
大家好,我是肆〇柒。AI 圈的进化速度之快,已是不争的事实。去年,MCP(模型上下文协议)发布,随后 AI Coding 赛道愈发热闹,Cursor、Cline、Devin、MGX 等产品层出不穷。春节前夕,各模型厂商扎堆发布新模型,DeepSeek-R1 的问世更是让全球为之一震。近期,通用智能体 Manus 的发布又引发了不小的热议。类似的消息数不胜数,这都是近三四个月发生的事情,信息饱和度极高。用群友的一句话来形容再恰当不过:“物理方一日,智能已千年”。
在此,有个显而易见的结论是:一个协议能否成为标准,取决于共识。比如W3C HTTP协议,能成为业界标准,原因就是在行业协会牵头下有广泛共识,并见真实落地和深度的用户渗透率。所以,MCP能不能成为协议标准,取决于大家对它的共识程度,而这个共识,不仅仅来自于创业公司,开发者群体,还要来自于商业巨头,甚至是政体。
说到共识,我曾在社群里聊到过,行业巨头通常不会给自己找一个能扼住自己咽喉的上游。那么如何看待国内这两个头部地图应用的动作呢?
原因在于它们本身具有工具属性,且有开放平台API为开发者提供服务。所以多一个MCP,只是从开放平台角度多了一个智能应用的用户渠道,对它们自身市场和竞争格局是有益的。况且,如果老二先入,老大不跟,就可能错失市场,所以我们才看到百度地图和高德地图相继宣布开放MCP Server。由此,也许可以得到一个观点:一个具有行业地位,但没有绝对垄断性领先优势的平台或应用,要特别警惕在AI时代被竞争对手通过AI Agent等智能形态的应用弯道超越。
AI Agent 战略?
对于Agent战略,工具类应用,容易跟进,但平台类的却要自己想清楚,因为它涉及到产业生态。多数2C服务类平台,应该不会情愿工具化自己,因为这会使整个业务模式改变,用户体验发生剧变,流量走向也会完全不一样。比如电商,想象一下,如果引入Agent电商,业务模式将发生天翻地覆的变化。在这样的平台场景下,如果AI Agent渗透,就要看Agent的代理当方向是什么,它代理了谁——是平台?还是个人?
- 如果代理的是平台,Agent可以实时感知用户需求,为客服提供更精准的购买服务支持;
- 如果代理的是个人,Agent可以作为个人的购物助手,在成本预算、功能性要求的前提下,对商品进行比价、功能性分析、社交评价洞察,从而为用户实现购买评估。
以上两点只是非常粗糙的假想,只为给大家提供一个思考的种子。我们可以看到,在这样的场景下,无论AI Agent代理的是个人还是平台,都具有非常大的商业想象空间。
AI Agent 代理平台
如果Agent代理的是平台,其主要作用是作为平台与用户之间的中介,实时感知用户需求,为平台的客服、商品推荐、流量分配等提供更精准的支持。也许可以是:
- 客服支持Agent代理平台时,能实时感知用户需求,提前为客服提供精准信息。比如用户浏览商品时,Agent可预测其可能的咨询内容(如商品详情、尺码、退换货政策等),提前推送给客服,让客服快速响应,提升服务效率和用户满意度。
- 商品推荐与流量分配Agent可分析用户实时行为和偏好,为平台推荐系统提供精准用户画像,优化商品推荐策略。平台据此将用户感兴趣的商品精准展示,提高曝光率和转化率。同时,Agent还能优化流量分配,引导流量到更符合用户需求的商品和商家页面,提升平台运营效率。
- 广告投放与营销Agent为平台广告投放提供精准依据,分析用户实时需求和兴趣,将相关广告精准推送给用户,提高点击率和转化率。此外,Agent还能根据用户行为数据,为平台制定个性化营销策略,如优惠券发放、限时折扣推荐等,吸引更多用户购买商品。
