中科院智能信息处理重点实验室发表的Auto-RAG(Autonomous Retrieval-Augmented Generation) 技术,作为Agentic RAG(智能体驱动检索增强)趋势下的产出,打破传统RAG的「检索→生成」线性瓶颈,通过大语言模型(LLM)的自主决策能力,实现「检索规划→信息提取→答案推断」的闭环推理,让机器像人类侦探般动态收集线索、修正方向,无需人工预设规则。
这项技术的核心价值在于:将RAG从「被动执行工具」升级为「主动认知智能体」,不仅解决传统方法的效率低、幻觉多等问题,更在开放域问答、多跳推理等任务中展现出碾压级性能。
论文地址:https://arxiv.org/pdf/2411.19443
项目地址:https://github.com/ictnlp/Auto-RAG
01、研究动机:传统RAG的三大「致命痛点」
在Auto-RAG出现前,即使是Self-RAG、FLARE等先进方法,仍未摆脱对人工的依赖,这在实际应用中暴露出诸多短板:
1. 迭代检索「靠人工喂招」 :传统迭代RAG需手动设计规则:比如FLARE依赖8-shot提示词指定检索策略,Self-RAG则靠预设的「反射Token」(如[Relevant]标签)判断是否检索。一旦遇到未见过的问题(如「《三体》黑暗森林法则的哲学源头」),就会陷入「检索无效→生成幻觉」的死循环。
2. 多跳推理「链路易断裂」 :面对「A的父亲是B,B的老师是C,求C的代表作」这类多跳问题,Standard RAG仅能单次检索,易遗漏中间环节;Iter-RetGen虽支持迭代,但固定的检索次数会导致「单跳问题多轮冗余,多跳问题轮次不足」。
3. 结果解释「像开盲盒」 :多数RAG直接输出最终答案,既不说明「为什么检索这些文档」,也不解释「答案如何推导」。在医疗、法律等关键领域,这种「黑箱输出」根本无法落地——你无法让医生基于「不知来源的答案」诊断病情。
正是这些痛点,推动中科院团队研发出「让RAG自己做决策」的Auto-RAG技术。
02、方法解析:Auto-RAG的「自主推理三阶段」

Auto-RAG的核心是LLM驱动的动态决策框架,整个过程无需人工干预,完全模拟人类解决问题的思维逻辑:
阶段1:检索规划(「该查什么?」)
在接收到用户问题后,LLM需要明确识别回答问题所需的知识。在获取检索文档后,LLM需要评估是否需要进一步检索,并基于历史检索结果明确指定下一步需要检索的具体信息。这种规划能力对于提高检索效率和避免检索过程中的迷失方向至关重要。
举个例子:问「Anastasia Of Serbia丈夫的死亡地点」,首次检索未找到直接答案,模型会自动生成新查询:「Anastasia Of Serbia 丈夫 身份 死亡地点」,精准定位中间线索。
阶段2:信息提取(「有用没用?」)
