
在大语言模型(LLMs)主导的AI时代,知识密集型任务始终面临一个核心矛盾:LLM擅长复杂推理,但受限于固定参数无法动态获取最新或领域专属知识;检索增强生成(RAG)虽能链接外部知识,却常因“一刀切”的检索逻辑陷入噪声冗余、推理浅薄的困境。
来自罗格斯大学、西北大学与NEC实验室的团队提出的DeepSieve,创新性地将LLM作为“知识路由器”,通过多阶段信息筛选机制,为异构知识源与复杂查询的精准匹配提供了新解法。本文将带您深入拆解这一方案的设计思路与实验效果。
论文地址:https://arxiv.org/pdf/2507.22050
项目代码:https://github.com/MinghoKwok/DeepSieve
01、为什么需要DeepSieve?RAG的两大核心痛点
现有RAG系统虽能缓解LLM的“知识过时”问题,但在处理真实场景任务时,存在难以逾越的两大障碍:
1. query侧:复杂查询被“一刀切”
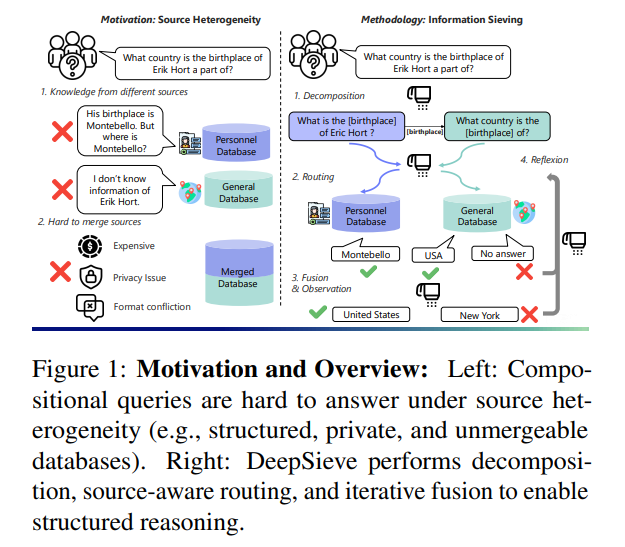
多数RAG将用户查询视为“原子单元”,直接送入检索器匹配。例如面对“谁是尼日利亚空中医生服务创始人的丈夫”这类嵌套查询,系统无法拆解“先找创始人→再查其配偶”的推理链,要么返回无关信息,要么直接 hallucinate 出虚假答案。
2. 知识源侧:异构信息难兼容
真实世界的知识源高度多样:既有非结构化的文档库,也有结构化的SQL数据库,还有需API调用的实时数据(如天气、地图)。传统RAG将所有源合并为统一索引,不仅因格式冲突丢失信息,还会因隐私限制(如企业私有数据库)无法实现;更糟的是,检索时不区分源特性,比如用文本检索处理“19世纪出生的放射性发现者”这类需时间筛选的问题,效率极低。
而DeepSieve的核心目标,就是通过结构化分解查询与源感知路由,实现“查询按需拆、知识精准取”。
02、DeepSieve的核心设计:四阶段信息筛选流水线
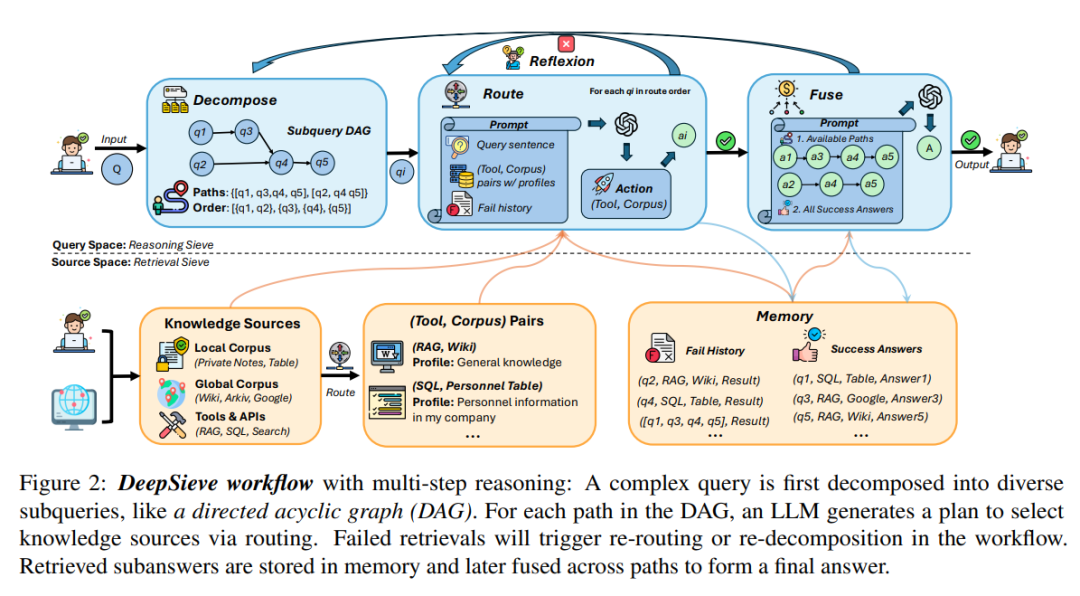
DeepSieve的本质是一套“模块化、可迭代”的检索推理框架,通过四个核心阶段完成从复杂查询到精准答案的转化,整体流程如图所示:
关键符号定义
- Q:原始复杂查询(如“尼日利亚空中医生服务创始人的丈夫是谁”)
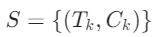 :知识源集合,
