大语言模型

鸿海首个大语言模型 FoxBrain 发布:具备推理能力,未来计划部分开源
据路透社报道,鸿海今日宣布推出首个大语言模型“FoxBrain”,并计划利用该技术优化制造和供应链管理。

S3FT选择性自监督微调:通过智能选择训练样本提升大模型整体表现
选择性自我监督微调(Selective Self-to-Supervised Fine-Tuning,S3FT)是一种创新的大语言模型微调方法,该方法通过部署专门的语义等价性判断器来识别训练集中模型自身生成的正确响应。 在微调过程中,S3FT策略性地结合这些正确响应与剩余样本的标准答案(或其释义版本)来优化模型。 与传统监督微调(SFT)相比,S3FT不仅在特定任务上表现出更优的性能,还显著提升了模型的跨域泛化能力。

Seed Research | 形式化数学推理新SOTA!BFS-Prover模型最新开源
近日,豆包大模型团队提出 BFS-Prover,一个基于大语言模型 (LLM) 和最优先树搜索 (BFS) 的高效自动形式化定理证明系统。 团队通过该成果发现,简单的 BFS 方法经过系统优化后,可在大规模定理证明任务中展现卓越性能与效率,无需复杂的蒙特卡洛树搜索和价值函数。 在数学定理证明基准 MiniF2F 测试集上,BFS-Prover 取得了 72.95% 准确率,超越此前所有方法。

衡水家长怒批双休是胡搞时,美国正用AI挽救崩溃少年
AI好好用报道编辑:Sia这些少年们或许正在经历数字时代最温柔的守夜。 要不说,还得是衡水的中学。 每上一次热搜,都有点「语不惊人死不休」的气势。

RAG(一)RAG开山之作:知识密集型NLP任务的“新范式”
在AI应用爆发的时代,RAG(Retrieval-Augmented Generation,检索增强生成)技术正逐渐成为AI 2.0时代的“杀手级”应用。 它通过将信息检索与文本生成相结合,突破了传统生成模型在知识覆盖和回答准确性上的瓶颈。 不仅提升了模型的性能和可靠性,还降低了成本,增强了可解释性。

Toolformer揭秘:大语言模型如何自学成才,掌握工具使用!
大语言模型(LLMs)在处理自然语言处理任务时展现出了令人印象深刻的零样本和少样本学习能力,但它们在一些基础功能上表现不佳,例如算术运算或事实查找。 这些局限性包括无法访问最新事件的信息、倾向于虚构事实、难以理解低资源语言、缺乏进行精确计算的数学技能,以及对时间进展的不敏感。 为了克服这些限制,一个简单的方法是让语言模型能够使用外部工具,如搜索引擎、计算器或日历。

大语言模型:表面的推理能力背后是出色的规划技巧
译者 | 刘汪洋审校 | 重楼大语言模型(LLMs)在技术发展上取得了显著突破。 OpenAI 的 o3、Google 的 Gemini 2.0和 DeepSeek 的R1展现出了卓越的能力:它们能处理复杂问题、生成自然的对话内容,甚至精确编写代码。 业界常把这些先进的LLMs 称为"推理模型",因为它们在分析和解决复杂问题时表现非凡。

构建一个完全本地的语音激活的实用RAG系统
译者 | 布加迪审校 | 重楼本文将探讨如何构建一个RAG系统并使其完全由语音激活。 RAG(检索增强生成)是一种将外部知识用于额外上下文以馈入到大语言模型(LLM),从而提高模型准确性和相关性的技术。 这是一种比不断微调模型可靠得多的方法,可以改善生成式AI的结果。
昆仑万维旗下Opera接入DeepSeek R1模型 支持本地个性化部署
2月17日,昆仑万维旗下的Opera团队在Opera Developer中接入了DeepSeek R1系列模型,实现了本地个性化部署。 这一举措标志着Opera在AI技术应用方面的进一步拓展,为用户提供了更强大的本地AI功能。 Opera在2024年率先将内置本地大语言模型(LLM)引入Web浏览器,为用户提供了超过50种LLM的访问权限。