每轮检索后,LLM会自主评估文档价值,从文档中提取与问题相关的有用信息,这一过程类似于人类的总结能力:若文档含「子答案」(如多跳问题的中间结论),则保留并整合;若无关(如误检索到同名人物),则标记「无需参考」并重新检索。
这解决了传统RAG「强制用噪声文档生成答案」的幻觉问题。
阶段3:答案推断(「停还是继续?」)
通过「信息完整性评分」判断是否终止:单跳问题1-2轮即可达标,多跳问题则动态迭代3-5轮。终止时不仅输出答案,还会用自然语言还原推理过程,比如:


在Auto-RAG的自主决策框架背后,指令数据集构建的合理性、训练策略的针对性、推理流程的工程化设计是其实现“小数据高效收敛”与“低幻觉精准输出”的核心支撑。以下从技术落地视角,详解这三大关键环节的实现逻辑:
03、指令数据集构建:从「噪声过滤」到「对话式格式化」,奠定自主决策基础
Auto-RAG的自主推理能力,并非依赖海量人工标注数据,而是通过低成本的指令数据集自主合成技术实现——核心是解决“推理伪影”和“查询质量差”两大问题,确保模型学到的决策逻辑既精准又通用。
核心目标:用「子答案验证」替代人工筛选
传统迭代RAG的数据集构建常陷入两个误区:要么依赖人工标注每轮检索的“有效查询”,成本极高;要么直接使用原始问答对,导致模型学到无效检索逻辑。Auto-RAG的突破在于:以“子答案”为锚点,让数据自己“筛选”有效样本。
在多跳问答任务中,一个完整答案(如“Anastasia Of Serbia丈夫的死亡地点是Hilandar修道院”)往往拆解为多个“子答案”(如“丈夫是Stefan Nemanja”“Stefan Nemanja死于Hilandar修道院”)。Auto-RAG在每次迭代中,会先让LLM生成多个候选查询,再用检索器验证这些查询能否召回包含“子答案”的文档——只有能召回有效子答案的查询,才会被保留到数据集中。
这种机制从源头避免了“无效查询污染数据”:比如针对“《The Sensational Trial》导演国籍”的问题,若LLM生成“《The Sensational Trial》上映时间”这类无关查询,因无法召回“导演是Karl Freund”的子答案文档,会被直接过滤,确保最终数据集里每一条查询都能推动推理进程。
数据格式化:把「迭代检索」变成「多轮对话」
为了让LLM理解“检索-推理-再检索”的闭环逻辑,Auto-RAG将整个过程设计成结构化对话格式,模拟人类与检索工具的交互场景。具体遵循“输入-输出”对应规则:
迭代阶段 | 输入 | 输出 | 核心作用 |
第0次 | 用户原始问题(如“Anastasia丈夫的死亡地点”) | LLM的推理(“需先确定丈夫身份+死亡地点”)+ 下轮查询(“Anastasia Of Serbia丈夫是谁及死亡地点”) | 启动推理,明确首次检索目标 |