- 平台运营与管理Agent作为平台的智能助手,实时监测流量、用户活跃度、商品库存等信息,为平台提供运营建议。如发现商品库存不足提醒补货,发现页面用户流失率高则分析原因并提优化建议,还能协助平台进行数据分析和报告生成,为决策提供支持。
- 平台与商家合作Agent帮助平台管理与商家的合作,提供商家销售数据、用户评价、库存等信息,评估商家表现和合作价值。同时,为商家提供平台运营规则、用户需求等信息,帮助其适应平台环境、提高销售业绩,使平台与商家合作更顺畅高效。
所以,AI Agent如果代理的方向是平台,主要可以通过实时感知用户需求,为平台的运营、客服、商品推荐、广告投放等提供更精准的支持,从而提升平台的整体效率和用户体验。
AI Agent 代理个人
从平台的角度来看,引入Agent战略,尤其是当Agent代理的是个人时,用户的自主性会大大增强。用户不再只是被动地接受平台推送的商品信息,而是通过Agent主动筛选和分析,找到最适合自己的产品。这可能会导致平台原有的流量分配机制失效,那些原本依靠广告投放和平台推荐获得曝光的商家,可能会发现自己的产品难以进入用户的视野,除非它们真的具有足够的竞争力。
对于广告业务而言,这无疑是一个巨大的挑战。广告的精准投放一直是平台广告业务的核心优势,但如果Agent能够根据用户的个性化需求进行商品筛选,那么广告的展示机会可能会被大幅压缩。平台需要重新思考广告的投放策略,如何在Agent的过滤机制下,让广告能够真正触达有需求的用户,而不是被一概屏蔽。这可能需要平台与广告主共同探索新的合作模式,比如基于Agent反馈的精准广告推荐,或者开发新的广告产品,以适应这种新的用户交互方式。
新商品和新商家的曝光问题也尤为关键。在一个成熟的电商平台上,新商品和新商家往往需要借助平台的推荐系统来获得初始流量,从而逐渐积累口碑和销量。但如果Agent主要依据历史数据和用户评价来筛选商品,新商品和新商家可能会因为缺乏足够的数据支持而被边缘化。这不仅会影响平台的创新活力,也可能导致平台的商品种类逐渐固化。平台需要找到一种平衡,既要利用Agent提升用户体验,又要为新商品和新商家提供公平的曝光机会,比如通过设置专门的新品推荐区域,或者为新商家提供一定的初始流量扶持。
用户购买决策的变化也可能会对平台的商业模式产生深远影响。如果用户越来越依赖Agent进行购买评估,那么平台的角色可能会从一个商品展示和交易的场所,逐渐转变为一个提供决策支持和服务的平台。这意味着平台需要更加注重数据的准确性和可靠性,以及Agent的智能水平和服务质量。同时,平台也需要重新思考如何与用户建立更深层次的连接,因为用户对商品的购买决策不再仅仅基于平台的推荐,而是基于Agent提供的综合评估。
甚至,想象的再大胆一点,平台还在吗?Agent是否有可能撇开现有供应链,通过厂商提供的Agent协议来直连厂商Agent?通过类似ANP这样的协议,实现AI之间的协作与对话。
想清楚了?
那么,我们真的考虑清楚了吗?如果平台仓促实施Agent战略,会对平台生态产生怎样的冲击?广告业务该如何开展?新商品、新商家如何获得曝光机会?用户是否只能购买到口碑良好的老品牌产品?品牌创新、产品创新怎么办?如果真的按照这种方式落地,2B或2C的模式是否还能继续存在?用群友的话来说,是不是只剩下“to human”和“to AI”的模式了,“to B”和“to C”不再有明确的界限了?
