
在自然语言处理领域,大语言模型(LLMs)已经取得了令人瞩目的成就。然而,当面对知识密集型任务时,例如科学文献综述、法律案件简报或医疗诊断,这些模型往往显得力不从心。它们难以有效地整合新的或特定领域的知识,而现有的检索增强生成(RAG)方法也因无法满足复杂的跨段落或文档的知识整合需求而受到限制。
为了解决这一问题,研究人员提出了 HippoRAG,这是一种受到海马体记忆索引理论启发的检索增强生成方法,旨在增强语言模型处理知识密集型任务的能力,并优化信息检索过程。
论文地址:https://arxiv.org/abs/2405.14831
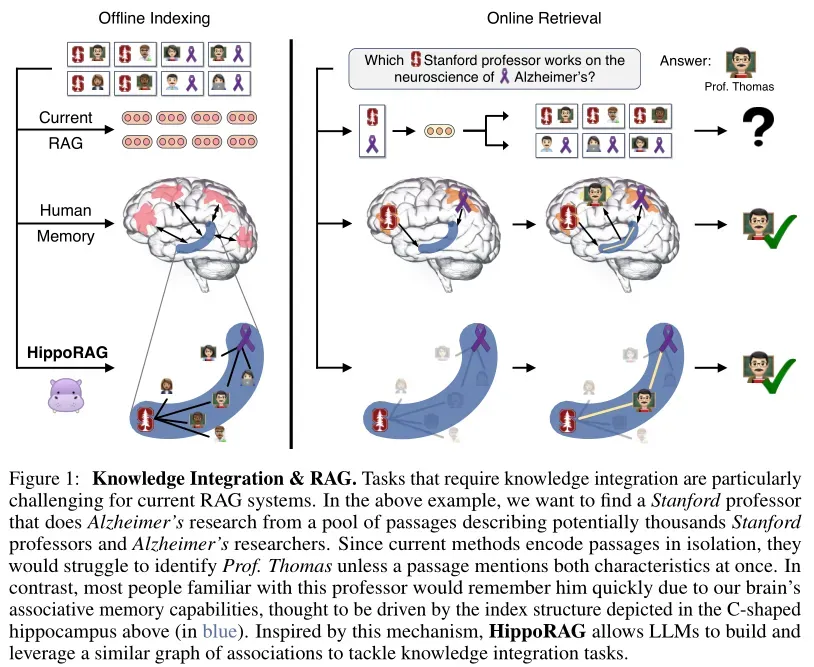
1、海马体记忆索引理论
海马体记忆索引理论是描述人类长期记忆的一个成熟理论,由 Teyler 和 Discenna 提出。该理论解释了人脑中负责长期记忆的不同组件和电路如何协同工作,以完成两个主要目标:模式分离和模式完成。
海马记忆索引理论是一个描述人类长期记忆的成熟理论,由 Teyler 和 Discenna提出,解释了人脑中负责长期记忆的不同组件和电路如何协同工作以完成两个主要目标:模式分离(pattern separation)和模式完成(pattern completion)。
- 模式分离:在记忆编码过程中,新皮层接收和处理感知刺激,将其转换为高级特征,然后传递到海马体进行索引。海马体中的显著信号被纳入索引,并相互关联。这一过程确保了不同感知体验的记忆表示是唯一的。
- 模式完成:在记忆检索过程中,海马体接收到部分感知信号后,利用其基于上下文的记忆系统识别索引中的完整且相关记忆,并将其回传到新皮层进行模拟。即使提供的线索并不完整或精确,海马体中的索引也能帮助定位相关的记忆条目。
海马体在这个过程中扮演着关键角色。在记忆编码阶段,它接收来自新皮层的感知信息,并将显著的信息信号加入索引;在记忆检索阶段,它通过索引触发模式完成的过程,从而实现从部分提示恢复完整记忆的能力。
2、HippoRAG
HippoRAG 的设计灵感来源于海马体记忆索引理论,它模拟了人类大脑中模式分离和模式完成的过程,以更高效地处理需要复杂推理或大量背景知识的任务。
