RCP(Robotics Context Protocol)协议以推动不同的数据、模型与本体之间的对接适配。

刚刚,小红书开源了多模态大模型dots.vlm1,性能直追SOTA!
最近的AI圈只能说是神仙打架,太卷了。 OpenAI终于发了开源模型,Claude从Opus 4升级到4.1,谷歌推出生成游戏世界的Genie 3引发社区热议。 国产模型这边,就在前几天,HuggingFace上排在最前面的10个开源模型还都来自国内。

OpenAI重磅发布gpt-oss系列开源大模型:媲美 GPT-4o
不论你是独立开发者、企业还是研究机构,现在都可以免费拥有一款与 GPT-4o 接近实力的语言模型。 开源但不“阉割”:媲美 GPT-4o,运行成本极低OpenAI 在这次发布中非常有诚意:gpt-oss-120b:在核心推理任务上已接近 GPT-4o-mini,支持 128k 上下文,单卡 80GB GPU 可跑。 gpt-oss-20b:性能对标 GPT-3.5(o3-mini),仅需 16GB 显存,可部署于消费级设备、本地推理、离线使用等场景。
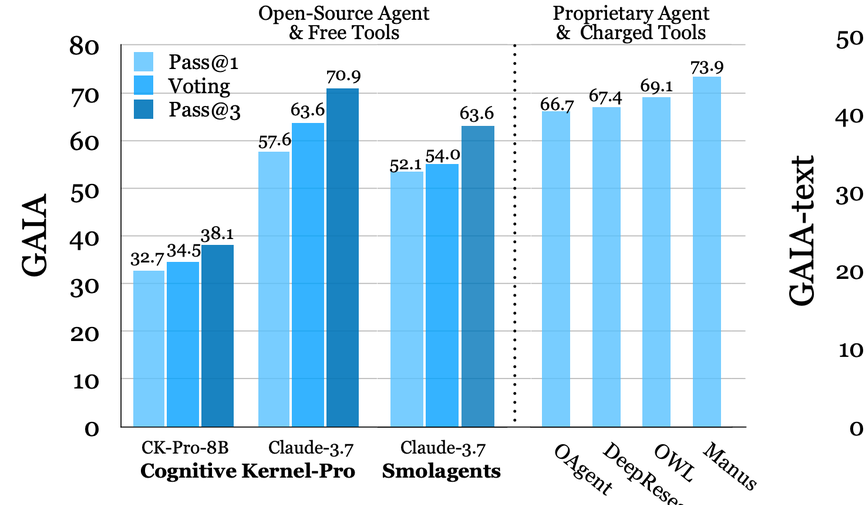
腾讯AI Lab开源可复现的深度研究智能体,最大限度降低外部依赖
深度研究智能体(Deep Research Agents)凭借大语言模型(LLM)和视觉-语言模型(VLM)的强大能力,正在重塑知识发现与问题解决的范式。 然而,现有开源智能体框架多依赖付费工具,限制了可复现性和普适性。 腾讯AI Lab全新推出的Cognitive Kernel-Pro,一款全开源、多模块、层次化的智能体框架,为深度研究智能体的开发与训练提供了突破性解决方案。

阿里刚刚开源Qwen-Image,免费版GPT-4o吉卜力,中文最好模型
今天凌晨,阿里巴巴达摩院开源了最新文生图模型Qwen-Image。 Qwen-Image是一个200亿参数的MMDiT模型,可生成写实、动漫、赛博朋克、科幻、极简、复古、超现实、水墨等几十种类型的图片,支持图片的风格迁移、增删改、细节增强、文字编辑,人物姿态调整等常规操作。 Qwen-Image也可以生成OpenAI的GPT-4o爆火全网的吉卜力风格图片。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI绘画
大模型
AI新词
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
智能体
技术
Gemini
英伟达
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
代码
AI for Science
苹果
算法
腾讯
Agent
Claude
芯片
Stable Diffusion
具身智能
xAI
蛋白质
开发者
人形机器人
生成式
神经网络
机器学习
AI视频
3D
RAG
大语言模型
字节跳动
Sora
百度
研究
GPU
生成
工具
华为
AGI
计算
大型语言模型
AI设计
生成式AI
搜索
视频生成
亚马逊
AI模型
DeepMind
特斯拉
场景
深度学习
Transformer
架构
Copilot
MCP
编程
视觉