当社区群里讨论“Agent电商”时,一位伙伴的发言让我心中一震:“说不定电商行业正在经历数字版的《三体》危机——不知道什么时候会被二向箔降维打击。”这种思考源于一个根本矛盾:传统电商遵循的是“人找货”的搜索逻辑,而AI Agent电商则是“意图即服务”的穿透逻辑。试想这样一个场景:用户说“想给喜欢露营的男友选个实用又不失格调的生日礼物”,AI Agent也许可以同时调用电商供应链数据、小红书的场景化推荐、闲鱼的保值率分析,最终生成包含采购建议、包装方案、贺卡文案的完整解决方案。
这无疑直接动摇了平台经济的根基——当交易发生在Agent之间,流量入口、广告模式、佣金体系等都将被重构。所以,另外一个伙伴感叹道:“既怕Agent不来,又怕Agent乱来。”
这是一个天翻地覆的变化,其中蕴含的故事和脑洞非常多。然而,我们不再对可能的场景问题展开更宽泛的探讨。但从以上推演来看,或许大家可以理解为什么一些平台型巨头还没有迅速行动。在我看来,并非他们看不到其中的机遇和挑战,而是需要思考的问题实在太多,这件事并不简单,必须谨慎思考,否则可能会引发一系列不可控的连锁反应,甚至对整个平台,乃至对行业的长期发展造成负面影响。
子弹再飞一会,或者等待鲶鱼到来。
「这些商业动作背后,暗含着AI时代更底层的技术逻辑:当MCP这类协议试图连接万物时,必须存在一个能统筹全局的「调度中枢」。这就如同智能手机普及需要iOS/Android作为支撑,AI智能体生态的繁荣,同样需要属于这个时代的『操作系统』——而这正是Agent与Workflow架构正在扮演的角色,AI 时代的智能生态基座。」
AI时代的智能生态基座
关于Agent前两天有一篇文章,被社区伙伴转发——
“万字探讨Agent发展真方向:模型即产品,Agent的未来要靠模型而不是Workflow”——发表于《机智流》链接:https://mp.weixin.qq.com/s/em5UGArBECNa9Tt6GN1wqQ
上面这篇文章的核心观点是:
未来AI智能体的发展方向将依赖于模型本身,而非工作流(Workflow)。观点提出者认为,通过强化学习(RL)与推理(Reasoning)结合的模型,能够自主掌控任务执行全过程,包括动态规划搜索策略和主动调整工具使用等,从而颠覆目前的应用层生态。文章强调“模型即产品”,并指出未来闭源AI大模型提供商将停止提供API服务,转而直接提供模型作为产品。
模型即产品?即一切?
坦白讲,这个观点不可谓不激进。甚至从观点提出者的职业背景来看,观点中有事实,但也极具阵营色彩。
的确,从目前的一些现象来观察,模型的进化非常的迅速,从中美最具代表性的推理模型来看,GPT-o1发布于9月中旬,DeepSeek-R1则发布于今年的1月20日,相差4个月。而DeepSeek-R1的出现,其实是全民使用reason model的时刻,因为它被普及了。
这代表了什么?从细节应用的角度,通用模型比如GPT-4o,或者DeepSeek-V3,当这类模型需要做文本推理的时候,需要用到CoT结构的Prompt来实现;而诸如DeepSeek-R1这样的Reason model,并不需要CoT技巧,你会说话就可以,有问题直接问,模型通过训练以后已经实现了自主思维链的推理。
所以,这可以有一个感知,即:软件吞噬世界,模型吞噬软件。
技术演进的底层逻辑
似乎,模型正在吞噬上层应用。但,模型在进化的同时,Agent、Workflow架构也在进化。如果从技术演进的底层逻辑稍作拆解,或许可以总结如下:
1. 工具价值
“过渡形态”与“生态基座”存在本质区别,Workflow这种编排形式并非过渡形态(人类社会至今仍未淘汰工作流、工序的概念)。应这样看待:类似Dify、Coze的工具并非拐杖,而是AI时代的Kubernetes。回顾AWS发展史,当EC2计算力足够强大时,人们反而更需要容器编排系统。大模型越强大,工作流引擎的价值就越凸显,因为其需解决复杂任务的资源调度问题。这正如CPU越强大越需要操作系统,大模型越强大,跨模型协作就越需要工作流编排。所以即使未来Dify、Coze不复存在,也应有其他组织拓扑形式来整合AI能力(想想function calling,若无程序向模型返回调用结果,模型将一无所知,这其实是一种简单的交互协作)。
2. 智能进化的一点理解
GPT-4的token上下文窗口从4k扩展到128k,但人类仍在使用Notion、飞书。原因在于认知科学告诉我们,智能体需分层处理信息。工作流本质上类似于神经网络的“外置缓存”,这是进化的必然,而非技术妥协。
3. 工程化规律
如今,几乎所有的技术革命都遵循“原始能力→抽象工具→垂直场景”的路径。例如,目前的Prompt Engineering虽原始,但未来或许会出现“工作流架构师”这一新工种。就像移动互联网初期人人做APP,如今则需要Flutter这样的跨平台方案,类似Dify、Coze的工具使用者,也在为AI时代的开发生态构建护城河。
生态基座?AIOS?