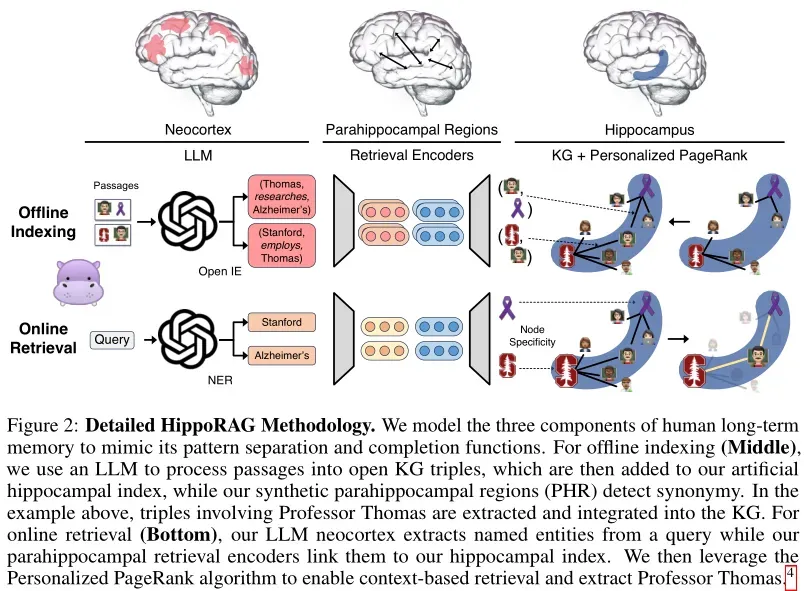
离线索引:构建知识图谱
- 使用 LLM 进行开放信息提取(OpenIE):在离线索引阶段,HippoRAG 利用指令调优的大语言模型(如 GPT-3.5 或 Llama-3.1)作为“人工新皮质”,从检索语料库中提取知识图谱(KG)三元组。以开放信息抽取的方式,将文档中的关键信息(如命名实体和关系)以离散的名词短语形式提取出来,而不是采用密集的向量表示。这种方式实现了更精细的模式分离,使得 HippoRAG 能够更有效地处理长文本和复杂关系。
- 构建无模式的知识图谱:将 OpenIE 提取的三元组存储在无模式的知识图谱中。该图谱包含实体节点、关系边和同义词边。同义词边连接相似但不同的名词短语,帮助 HippoRAG 在在线检索阶段更好地理解查询。
- 使用检索编码器进行索引:使用预先训练好的密集编码器(如 ColBERTv2)为知识图谱中的节点生成密集表示。这不仅有助于识别和添加同义词边,还能连接原本孤立但语义相似的节点,从而提高知识图谱的连通性。
在线检索:高效的知识整合
- 使用 LLM 进行命名实体识别(NER):在在线检索阶段,HippoRAG 模仿人脑的记忆检索过程,使用 LLM 从查询中提取命名实体。这些实体成为 HippoRAG 在知识图谱中进行检索的起点。
- 选择查询节点:使用检索编码器将查询中的实体编码成密集表示,并与知识图谱中的节点表示进行相似度计算,选择最相似的节点作为查询节点。这些节点代表了与查询相关的实体,并作为 HippoRAG 进行多跳推理的起点。
- 使用个性化 PageRank 进行检索:一旦确定了查询节点,HippoRAG 就可以开始执行模式完成的过程,这类似于人类记忆从部分提示恢复完整记忆的能力。具体来说,HippoRAG 采用个性化 PageRank(PPR)算法在知识图谱上运行,以找到与查询最相关的节点及其邻域。根据选定的查询节点,HippoRAG 设置 PPR 的个性化概率分布,其中查询节点的概率设置为 1,其他节点的概率设置为 0。这意味着初始概率只集中在那些与查询直接相关的节点上。随着 PPR 算法的迭代,概率会沿着知识图谱中的边传递给其他节点。由于边权重反映了节点间的关联强度,因此更紧密相连的节点会获得更高的概率值。除了直接关联的节点外,PPR 还能够探索几跳之外的节点,从而捕捉到更广泛的上下文信息。这种单步多跳检索的能力使得 HippoRAG 在处理复杂问题时表现出色。