:知识源集合,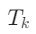 是工具(如SQL、RAG检索器),
是工具(如SQL、RAG检索器),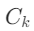 是对应语料库(如员工数据库、维基文档)
是对应语料库(如员工数据库、维基文档)- 核心操作:分解→路由→检索→反思→融合
阶段1:Query分解——把复杂问题拆成“可解单元”
第一步是将原始查询转化为结构化的子问题有向无环图(DAG)。例如:
- 原始查询:“谁是尼日利亚空中医生服务创始人的丈夫?”
- 分解结果:
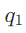 :谁创立了尼日利亚空中医生服务?
:谁创立了尼日利亚空中医生服务?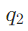 :该创始人的丈夫是谁?
:该创始人的丈夫是谁?
这里的关键是用LLM作为“规划器”,确保每个子问题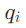 仅对应一个“可检索事实”,且DAG的边能体现子问题间的依赖关系(如
仅对应一个“可检索事实”,且DAG的边能体现子问题间的依赖关系(如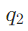 依赖
依赖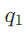 的结果)。这一步就像把“拆快递”的复杂动作,拆解为“找快递单→核对地址→拆包装”的明确步骤。
的结果)。这一步就像把“拆快递”的复杂动作,拆解为“找快递单→核对地址→拆包装”的明确步骤。
阶段2:知识路由——LLM当“路由器”,子问题匹配最优源
对每个子问题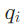 ,LLM会根据三个维度选择最优(工具-语料库)对:
,LLM会根据三个维度选择最优(工具-语料库)对:
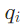 的语义:比如“创始人是谁”是实体查询,“丈夫是谁”是个人关系查询;
的语义:比如“创始人是谁”是实体查询,“丈夫是谁”是个人关系查询;- 知识源 profile:每个源会标注领域(如“员工数据库-存储个人信息”“维基文档-通用知识”)、格式(SQL/文本)、隐私级别;