第1~T-1次 | 上轮检索到的文档(如“丈夫是Stefan Nemanja”) | LLM的推理(“已获丈夫身份,缺死亡地点”)+ 下轮查询(“Stefan Nemanja死亡地点”) | 基于新信息,调整检索方向 |
第T次 | 最终检索到的文档(如“Stefan死于Hilandar修道院”) | LLM的推理(“已获死亡地点,信息完整”)+ 最终答案(“Hilandar修道院”) | 终止迭代,输出结论 |
这种格式化方式的关键价值在于:让LLM学到“根据历史信息动态决策”的能力,而非机械执行固定步骤。例如在第1次迭代后,若文档已包含完整答案,模型会直接输出结论,无需继续检索;若仅含部分信息,则自动生成补充查询——这正是Auto-RAG“自主决策”的数据集层面支撑。

04、训练策略:用「时序交叉熵」让模型学会“连贯推理”
Auto-RAG的训练核心不是“教模型回答问题”,而是“教模型如何规划检索步骤”。其采用的时序化监督微调策略,专门解决传统训练中“忽略迭代逻辑连贯性”的问题。
损失函数设计:聚焦「每一步决策的正确性」
传统RAG训练仅关注“最终答案是否正确”,而Auto-RAG的损失函数(时序交叉熵)则要求模型对每一轮迭代的输出负责,公式如下:
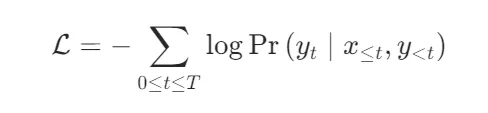
举个具体例子:在“Anastasia丈夫死亡地点”的任务中,模型在第1次迭代的输出(“需检索Stefan Nemanja死亡地点”),必须同时满足两个条件才会被判定为“正确”:
- 基于第0次的问题和第1次的文档(“丈夫是Stefan Nemanja”);
- 为第2次检索提供有效方向(“Stefan Nemanja死亡地点”)。
这种损失计算方式,强制模型学会“每一步都为下一步铺路”,避免出现“前序查询与后续推理脱节”的问题——比如先查询“Stefan Nemanja的出生年份”,再突然转向“死亡地点”,这种逻辑断裂会因损失值升高而被修正。
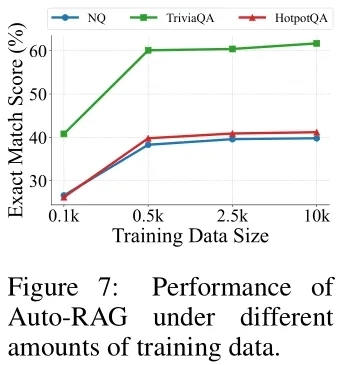
训练数据规模:小样本即可实现“自主决策入门”
与FLARE、Self-RAG等需要数万甚至百万级样本的方法不同,Auto-RAG对训练数据的需求极低:仅用10k(1万条)时序化指令样本,就能让模型具备基础的自主检索规划能力;若增加到25k样本,性能可提升12%-18%(在HotpotQA多跳任务中)。
这一特性的关键原因在于:Auto-RAG的训练目标是“通用检索决策逻辑”,而非“特定领域知识”。模型通过少量样本学到的是“如何分析问题→判断信息缺口→生成补充查询”的通用方法,而非记忆某类问题的答案——这也使得Auto-RAG能快速适配开放域、医疗、法律等不同场景,无需针对每个领域重新大规模标注数据。
05、推理流程:从「外部检索」到「参数化兜底」,避免“无限循环”
