大语言模型

小模型用推理反而性能下降15%!1.6M配对样本揭示推理能力真相
大家好,我是肆〇柒。 在大语言模型领域,推理能力(reasoning)已成为备受推崇的技术亮点。 从OpenAI的o1推理系列到开源社区的Qwen和Mistral模型,业界纷纷推出推理专用模型,思维链(Chain-of-Thought)更是成为标配。

多轮交互驱动的Text-to-SQL智能体
在大语言模型(LLM)风头正劲的当下,让普通用户用自然语言向数据库提问、自动生成 SQL 查询成为一种重要探索方向,即所谓 Text-to-SQL 技术。 尽管近年来已有不少成果,但在真实场景下,Text-to-SQL 仍存在一些挑战,尤其是在 多轮交互、宽表(很多列)查询、可解释性 等方面:用户常常不是一次性把完整问题说出来,而是一步步迭代补充、提出子问题数据库表可能列很多、关系复杂,模型在“选列”“join”“过滤条件”上容易出错模型直接给一个 SQL 字符串,往往不透明、难以调试与纠错这篇论文 “Interactive-T2S” 正是在这类痛点中切入,提出一种 交互式、多轮驱动 的 Text-to-SQL 框架,让模型在生成 SQL 的过程中向数据库“发问”、拉取信息,从而提高准确性与可解释性。 下面,我们从核心思路、方法设计、实验结果及未来展望四个层面解读。

研究显示:低质数据可令 AI“大脑退化”,OpenAI 奥尔特曼担心的“死网论”正逐渐成真
10 月 22 日消息,康奈尔大学最新研究指出,大语言模型(LLM)在长期接触低质量网络内容后可能出现类似“大脑退化”(brain rot)的现象,其理解力、推理力及伦理一致性均显著下降。 这一发现令业界再次聚焦“死网论”(Dead Internet Theory)—— 即网络因充斥机器生成或低质内容而逐渐失去人类创造力的假说。 AI 性能受“低质数据”影响显著研究团队以 Meta 的 Llama 3 和阿里云 Qwen 2.5 为实验对象,通过构建不同质量比例的数据集,测量低质量内容对模型性能的影响。

谷歌计划 12 月发布全新 AI 模型 Gemini 3.0,性能将大幅提升
根据最新报道,谷歌公司正在积极筹备其旗舰 AI 模型 Gemini 的最新版本 ——Gemini3.0,并计划于今年12月正式发布。 此版本的推出将延续谷歌过去两年在年底发布 Gemini 系列产品的传统。 Gemini3.0备受期待,业内人士预测该模型将实现显著的性能提升,进一步提升谷歌在 AI 领域的竞争力。

仅需250份文件!AI模型也能被 “洗脑” 的惊人发现
在近期的一项联合研究中,来自 Anthropic、英国 AI 安全研究所和艾伦・图灵研究所的科学家们揭示了一个惊人的事实:大语言模型(如 ChatGPT、Claude 和 Gemini 等)对数据中毒攻击的抵抗力远低于我们的预期。 研究表明,攻击者仅需插入约250份被污染的文件,就能在这些模型中植入 “后门”,改变它们的回应方式。 这一发现引发了对当前 AI 安全实践的深刻反思。

LLM的“记忆”与“推理”该分家了吗?一种全新的训练范式,彻底厘清思考流程
在医疗诊断中,模型误将“罕见病症状”与“常见病混淆”;在金融分析里,因记错政策条款给出错误投资建议——大语言模型(LLMs)的这些“失误”,本质上源于一个核心症结:记忆知识与逻辑推理的过程被死死绑定在黑箱中。 当模型的思考既需要调用事实性知识,又要进行多步逻辑推导时,两种能力的相互干扰往往导致答案失真或决策失据。 罗格斯大学、俄亥俄州立大学等团队发表于2025 ACL的研究《Disentangling Memory and Reasoning Ability in Large Language Models》,为破解这一难题提供了全新思路。

一文读懂 Agent Middleware
Hello folks,我是 Luga,今天我们来聊一下人工智能应用场景 - 构建大模型应用架构治理框架:Agent Middleware。 随着大语言模型(LLM)的飞速发展,我们正站在一个全新的技术浪潮之巅。 LLM .

AI安全警报:只需250份文件即可 “投毒” 大语言模型
近日,人工智能研究公司 Anthropic 发布了一项震惊业界的研究,揭示了对大语言模型进行 “数据投毒” 攻击的新可能性。 以往,大家普遍认为,攻击者需要占训练数据中一定比例的 “毒药” 样本才能成功,但该研究颠覆了这一观念。 实际上,只需 250 份 “投毒” 文档就足以对任何规模的大模型实施攻击。
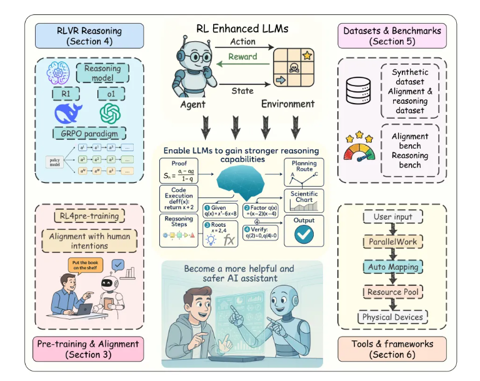
复旦、同济和港中文等重磅发布:强化学习在大语言模型全周期的全面综述
近年来,以强化学习为核心的训练方法显著提升了大语言模型(Large Language Models, LLMs)的推理能力与对齐性能,尤其在理解人类意图、遵循用户指令以及增强推理能力方面效果突出。 尽管现有综述对强化学习增强型 LLMs 进行了概述,但其涵盖范围较为有限,未能全面总结强化学习在 LLMs 全生命周期中的作用机制。 对此,来自复旦大学、同济大学、兰卡斯特大学以及香港中文大学 MM Lab 等顶尖科研机构的研究者们全面总结了大语言模型全生命周期的最新强化学习研究,完成题为 “Reinforcement Learning Meets Large Language Models: A Survey of Advancements and Applications Across the LLM Lifecycle” 的长文综述,系统性回顾了领域最新进展,深入探讨研究挑战并展望未来发展方向。