- 历史失败记录:若某源曾检索失败(如查“创始人丈夫”用维基无果),则优先避开。
仍以“空中医生”查询为例:
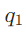 (找创始人)→ 路由到“维基文档+RAG检索器”(通用知识源);
(找创始人)→ 路由到“维基文档+RAG检索器”(通用知识源);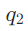 (找丈夫)→ 路由到“本地人物数据库+SQL工具”(私有个人信息源)。
(找丈夫)→ 路由到“本地人物数据库+SQL工具”(私有个人信息源)。
这种“按需分配”的逻辑,彻底避免了传统RAG“用文本检索查结构化数据”的低效问题。
阶段3:观察与反思——检索失败时的“自我修正”
检索到子答案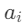 后,LLM会先判断其是否“有效”(如是否完整、是否相关)。若无效(如
后,LLM会先判断其是否“有效”(如是否完整、是否相关)。若无效(如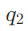 检索到“无公开信息”),则触发“反思循环”:
检索到“无公开信息”),则触发“反思循环”:
- 不修改子问题本身,而是重新路由(如从“本地数据库”切换到“社交媒体文档库”);
- 所有尝试结果会存入记忆模块MMM:成功结果
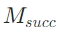 (如
(如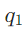 的“创始人是Ola Orekunrin”)用于最终融合,失败结果
的“创始人是Ola Orekunrin”)用于最终融合,失败结果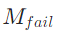 (如“维基查丈夫无果”)用于后续避坑。
(如“维基查丈夫无果”)用于后续避坑。
这一步让DeepSieve具备了“抗错能力”,而非像传统RAG那样“一次检索定生死”。
阶段4:答案融合——从子答案到连贯响应
所有子问题解决后,LLM会基于DAG的依赖关系,将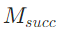 中的子答案聚合为最终答案。例如:
中的子答案聚合为最终答案。例如:
- 子答案1:Ola Orekunrin创立了尼日利亚空中医生服务;