训练完成后,Auto-RAG的推理过程完全自主,无需人工干预,核心是通过“检索器交互+参数化知识兜底”的双层机制,平衡“外部知识准确性”与“推理效率”。
与检索器交互:动态判断“检索/终止”
Auto-RAG的推理流程遵循“迭代-验证-决策”的循环,具体步骤如下:
- 初始化(第0次迭代):模型接收用户问题后,先通过推理明确回答问题所需的知识(如“需确定A和B的国籍”),生成初步的检索规划和第一个检索查询(如“Coolie No.1(1995)导演及国籍”),为后续检索确定方向。
- 检索验证(第1~T次迭代):若前一次迭代的输出包含检索查询,模型会用该查询调用检索器获取文档;基于用户原始问题、历史所有输出和新获取的文档,模型再次推理,提取有用信息,并判断是否需要继续检索:若信息不足,生成新的补充查询用于下一轮检索;若已包含最终答案,则直接终止迭代并返回答案。
- 终止条件:当模型判断现有信息足够生成准确答案,或达到预设的最大检索次数时,停止检索。这种交互方式能实现“按需检索”,单跳问题通常1-2次迭代即可完成,多跳问题则会通过3-5次迭代逐步补全信息。
这种交互方式的优势在于“按需检索”:对于单跳问题(如“Hypocrite导演是谁”),模型可能1-2轮就找到答案并终止;对于多跳问题(如“达尔文出版《物种起源》时所在城市的市长”),则会自动迭代3-5轮,逐步补全中间信息。
参数化知识兜底:解决“检索器查不到”的困境
即使检索器性能再强,也会遇到“语料库中无相关信息”的情况(如小众人物、新兴事件)。此时Auto-RAG会启动“参数化知识调用”机制,避免陷入“检索无效→重复检索”的无限循环:
- 当模型与检索器交互T次后仍未终止,进入“参数化知识迭代阶段”(预设最大迭代次数);
- 模型不再调用外部检索器,而是基于自身预训练的参数化知识,针对当前查询生成一份“伪检索文档”,模拟外部检索到的信息。
- 模型将“伪检索文档”作为输入继续推理,若能生成合理答案则返回;若达到参数化知识迭代的最大次数仍无法生成,就基于现有信息输出最可靠的结论,并标注相关信息来源,确保结果可追溯。
这一机制的关键价值在于“鲁棒性”:既避免了传统RAG“无外部知识就生成幻觉”的问题,又通过“伪文档标注”保证了结果的可追溯性——在医疗、法律等关键领域,用户能清晰区分“答案来自外部权威文档”还是“模型内部推断”,降低决策风险。
06、实验验证:6大数据集碾压基线,多跳任务优势显著
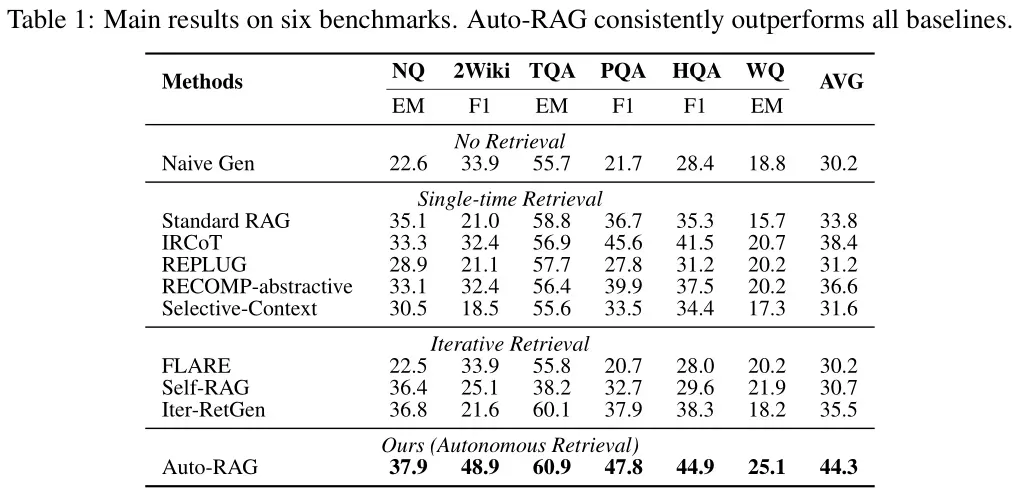
中科院团队在6个权威基准数据集(NQ、HotpotQA、TriviaQA等)上的实验,充分证明了Auto-RAG的性能:
主要结果
- 优越性能:Auto-RAG在所有数据集上均优于其他基线方法,尤其是在多跳问答任务上表现显著优于其他迭代检索方法(如FLARE、Self-RAG和Iter-RetGen)。