基于以上分析,我们可以看到:
- 工作流的价值,绝不仅仅是作为完成任务的工具,它更像是AI生态的基座,支撑着整个智能体的运行。没有工作流的协调,大模型就像强大的单兵作战单位,缺乏统一的指挥和调度,难以形成合力。
- 工作流的存在,使得智能体能够在复杂的任务中灵活调度资源,动态调整策略,从而更高效、稳健地完成任务。
- 工作流有其独特的生态位,也许它正在向着AI时代的Windows进化。OpenAI等大厂已在发布Workflow Builder,这不仅是技术趋势的体现,更是生态卡位战的重要一步。
我们也许可以将模型视为“大脑”,Agent视为“肢体”,两者应该是协同进化的整体。大模型的强大会提升Agent的能力天花板,但工作流、智能体拓扑的存在是智能体协作的需求。就像计算机的发展历程一样,从早期的大型机到个人电脑,再到云计算,每个阶段都需要操作系统来协调硬件和软件资源。在AI时代,工作流、智能体拓扑就是那个不可或缺的“操作系统”,它不仅协调着不同模型之间的协作,还为智能体提供了与现实世界交互的接口。
所以,由于AI强大模型的存在,模型上层的智能体框架、工作流框架等应用层尽管很薄,但它是“四肢”;模型很强,因为它是“大脑”。如果泛概念的来看智能体,应该是Model+Agent,而ANP、MCP结合泛化的智能体(Model+Agent)则是AI Society。
「但这样的『操作系统』能否真正运转,最终取决于『计算引擎』的效能——就像Windows的流畅度依赖CPU性能,Agent架构的实用性必然受制于模型的核心能力。当我们为Agent的生态愿景兴奋时,一个更根本的问题浮现:当前模型的推理能力,真的足以支撑这场智能革命吗?」
既然,上面提到了关于增强模型能力的话题,那我们就再多聊聊关于模型能力。
模型能力:“知识”与“方法”的双重挑战
近期,有一篇文章,是关于斯坦福大学的研究
“为什么Qwen能自我改进推理,Llama却不行?斯坦福找到了原理”——发表于《机器之心》链接:https://mp.weixin.qq.com/s/OvS61OrDp6rB-R5ELg48Aw
上面这篇文章的核心阐述的是:
斯坦福大学的研究揭示了Qwen和Llama在自我改进推理能力上的差异。Qwen表现出更强的自我改进能力,而Llama则提升有限。研究发现,Qwen自然地表现出关键的认知行为,如验证(系统错误检查)、回溯(放弃失败的方法)、子目标设定(将问题分解为可管理的步骤)和逆向思考(从期望结果推理到初始输入),而Llama缺乏这些行为。这些行为是有效利用额外计算资源和时间进行自我改进的基础。通过有针对性的干预,如用包含这些行为的人工合成推理轨迹引导Llama,或调整预训练数据以强调这些行为,可以显著提升Llama的自我改进能力。这表明,模型的初始推理行为与其自我改进能力密切相关,认知行为的存在比结果的正确性更重要。
我之所以会关注到这篇文章,1.是因为社区伙伴的推荐。2.是因为它与我对Qwen模型的认知相符合。
Dense 模型瓶颈了?
在去年 Qwen2.5 发布以后,为了应用的需要,我特意在本地私有化部署,跑了Qwen2和Qwen2.5的7B模型的基准评测。见下表。
Benchmark | Qw2-7B | Qw2.5-7B | Recovery |
Overall | 63.09 | 67.60 | 107.15% |
Exam | 72.38 | 72.38 | 100.00% |
Language | 54.25 | 53.97 | 99.49% |
Knowledge | 42.92 | 44.95 | 104.74% |
Understanding | 70.52 | 71.18 | 100.94% |
Coding | 77.44 | 83.54 | 107.88% |