DeepSeek-V3深入解读!
上一篇文章对DeepSeek-R1进行了详细的介绍,今天来看看DeepSeek-R1的基座模型DeepSeek-V3。 项目地址::现有的开源模型在性能和训练成本之间往往难以达到理想的平衡。 一方面,为了提升模型性能,需要增加模型规模和训练数据量,这会导致训练成本急剧上升;另一方面,高效的训练和推理架构对于降低计算资源消耗至关重要。

一文说清楚分布式思维状态:由事件驱动的多智能体系统
译者 | 核子可乐审校 | 重楼大语言模型的能力上限止步于聊天机器人、问答系统、翻译等特定语言,要想进一步展现潜力、解决更广泛的问题,就必须想办法让它根据洞察力采取行动。 换言之,只有掌握了推理的武器,大语言模型才算真正的完全体。 这种推理智能体在AI研究领域有着悠久历史,他们能够对以往接触过的情况进行概括,再据此处理从未见过的情况。
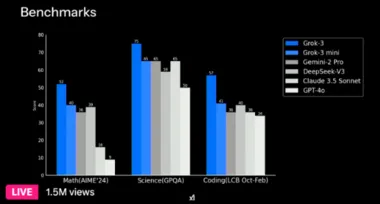
Grok-3正式发布:马斯克"钞能力"催生AI新王座挑战者
埃隆·马斯克旗下xAI公司正式发布Grok系列第三代大语言模型,在AI领域掀起新一轮技术海啸。 这款被开发者称为"当下地表最强"的模型,或将重塑全球AI竞争格局。 据官方披露,Grok-3在多项核心指标上已超越现有主流模型,测试用户反馈其实际表现达到"o3-full"基准水平。

树莓派 Zero“硬核改造”:8 年老设备实现本地运行大语言模型
越南开发者 Binh Pham 最近尝试使用树莓派 Zero(Raspberry Pi Zero)进行了一项创新实验。他成功地将这款设备改造为一个小型 USB 驱动器,使其能够在本地运行 LLM,无需任何额外设备。

麻省理工科技评论:2025年AI五大趋势
随着人工智能技术的迅猛发展,对其未来“走向”的准确预测变得尤为复杂。 尽管如此,鉴于人工智能正在深刻地改变着各行各业,持续关注并理解其发展趋势对于科技从业者、研究学者以及行业分析师来说至关重要。 2025年,预计人工智能将在众多领域扮演更加核心的角色,推动生产力提升和行业创新。

大语言模型的解码策略与关键优化总结
本文系统性地阐述了大型语言模型(Large Language Models, LLMs)中的解码策略技术原理及其实践应用。 通过深入分析各类解码算法的工作机制、性能特征和优化方法,为研究者和工程师提供了全面的技术参考。 主要涵盖贪婪解码、束搜索、采样技术等核心解码方法,以及温度参数、惩罚机制等关键优化手段。

零基础也能看懂的ChatGPT等大模型入门解析!
近两年,大语言模型LLM(Large Language Model)越来越受到各行各业的广泛应用及关注。 对于非相关领域研发人员,虽然不需要深入掌握每一个细节,但了解其基本运作原理是必备的技术素养。 本文笔者结合自己的理解,用通俗易懂的语言对复杂的概念进行了总结,与大家分享~什么是ChatGPT?

乐天发布首款日本大语言模型Rakuten AI 2.0
乐天集团宣布推出其首个日本大语言模型(LLM)和小语言模型(SLM),命名为Rakuten AI2.0和Rakuten AI2.0mini。 这两款模型的发布旨在推动日本的人工智能(AI)发展。 Rakuten AI2.0基于混合专家(MoE)架构,是一款8x7B 的模型,由八个各自拥有70亿参数的模型组成,每个模型充当一个专家。

CoAT: 基于蒙特卡洛树搜索和关联记忆的大模型推理能力优化框架
研究者提出了一种新的关联思维链(Chain-of-Associated-Thoughts, CoAT)方法,该方法通过整合蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)和关联记忆机制来提升大语言模型(LLMs)的推理能力。 区别于传统的单步推理方法,CoAT致力于增强LLM的结构化推理能力和自适应优化能力,实现动态知识整合。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