- 自主决策能力:Auto-RAG通过自主推理和决策机制,能够根据问题的复杂性和检索结果的相关性动态调整迭代次数和检索内容。
- 鲁棒性:即使在检索器提供的知识不足时,Auto-RAG仍能利用自身的参数化知识生成高质量的答案。
迭代次数分布
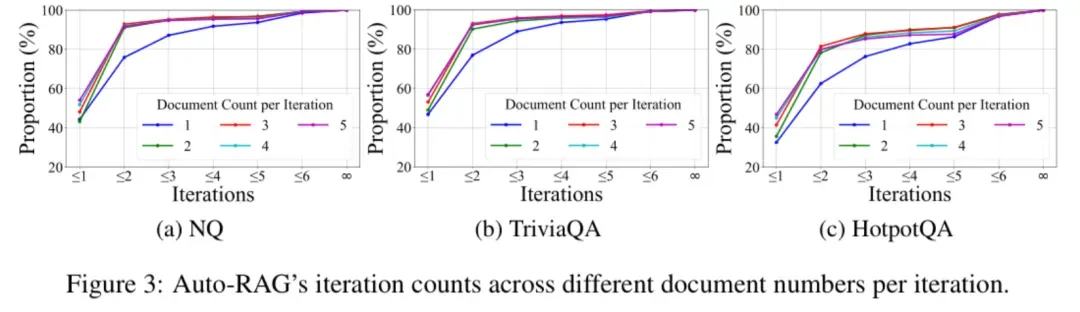
对于单跳问题(如Natural Questions和TriviaQA),Auto-RAG更多地在较少的迭代次数(1-2次)内完成任务。对于多跳问题(如HotpotQA),迭代次数分布更倾向于多次迭代(3-5次)。当检索器每次返回更多文档时,Auto-RAG更倾向于在较少的迭代次数内完成任务,表明其能够快速利用足够的信息。
结果表明,Auto-RAG能够根据问题的复杂性动态调整迭代次数,表现出良好的适应性。对于简单问题,模型能够快速生成答案;而对于复杂问题,模型会通过多次迭代逐步收集所需的知识。
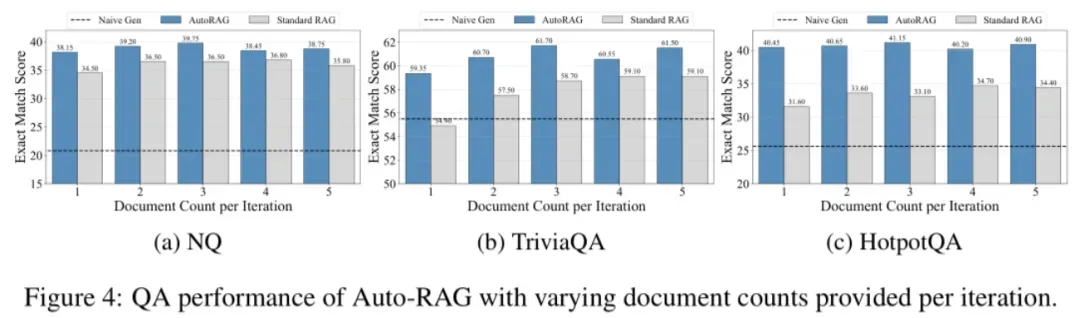
文档数量对性能的影响
传统RAG需精确调整「每次检索文档数」(k值),k太小漏信息,k太大添噪声。而Auto-RAG在k=2-5的范围内性能波动仅2.1%,即使仅给3篇文档也能达到最优效果,极大降低落地调试成本。 结果表明,Auto-RAG对每次迭代中检索器返回的文档数量具有较强的适应性。适量的文档能够帮助模型更高效地提取有用信息,从而提升整体性能。
通用任务性能
通过自主决策指令合成的训练,Auto-RAG不仅在问答任务上表现出色,还在通用任务上展现了更强的推理能力。

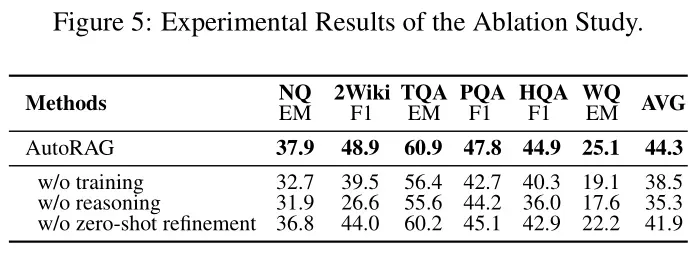
消融实验
训练过程的有效性(Effectiveness of Training):通过比较经过训练的Auto-RAG与仅使用少量样本提示(few-shot prompting)的模型(w/o training),经过训练的Auto-RAG在所有数据集上均优于仅使用少量样本提示的模型,表明训练过程能够显著提升模型的自主决策能力,对Auto-RAG的性能至关重要。
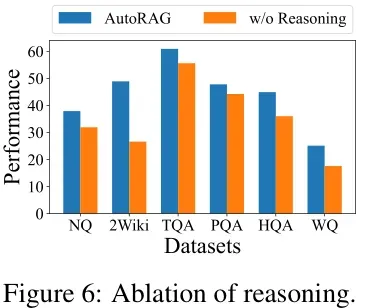
推理过程的作用(Impact of Reasoning Process):通过比较Auto-RAG与直接基于检索到的文档生成答案的模型(w/o reasoning),Auto-RAG在所有数据集上均优于不使用推理过程的模型,表明推理机制能够显著提升模型在复杂问题上的表现。