- 计算文档得分并进行检索:经过 PPR 算法后,HippoRAG 获得了每个节点的概率得分,这些得分指示了节点与查询的相关性。然后,系统将这些节点概率聚合回原始文档,为每个文档计算一个综合得分,用于最终的段落排名。对于出现在多个文档中的相同节点,HippoRAG 会将它们的概率得分累加到对应的文档上,形成段落级别的评分。根据段落评分,HippoRAG 对所有候选文档进行排序,挑选出最有可能包含正确答案的前几个段落作为回答来源。
生成答案:自然语言生成与信息整合
最后,HippoRAG 利用检索到的相关段落和知识图谱结构,结合生成器模块生成最终的答案。生成器可以根据提供的上下文生成自然语言的回答,确保答案不仅准确而且易于理解。这一过程可能涉及模板填充、文本摘要或其他形式的语言生成技术。如果一个问题需要整合来自不同段落的信息,生成器会巧妙地将这些片段组合成一个连贯的回答。
3、单步多跳高效解决复杂查询
单步多跳是一种在信息检索和问答系统中用于解决复杂查询的技术,尤其是在需要跨多个文档或段落进行推理的多跳问答(Multi-Hop QA)任务中。与传统的多步多跳方法不同,单步多跳能够在一次检索操作中完成多跳推理,而不需要多次迭代检索和生成步骤。
多跳问答的背景
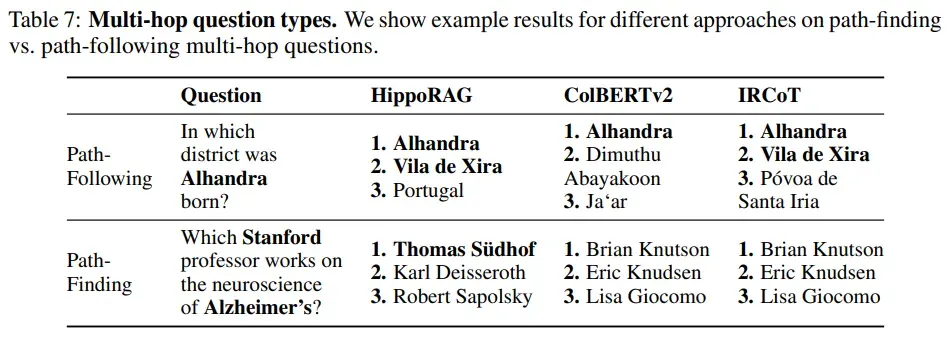
多跳问答任务要求系统能够通过多个文档或段落中的信息进行推理,以回答复杂的问题。例如,问题可能是:“哪位斯坦福大学的教授研究阿尔茨海默病?”要回答这个问题,系统需要首先找到斯坦福大学的教授列表,然后找到研究阿尔茨海默病的教授,最后将这两个信息结合起来找到答案。
传统的多跳问答系统通常采用多步检索的方法,即系统首先检索与问题相关的第一个文档,然后根据第一个文档中的信息生成新的查询,再进行第二次检索,依此类推,直到找到所有必要的信息。这种方法虽然有效,但存在以下问题:
- 效率低:每次检索都需要生成新的查询并进行检索,增加了计算成本和时间。
- 误差累积:每一步的检索和生成都可能引入误差,导致最终答案不准确。
单步多跳的核心思想
单步多跳的核心思想是通过一次检索操作完成多跳推理,而不需要多次迭代。具体来说,系统通过构建一个知识图谱(KG)或类似的图结构,将文档中的实体和关系表示为图中的节点和边。当用户提出一个多跳问题时,系统通过图搜索算法(如个性化 PageRank,PPR)在图中找到与查询相关的节点和路径,从而一次性检索到所有必要的信息。
4、实验结果
为了验证 HippoRAG 的性能,研究人员在多个数据集上进行了实验,包括 MuSiQue、2WikiMultiHopQA 和 HotpotQA。这些数据集涵盖了多跳问答任务的不同场景,能够全面评估 HippoRAG 的检索和问答能力。
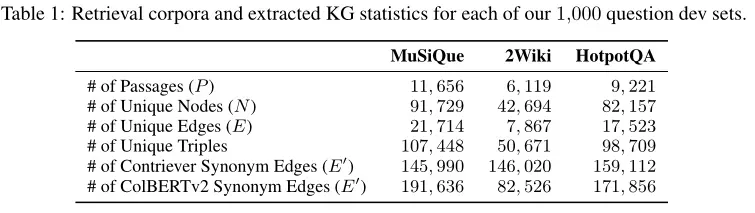
单步检索结果
HippoRAG 在 MuSiQue 和 2WikiMultiHopQA 数据集超越其他方法,在 2WikiMultiHopQA 数据集上,R@2 和 R@5 提升显著。在 HotpotQA 数据集上,HippoRAG 的性能与 ColBERTv2 相当。作者认为,2WikiMultiHopQA 的实体中心设计特别适合 HippoRAG,而 HotpotQA 的性能较低主要是因为其对知识整合的要求较低,以及概念-上下文权衡的问题。
多步检索结果
IRCoT(Iterative Retrieval with Contextualized Objectives and Training)是一种迭代检索方法,旨在通过多轮次的检索过程来逐步精炼和聚焦于最相关的文档或段落,以提高信息检索和问答系统的准确性。实验结果表明,IRCoT 和 HippoRAG 是互补的。
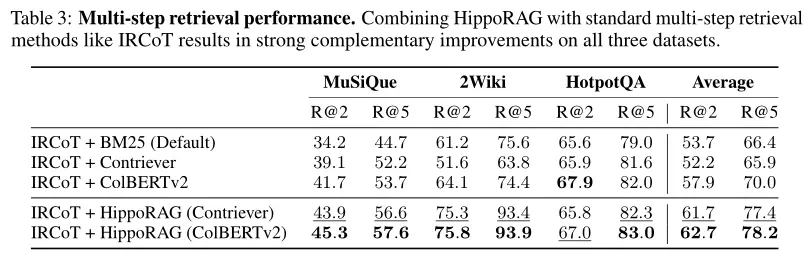
问答结果
实验表明,HippoRAG 的检索改进直接转化为了更好的问答性能。特别是在依赖复杂推理和多源信息整合的问题上,HippoRAG 提供的支持使得生成的回答更加准确和详尽。
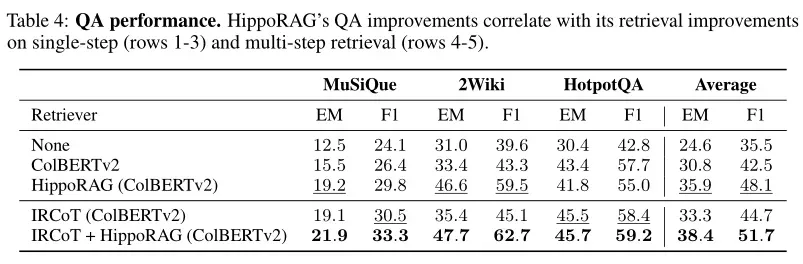