- 子答案2:未检索到Ola Orekunrin丈夫的公开信息;
- 最终答案:尼日利亚空中医生服务的创始人是Ola Orekunrin,目前暂无其丈夫的公开记录。
若子答案存在冲突(如不同源对“创始人”有不同说法),LLM还会进行全局推理,优先选择高可信度源的信息。

模块化优势:即插即用,灵活扩展
DeepSieve的每个阶段都是独立模块,可按需替换:
- 检索器:支持BM25、FAISS、ColBERTv2等;
- 知识源:新增“实时天气API”只需注册工具和profile,无需修改整体流程;
- LLM backbone:可切换DeepSeek-V3、GPT-4o等模型。
这种设计让它既能适配学术场景的“多跳问答”,也能落地工业场景的“企业私有知识检索”。
03、实验验证:性能与效率双超越
团队在三个经典多跳问答基准(MuSiQue、2WikiMultiHopQA、HotpotQA)上做了全面测试,核心回答四个问题:
性能是否超越传统RAG?(RQ1)
在DeepSeek-V3作为 backbone 时:
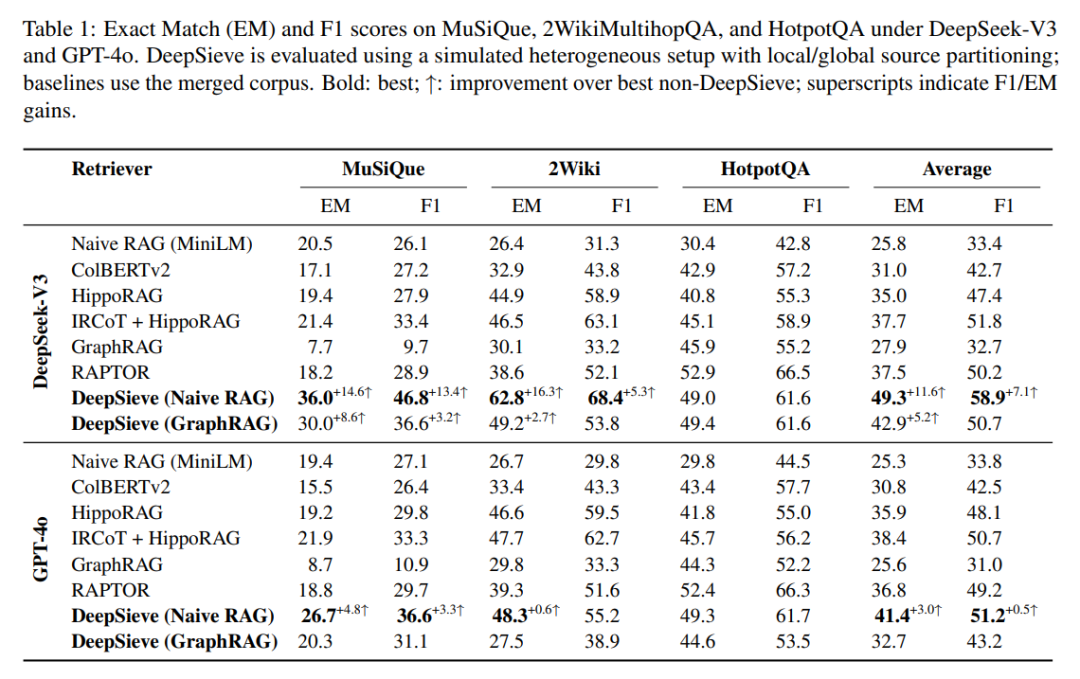
- MuSiQue数据集:DeepSieve(Naive RAG)F1分数46.8,比IRCoT+HippoRAG(传统RAG组合)高13.5;
- 2WikiMultiHopQA数据集:F1分数68.4,比传统组合高5.3;
- 平均F1 58.9,超越所有纯RAG和智能体RAG(如ReAct、Reflexion)基线。
即使切换到GPT-4o,DeepSieve在HotpotQA的F1仍达61.7,远超CoT(30.8)、ReAct(39.6)等方法。
实验结果表明,DeepSieve在多个多跳问答数据集上显著提高了答案准确性。
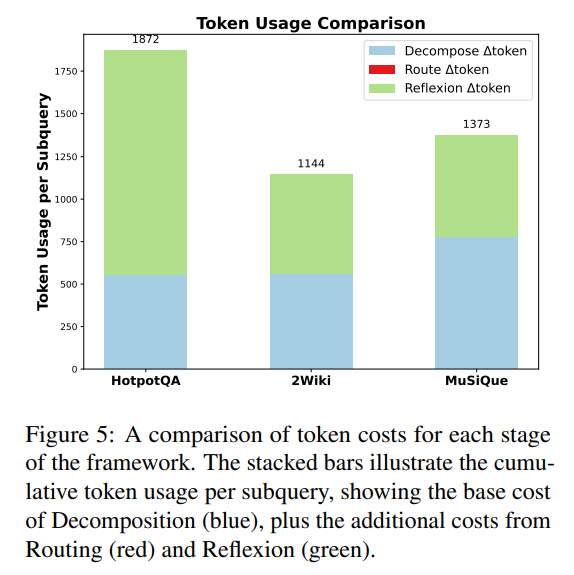
推理成本是否更低?(RQ2)
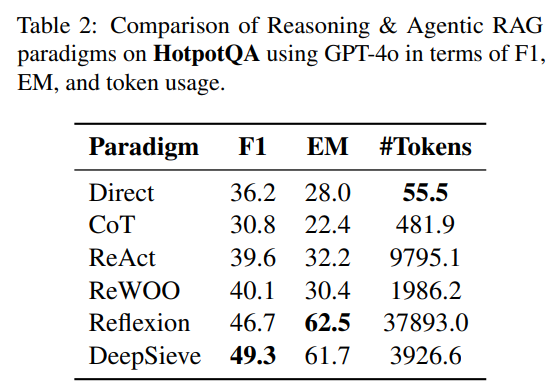
Token效率是工业落地的关键指标。实验显示,DeepSieve在HotpotQA上:
- 平均每查询仅用3.9K Token;
- 而Reflexion(智能体RAG)需37.9K Token,ReAct需9.8K Token;
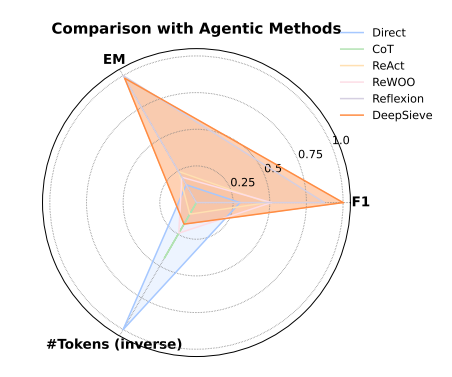