Reasoning | 66.99 | 72.46 | 108.17% |
Instruct_Follow | 57.12 | 74.73 | 132.82% |
--------- 学科 Exam ------------------ | |||
ceval | 81.60 | 78.52 | 96.23% |
agieval | 56.27 | 58.01 | 103.09% |
mmlu | 70.87 | 74.19 | 104.68% |
cmmlu | 80.77 | 78.78 | 97.54% |
--------- 语言 Language -------------- | |||
WiC | 56.90 | 55.8 | 98.07% |
WSC | 64.42 | 70.19 | 108.96% |
afqmc-dev | 71.39 | 70.64 | 98.95% |
tydiqa-goldp | 24.28 | 19.26 | 79.32% |
--------- 知识 Knowledge ------------- | |||
BoolQ | 85.75 | 84.92 | 99.03% |
GPQA_diamond | 21.21 | 31.82 | 150.02% |
nq | 21.80 | 18.12 | 83.12% |
--------- 理解 Understanding --------- | |||
C3 | 92.16 | 91.51 | 99.29% |
race-middle | 89.83 | 91.09 | 101.40% |
race-high | 86.96 | 86.62 | 99.61% |
lcsts | 13.13 | 15.51 | 118.13% |
--------- 代码 Coding ---------------- | |||
openai_humaneval | 77.44 | 83.54 | 107.88% |
--------- 推理 Reasoning ------------- | |||
ocnli | 57.22 | 54.81 | 95.79% |
COPA | 99.00 | 96 | 96.97% |
math | 29.68 | 54.12 | 182.35% |
gsm8k(0-shot-CoT) | 83.70 | 87.26 | 104.25% |
bbh | 65.36 | 70.12 | 107.28% |
--------- 指令跟随 Instruct Follow ---- | |||
IFEval(Prompt-level-strict-accuracy) | 52.13 | 70.79 | 135.80% |
IFEval(Inst-level-strict-accuracy) | 62.11 | 78.66 | 126.65% |
以上Benchmark表格,不用太关注细节指标的含义,我点出几点来看即可。
从整体来看,Qwen2.5的提升似乎只有7.15%,并不算高。然而,若深入分析细节基准指标,就会发现千问团队对
- 指令跟随(132%)
- 高难度理解(118%)
- 高阶知识(如博士知识,150%)
- 数学(182%)
等方面进行了非常有针对性的强化训练。因此,如果仅从平均整体角度来衡量,提升幅度看似不高。但若对用户经常使用的能力进行加权计算,那么提升还是相当可观的。
根据千问开源模型的技术报告,Qwen2.5的训练数据是Qwen2训练数据的2倍。尽管训练数据量是上一版本的2倍,但Qwen2.5均值能力的提升并没有达到相应的倍率增长,这可能反映出了瓶颈问题。不过,由于用户常用单项能力得到了增强,所以从落地使用体感上,Qwen2.5体验不弱,这也体现了在训练过程中数据配方的博弈与取舍。虽然这是7B模型与上一版本的对比,但因为数据同源,所以可以基本预测Dense模型72B的能力。