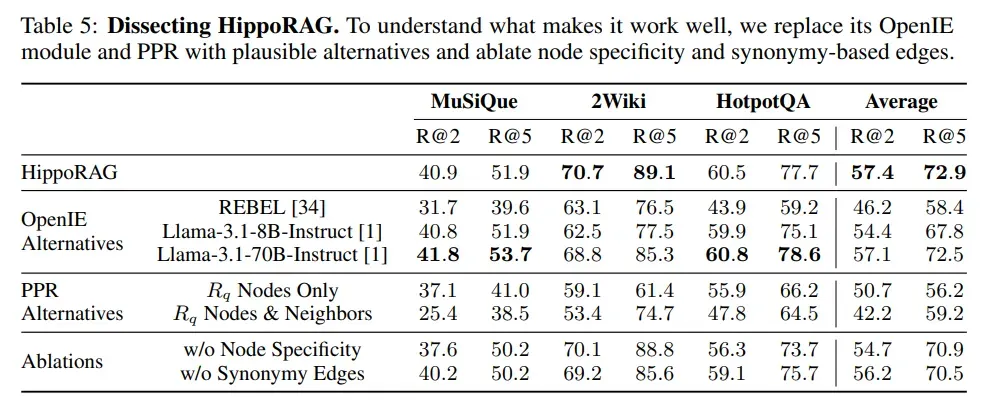
消融实验
OpenIE替代方案:通过测试使用不同OpenIE模型(如REBEL和Llama-3.1)对HippoRAG性能的影响。结果表明,GPT-3.5在生成知识图谱(KG)时表现最佳,尤其是在生成三元组数量上远超REBEL。Llama-3.1-70B在某些数据集上表现与GPT-3.5相当,甚至更好,表明开源模型可以作为低成本替代方案。
PPR替代方案:通过比较PPR算法与其他简单的图搜索方法,发现PPR在检索关联信息时更为有效,尤其是在多跳推理任务中。
消融实验:通过消融实验,发现节点特异性(Node Specificity)和同义词边(Synonymy Edges)对检索性能有显著影响。节点特异性在MuSiQue和HotpotQA数据集上表现较好,而同义词边在2WikiMultiHopQA数据集上效果显著。
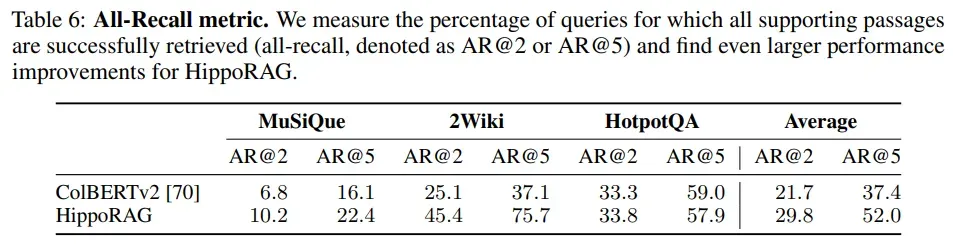
单步多跳检索:HippoRAG的一个主要优势是能够在单步检索中完成多跳推理任务,而传统RAG方法需要多次迭代。实验表明,HippoRAG在检索所有支持文档的成功率上显著优于其他方法,尤其是在2WikiMultiHopQA数据集上,HippoRAG的改进幅度更大。
路径发现多跳问题:HippoRAG在处理路径发现多跳问题时表现出色,这类问题需要在不同段落之间找到相关实体,而传统方法难以解决。HippoRAG通过其关联图和图搜索算法,能够有效识别相关实体并检索出正确的段落。
5、总结
从实验结果来看,HippoRAG 确实在知识密集型任务的处理上展现出独特优势。尽管文中提到未与 GraphRAG、GraphReader 等对比,且 QA 问答评估表现不如 GraphReader,并且从HippoRAG的方法细节中,可以了解到,HippoRAG对于信息的提取和表示相对粗糙,也是未来可以优化的地方。
在众多引入 graph 的方法中,HippoRAG 引入海马体记忆索引理论,无疑是故事讲的最好的一个。其实,无论哪种方法,最重要的是实用性、工程性,期待各个方法的落地。