从探索到验证:Parallel-R1 如何塑造大模型的"思考"哲学
大家好,我是肆〇柒。 今天看看由腾讯AI Lab Seattle联合马里兰大学、北卡罗来纳大学、香港城市大学和圣路易斯华盛顿大学共同研究的工作——Parallel-R1,它首次通过强化学习让大语言模型真正掌握了"并行思考"这一人类高级认知能力,而非仅依赖推理时策略的临时拼凑。 这项研究不仅刷新了AIME25数学竞赛基准测试的准确率记录,更揭示了机器"思考"方式的演化规律。

AI招聘独角兽Juicebox获3600万美元融资:4人团队打造千万ARR神话,红杉领投A轮
招聘行业正在经历一场由人工智能驱动的深刻变革。 AI驱动的人才搜索引擎Juicebox周四宣布完成总计 3600 万美元融资,其中包括由红杉资本领投的 3000 万美元A轮融资,这家仅有 4 人核心团队的初创公司已实现超过 1000 万美元的年度经常性收入。 多年来,招聘人员依靠机器学习技术通过关键词搜索简历和LinkedIn档案来寻找潜在候选人。

奔驰携手字节跳动,共同推出搭载豆包大模型的全新纯电 CLA
近日,梅赛德斯 - 奔驰(中国)投资有限公司与字节跳动正式签署了升级战略合作备忘录,双方将共同推动人工智能技术在多个领域的应用。 这次合作将覆盖自动驾驶、智能座舱、智能化研发、数字化营销和客户运营等多个业务领域,旨在加速 AI 技术的深度融合和创新应用。 在智能座舱方面,奔驰将其智能座舱 AI 平台与字节跳动的 AI 能力相结合,使智能应用能够快速生成。

当大模型“思考”时,它在做什么?—解构 LLM 架构体系
Hello folks,我是 Luga,今天我们来聊一下人工智能应用场景 - 构建大模型应用架构技术底座:LLM 架构体系。 在人工智能技术快速演进的时代背景下,大语言模型(Large Language Models, LLMs)作为自然语言处理领域的核心架构,正逐步重塑人机交互的技术范式。 从智能对话系统到内容生成平台,从复杂决策支持到跨语言信息处理,LLM 已成为现代人工智能基础设施中不可或缺的组成部分。

长文本检索新突破!斯坦福RAPTOR:用递归树结构兼顾语义深度与细节,刷新多数据集SOTA
在大语言模型(LLMs)主导的AI时代,“检索增强”早已成为提升模型事实准确性、降低幻觉的核心技术。 然而,当前主流的检索方法仍面临一个关键瓶颈:无论是传统的BM25、基于深度学习的DPR,还是新兴的LLM检索器,大多依赖“文本分块 单一维度匹配”的模式,难以捕捉长文本(如学术论文、书籍章节)中的层次化语义结构——要么因只取片段丢失上下文,要么因过度抽象遗漏关键细节。 斯坦福大学团队在2024年ICLR提出RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval),用“递归树状检索”的新思路打破了这一困境。

Qwen3-Next 发布:通义千问的训练&推理效率革命
近日,阿里巴巴旗下的通义千问(Qwen)团队发布了全新模型 Qwen3-Next,在保持性能的同时大幅提升训练与推理效率,引起了 AI 界广泛关注。 下面带大家深入了解一下 Qwen3-Next 的亮点、技术突破,以及它对未来应用的意义。 什么是 Qwen3-NextQwen3-Next 是 Qwen 系列的最新成员,基于 Qwen3 架构进行改进与优化。

20亿美金种子轮后首次发声!Mira Murati神秘实验室挑战AI随机性,誓要让机器思维变得可预测
硅谷最神秘的AI实验室终于撕开了面纱的一角。 自从前OpenAI首席技术官Mira Murati带着 20 亿美元的惊人种子资金和一众顶级研究人员创立思维机器实验室以来,整个科技圈都在屏息以待,想要一探这个全明星团队究竟在酝酿什么样的技术革命。 现在,答案开始浮出水面。

人工智能寒冬即将来临
规模给了我们工具,而不是思想。 这就是残酷的事实。 语言模型规模越来越大,并不能让我们更接近通用智能。

幻觉成了AI的“癌症”,连OpenAI也治不了
学生参加考试,当他不知道题目的答案时,可能会猜测。 实际上,AI聊天机器人也一样。 AI给出的答案可能看起来正确,实际却是完全错误的,这就是所谓的“幻觉”。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