- 雷达图显示,DeepSieve在“F1分数、EM分数、Token效率”三个维度的综合表现最优,是“精准与高效”的平衡者。
结果表明,DeepSieve使用的Token数明显少于其他基于大语言模型的系统,同时实现了更高的准确性,表现出很强的成本效益。
各模块的贡献有多大?(RQ3)
消融实验揭示了三个核心模块的价值:
- 分解模块:移除后MuSiQue的F1下降17.5分,证明“拆查询”是多跳推理的基础;
- 反思模块:移除后2WikiMultiHopQA的F1从68.4暴跌至15.4,说明“自我修正”对处理噪声至关重要;
- 路由模块:单独使用时效果有限,但与前两者结合后,能显著提升异构源场景的鲁棒性(如跨SQL和文本源检索)。
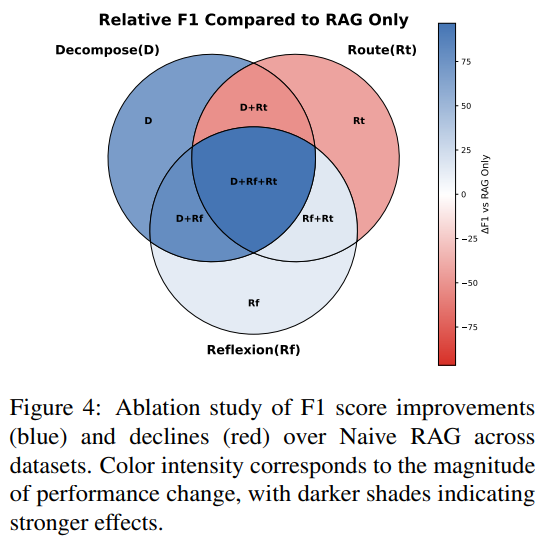
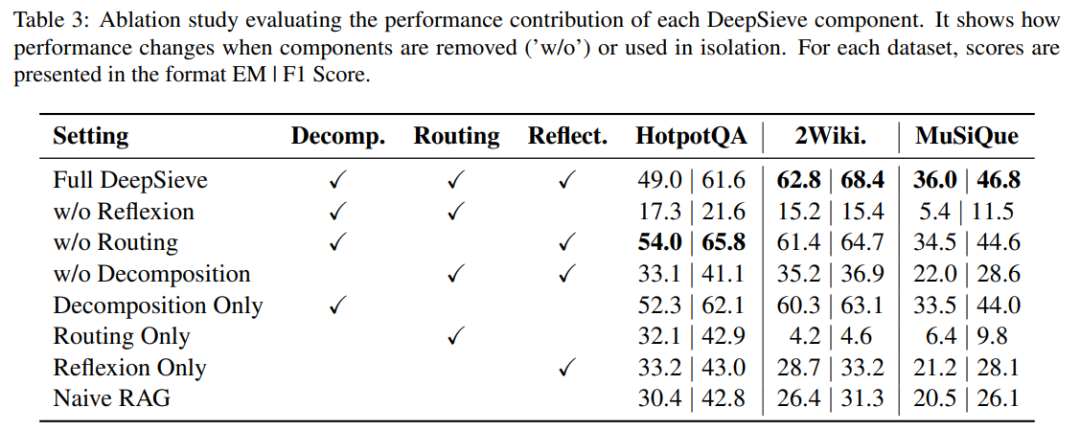
结果表明,分解和反思是准确性的关键。单独的路由可能表现不佳,但结合使用时,它在不牺牲性能的情况下提高了鲁棒性,并能处理异构知识源。
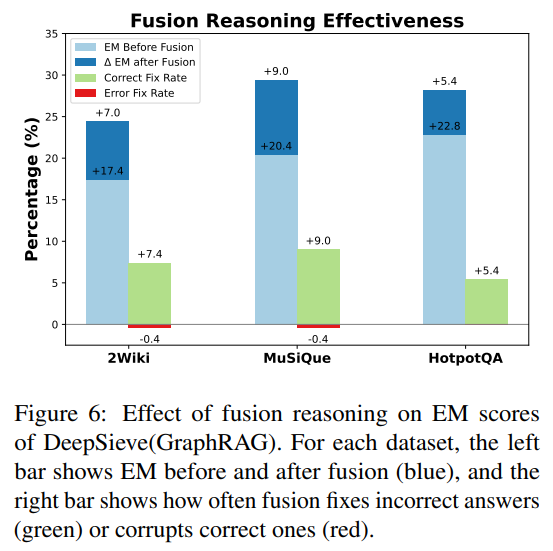
能否适配不同知识源?(RQ4)
测试了两种检索设置(Naive RAG、GraphRAG)和两种知识源(本地+全局拆分的异构源、统一源):
- 在异构源场景:DeepSieve的F1比传统RAG高8-12分;
- 在统一源场景:仍比传统RAG高5-7分,证明其不仅适配多源,还能优化单源检索;
- 新增SQL源后:无需修改核心逻辑,仅注册工具即可支持“19世纪放射性发现者”这类需筛选的查询,F1达59.1,接近专家Oracle的性能。
04、总结:DeepSieve的价值与未来方向
核心价值
- 解决RAG痛点:通过“分解+路由”终结“检索噪声”,通过“反思”提升抗错能力;
- 兼顾性能与效率:在三个基准上实现F1最优,同时Token成本仅为Reflexion的1/10;
- 工业级适配性:模块化设计支持SQL、API、文本等多源,隐私数据无需合并索引。
未来可探索方向
- 细粒度路由:当前仅选择(工具-语料库)对,未来可扩展到工具参数(如检索深度、API调用模式);
- 个性化适配:针对不同用户(如医生vs学生)定制知识源优先级,实现“千人千面”的检索;
- 成本感知:在路由时加入成本权重(如API调用费vs本地检索),进一步优化工业落地成本。