模型因果推理的基础是什么?
让我们重新聚焦于这篇文章的核心主题——《为什么Qwen能自我改进推理,而Llama却做不到?》。在之前提到的实测Benchmark中,我们可以着重关注一个关键指标——Math。这一指标对于衡量模型的因果推理能力有着至关重要的意义。
当时在社群里,我提出了一种观点:Qwen在因果推理方面表现得比Llama出色,或许是因为它在推理知识储备上本身就优于Llama。然而,不同的Benchmark脚本即便评测的是相同的指标,也可能会因为Prompt存在差异,从而导致最终的数据结果出现不一致的情况。鉴于此,为了确保测评结果的准确性,有小伙伴专门找来了第三方的Benchmark对比表格,以此来保障在相同条件下进行测评对比,具体情况如下:
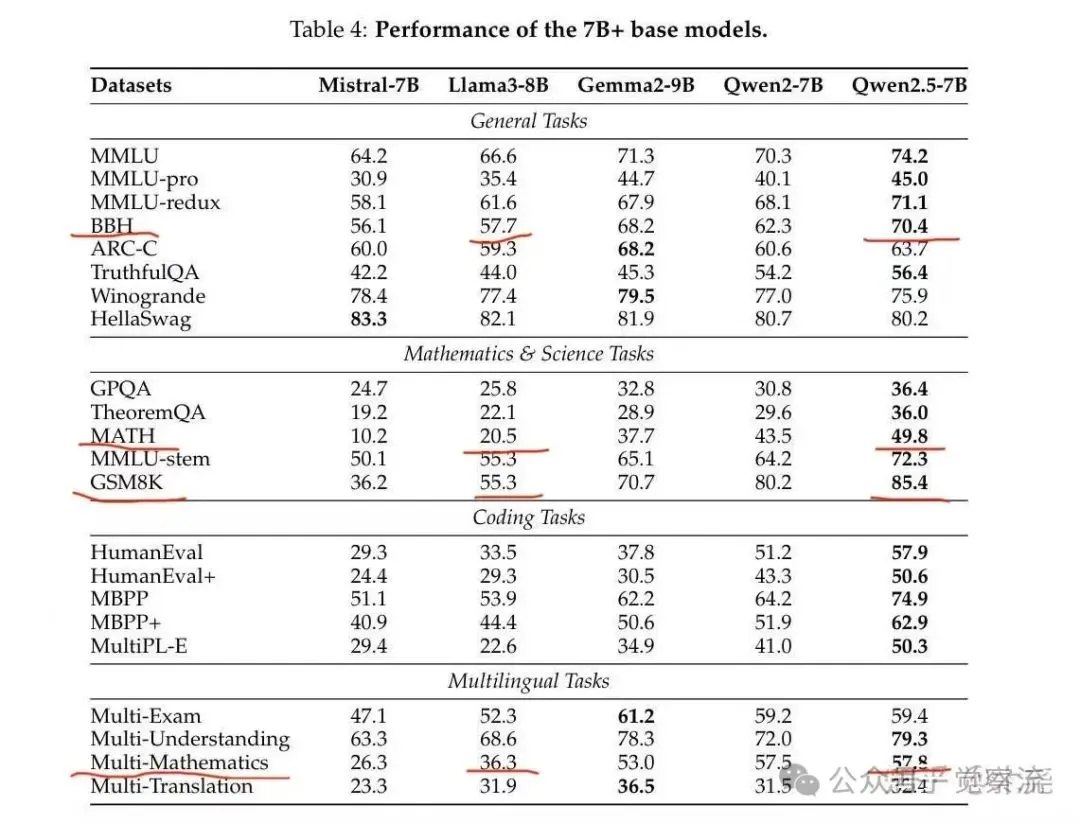
这是我们在社群中讨论问题时所贴的内容,图中我已经划出了个别项目。从图中可以看出,与因果推理能力相关的各项指标中,Qwen2.5几乎都高于Llama。这一结果印证了上面所提斯坦福研究的结论。同时也进一步证实了另一个认知:
模型的因果推理能力取决于至少两个方面,1.知识的广度和深度2.推理方法的掌握,比如CoT,ToT,GoT等等
从这两个角度来看,目前所有的推理模型几乎都是以O1为起点进行模仿,或者在此基础上进行二次创新,这应该是一个行业共识。
那么我们来探讨一下O1和R1的训练方法。它们都离不开高质量的推理类数据,通过强化学习或监督微调(SFT)来进行训练。那么这些训练究竟在训练什么呢?其实正是我之前提到的第二点,即培养掌握推理方法的能力。至于第一点呢?O1并没有解决,实际上,目前所有的推理模型都还没有解决。大家主要是在第二点上,投入了更多的精力,进行了大量的训练类或Agent类的工程工作。
那么目前来看,无论是o1还是现有的所有推理模型,它们所解决的只是推理方法这一“术”的层面的问题,而并未触及知识宽度和深度的压缩这一“道”的层面的问题(这也许是模型训练的瓶颈之一)。因此,因果推理如果缺乏充足的知识嵌入,仅凭借对推理方法的掌握,很快就会触及到一个触手可及的天花板。
这个道理其实很好理解。小学奥数竞赛题,小学生可以通过CoT(思维过程)来推理解答,但面对高中题目就无从下手了,原因就在于知识储备不足。同理,博士如果只靠知识储备,而没有掌握有效的推理方法,也很难开展学术研究,更别提发表论文了,甚至可能无法顺利毕业。因为学术研究不仅需要丰富的知识,更需要科学的推理方法,二者缺一不可。
再看DeepSeek这次的蒸馏模型,它堪称一个绝佳范例。该蒸馏模型仅用800k数据进行训练,这个数据量很小,然而查看论文中的benchmark,其效果却出奇地好,这充分彰显了技术的精妙之处。但为何DeepSeek会选择Qwen和Llama架构呢?不妨去Hugging Face的榜单上瞧瞧,头部前50的模型中,大多基于这两个架构,其中Qwen的占比或许更高,这本身就足以证明Qwen和Llama模型的卓越。倘若Dense模型的知识嵌入不够充分,那么仅用800k数据的蒸馏训练,恐怕很难取得理想的推理效果。
简单总结一下,模型知识压缩嵌入与推理方法的掌握同等重要。然而,目前全行业大多只在推理方法上投入了大量精力,因为这部分相对于已遇瓶颈的知识嵌入来讲可优化空间较大。而对于模型知识压缩嵌入,却总是以数据不足为由,迟迟没有太多实质性进展,这无疑是一个需要解决的重大问题。
所以,这么来看,仅凭模型训练这样单一的手段,就要达到“模型即产品”,是容易触及瓶颈的。
当前AI发展面临的核心命题,已从单一模型能力突破转向系统工程创新。要构建真正可落地的智能产品体系,必须突破"唯模型论"的局限,转而采用多维度融合演进策略:
- 在技术架构层,构建基于Agent集群拓扑结构的协同智能网络,通过工作流引擎实现复杂任务编排,使系统具备动态适应能力
- 在算法创新层,持续精进核心算法,探索模型架构的范式突破,保持基础能力的代际优势
- 在社会技术系统层,设计符合人类组织行为的交互范式,建立人机价值对齐机制
这种融合系统工程思维与社会技术系统视角的复合型智能架构,将推动AI应用从"功能模块"向"生态体系"跃迁。当模型能力的持续突破与多智能体协作网络形成共振,辅以人类反馈强化的人机协同机制,智能系统的进化将进入"飞轮效应"通道,开启人机协同新范式的无限可能。
四、总结与期许
现在,我们站在此刻回望这四个月的AI浪潮,会发现这场变革呈现出两个相互矛盾的演进方向:一方面,模型能力以指数级速度突破认知边界;另一方面,行业生态却仍在用线性思维构建护城河(但变化已起)。这种矛盾恰恰揭示了AI发展的深层规律——技术革命永远快于社会变革,但最终必须通过社会系统的消化吸收才能创造真实价值。
生态重构:从零和博弈到共生进化
百度地图与高德的MCP Server支持,折射出工具类应用向"智能体基座"转型的战略选择。这种选择背后,是AI时代对传统商业逻辑的颠覆性解构:当服务被抽象为协议接口,当用户交互被重构为智能体协作,旧有的流量霸权、平台垄断都将面临范式性挑战。
这要求企业必须具备"双重进化"能力——既要保持对核心技术的前沿探索,又要完成从"流量收割者"到"生态培育者"的角色转换。
模型革命:知识压缩与推理范式
斯坦福对Qwen的研究揭示了一个重要事实:模型能力的突破本质上是认知科学的工程化实践。我们惊叹于DeepSeek-R1模型在因果推理上的飞跃时,不应忽视其背后长达数月的训练数据配比优化、强化学习策略迭代。未来的模型进化必将呈现"知识嵌入-方法革新-场景验证"的三螺旋结构,这需要学界与产业界打破数据孤岛,建立开源协作的新型研发范式。
协议构建:标准之争背后的文明
当前围绕MCP、ANP的协议探讨,本质上是在智能时代构建一种全新的连接与协同机制。协议标准不应成为科技巨头们争夺主导权的战场,而应成为连接人类智能与机器智能的“认知桥梁”。这要求开发者社区保持清醒:真正的标准生命力不在于技术先进性,而在于能否创造普惠价值。正如TCP/IP协议的成功源于其“简单而开放”的设计哲学,AI时代的协议更需要,足够简单以包容复杂,足够开放以孕育可能。
未来图景:在确定性中寻找创新的不确定
面对"物理方一日,智能已千年"的进化速度,我们或许需要建立新的认知坐标系:
- 能力观:拥抱"脑(模型)-手(Agent)-工具链(协议)"的协同进化
- 生态观:超越零和博弈思维,在开放协议框架下构建"价值网络"
- 伦理观:警惕技术达尔文主义,为智能进化保留人文关怀的"减速带"
站在这个充满不确定性,又具有确定性的十字路口,我们既要有破釜沉舟拥抱变革的勇气,也要保持"让子弹再飞一会"的战略定力。因为真正的智能革命,从来都不是某个技术参数的突破,而是整个人类认知系统、协作网络、价值体系的范式迁移。或许我们终将明白:这场革命的终极目标,不是创造超越人类的智能,而是让人类在智能进化的浪潮中,重新发现自身的不可替代性。
我很喜欢大刘的《三体》。所以,正如《三体》中罗辑在黑暗森林中点燃篝火,AI时代的开拓者们,正在用协议、模型、Agent编织新的文明图腾。这图腾或许终将模糊人与机器的边界,但只要我们始终铭记"技术服务于人"的初心,这场AI智能的变局,终将会成为人类文明史上最闪耀的跃迁时刻。
各位朋友,看过此文有什么感想?如有其他想法可以在评论区留言,我们聊聊。或者加入“觉察流”社区群,与群里的小伙伴一起学习、交流。加入方法,私信回复“入群”“加群”即可。
参考资料
- 社群聊天记录