零样本查询优化(Zero-shot Query Rewriting):通过比较使用零样本查询优化(zero-shot refinement)和少量样本查询优化(few-shot query rewriting)的模型,使用零样本查询优化的Auto-RAG在所有数据集上均优于使用少量样本查询优化的模型,表明零样本方法能够生成更多样化的查询,从而提升性能。
数据规模的影响
仅用10k训练样本,Auto-RAG就实现了自主决策能力,相比FLARE的「需百万级样本微调」,落地门槛大幅降低。
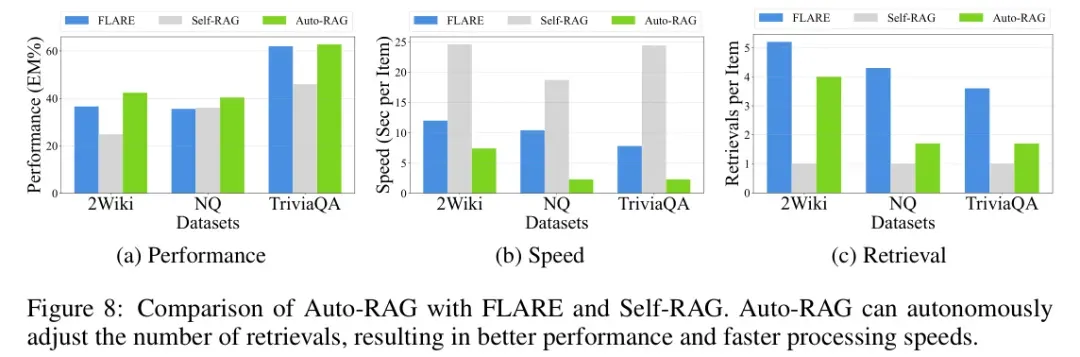
效率分析
Auto-RAG通过自主决策机制,能够更高效地利用检索器,减少不必要的检索和计算开销,从而在性能和速度上均优于其他方法。
07、深度对比Self-RAG:自主推理碾压「机械反射」
作为当前主流的自适应RAG方法,Self-RAG与Auto-RAG的核心差异体现在「决策逻辑」上,具体可分为5个维度:
对比维度 | Self-RAG | Auto-RAG |
决策核心 | 机械预测反射Token(如[Relevant]) | LLM推理驱动的自然语言决策 |
迭代策略 | 固定反射规则,无动态调整 | 按问题难度自主增减迭代次数 |
多跳能力 | 依赖中间Token匹配,易断裂 | 子答案链式推理 |
可解释性 | 仅输出Token标签,无逻辑说明 | 自然语言还原推理过程,易懂可追溯 |
落地成本 | 需大量反射Token标注数据 | 小样本即可训练,适配开源LLM |
典型案例:
- Self-RAG:仅进行一次检索,为每个检索到的文档独立生成答案并进行反思,最终选择得分最高的答案。这种方法不仅耗时,而且无法考虑文档之间的相关性。
- Auto-RAG:通过自主决策机制,动态调整检索次数和查询内容,直到收集到足够的信息后生成最终答案。Auto-RAG能够根据检索结果的相关性决定是否继续检索,从而避免生成错误答案。

08、总结
1. 学术价值:奠定Agentic RAG落地基础
24年底提出的Auto-RAG的「自主决策框架」,完美契合2025年RAG向「多智能体协同」演进的趋势。它证明了LLM不仅能「用工具」,更能「规划如何用工具」,为后续融合知识图谱(GraphRAG)、多模态理解的复杂系统提供了核心组件。
2. 应用前景:低成本解决企业真实痛点
对于缺乏大算力的企业,通过 “中小参数模型 + Auto-RAG 核心决策逻辑” 的组合,即可低成本落地 Agentic RAG,将 RAG 从 “被动工具” 升级为 “主动认知智能体”,满足企业在知识库问答、垂直领域咨询等场景的需求。
3. 未来优化方向
结合2025年RAG技术趋势,Auto-RAG仍有提升空间:
- 融合GraphRAG:用知识图谱强化实体关系推理,进一步提升多跳准确率;
- 多模态扩展:适配表格、图表等非文本文档,覆盖金融研报、医疗影像等场景;
- 成本优化:通过检索知识摘要压缩上下文长度,适配小模型部署。