开源模型之王易主,不过还是国产模型!
行业评测里,它在 Artificial Analysis 榜单综合进入全球前五、开源模型第一梯队,重点在编程、工具使用、深度搜索这些 Agent 核心能力上表现亮眼。
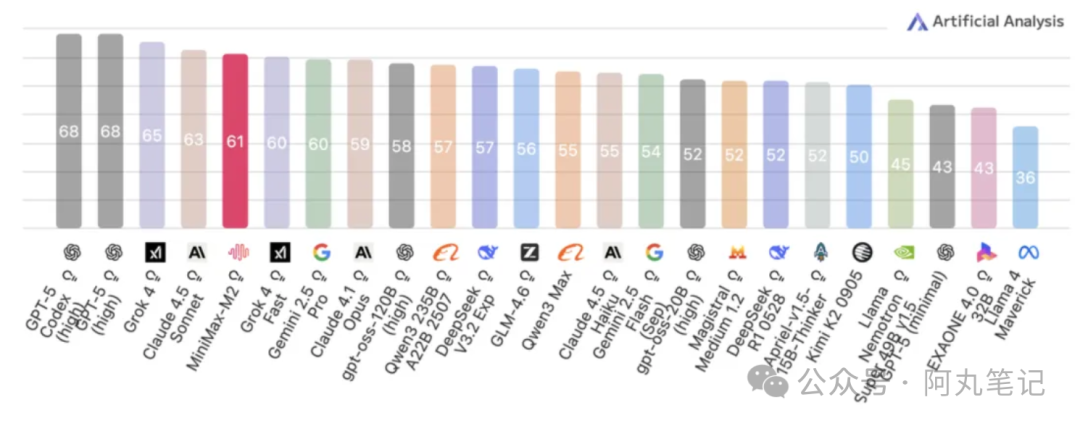
MiniMax 刚发布并开源M2模型,它采用稀疏 MoE 架构,总参数 230B,但推理时仅激活约 10B,这意味着在保持高性能的同时,把算力开销和延迟压下来了。
更具传播性的点是价格。多家报道给到的 API 定价区间,是“每百万输入 Token 约 $0.3、输出约 $1.2”,折算下来大约是 Claude Sonnet 4.5 的 8% 左右。即便考虑到不同渠道的信息误差,这个数量级的性价比,已经足够让中小团队认真评估“把 Agent 主力模型切换到 M2”的可能性。
为什么这次的“参数大,但用得省”成立?
简单说,MoE 的思路是“按需激活”。
总参数可以很大,但每次推理只唤醒少数专家子网络。对开发者而言,更像是“平时两三个高手就够上阵,只有难题才叫更多人”。
- 速度更快:少激活=少计算;
- 成本更低:同等任务减少算力账单;
- 性能不掉队:专家路由把难点交给擅长的子网络。
对开发者/团队的直接影响
我特意对照了几类常见工作流,感受比较直观:
• 全栈开发 Agent - 需求理解 → 方案设计 → 代码生成 → 单测 → 修复回合;M2 在工具调用/检索/长思考链条里延迟更友好,成本曲线明显更平。
• 深度研究 Agent - 多源检索 → 事实核验 → 摘要对照;在多轮检索+比对的场景里,性价比优势放大。
• 生产级 RAG - 长文档切块、思维链、工具混合;MoE 的“按需”策略有助于稳定复杂工具链的输出质量。
和“老牌选手”的对比怎么做?
如果你手里已经在用 GPT-4.1/4o、Claude Sonnet 4.5 之类的闭源主力,可以这样做一次“盲测迁移评估”:
• 挑选3条关键链路:编码生成/回归修复、工具检索、多表格数据分析。
• 统一数据与提示:相同测试集,相同系统提示,控制变量。
• 记录三种指标:端到端时延、总 Token 花费、一次成功率(无需人类介入的完成比例)。
• 算 TCO 而不是单价:把失败重试、人工干预、观测成本都算进去,性价比差距会更清晰。
注:价格/榜单等信息引自公开报道(如 36氪、新浪财经、DataLearner 等),不同渠道存在出入的可能,建议以官方公告与实际 API 计费为准。
可以怎么上手验证?
很简单的三步:
• 先跑公共基准的子集:例如 HumanEval/MBPP 的自定义小样,验证编码与测试修复能力。
• 接入真实工具链:把检索、结构化解析、代码执行接起来,看端到端效果。
• 逐步替换:先替换长尾任务和低风险链路,再评估是否把主链路切到 M2。
最后一个主观判断:M2 的卖点不是“参数更大”,而是在“Agent 真实工作流里更划算”。
如果你正被 API 账单和延迟拖住了迭代节奏,这一代 MoE 路线值得试一试。


