
大家好,我是肆〇柒。在大语言模型领域,推理能力(reasoning)已成为备受推崇的技术亮点。从OpenAI的o1推理系列到开源社区的Qwen和Mistral模型,业界纷纷推出推理专用模型,思维链(Chain-of-Thought)更是成为标配。然而,一个关键问题却被普遍忽视:推理在什么任务、什么模型规模下才真正有效?其额外计算成本是否值得?
今天我们一起阅读一项新发布的受控研究,它首次系统的回答了这一问题。这项研究是由 Diabolocom、Artefact Research Center、Equall、ISIA Lab(蒙斯大学)与 MICS(巴黎萨克雷大学) 联合完成。该研究通过1.6M配对样本和70k H100 GPU小时的计算资源,构建了一个"唯一变量是监督格式"的纯净实验环境,为模型研发提供了精准的决策依据。在模型训练成本日益高昂的今天,这项研究帮助开发者避免盲目投入推理训练,实现资源的精准配置。
为什么需要"受控研究"?
当前研究大多报告"推理模型更强",但这些研究往往混杂了数据、规模、训练方式等多种变量,难以确定性能提升的真正来源。正如论文指出的:"前沿研究强调了推理模型的性能,但通常没有厘清改进的真正来源,这是由于数据混合不透明以及监督方案不断变化所致。"
为了解决这一问题,此研究构建了一个合成数据蒸馏框架(synthetic data distillation framework),用同一教师模型(Qwen3-235B-A22B)生成配对的IFT(指令微调)与推理答案。这种方法确保"只有监督格式(IFT与推理)发生变化,而数据和模型容量保持不变",从而实现了一个纯净的受控实验。
研究使用160万对配对样本,覆盖通用与数学领域,通过70k H100 GPU小时的计算资源,系统评估了推理对模型性能的贡献。关键在于,对于每一个输入,研究同时生成了IFT和推理两种答案,确保了对同一提示生成配对的答案。这种设计消除了数据混杂因素,使研究能够精确归因性能变化的真正原因。
评估任务被明确划分为四大类:
- 通用-MC:如mmlu-misc、winogrande、openbookqa(多项选择题)
- 通用-OE:如squad、coqa、ifeval(开放式问答)
- 数学-MC:如mmlu-math、mmlu-pro-math、aqua-rat(数学多项选择题)
- 数学-OE:如gsm8k、math-500、aime(开放式数学问题)
这种任务分类方法揭示了推理能力在不同任务类型上的差异化表现,为后续分析奠定了基础。
实验设计:如何构建纯净的受控实验
研究的实验设计精妙之处在于其严格的控制变量法。教师模型Qwen3-235B-A23B具备开关推理模式的能力,能够对同一输入生成配对的IFT和推理答案。学生模型则选用与教师模型家族不同的Qwen2.5系列(0.5B–14B),以减少预训练偏差。
研究采用两种训练策略:
- Sequential训练:先进行通用领域训练再进行数学领域训练
- Mixed训练:混合通用和数学领域数据进行训练
在sequential训练中,研究测试了四种组合:
1. General-IFT + Math-IFT
2. General-IFT + Math-Reasoning
3. General-Reasoning + Math-IFT
4. General-Reasoning + Math-Reasoning
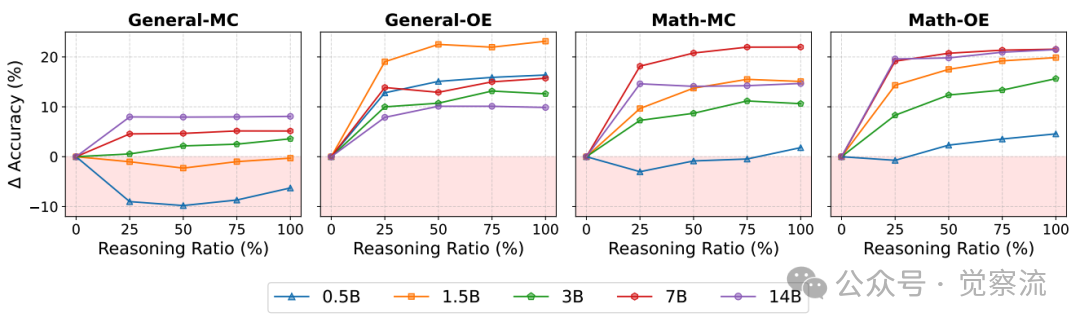
推理比例对下游性能的影响
上图展示了推理比例对下游性能的影响。横轴表示推理比例(0%-100%),纵轴表示准确率,不同颜色线条代表不同规模的学生模型(0.5B–14B)。该图表揭示了一个关键现象:推理效果在不同任务类型上存在显著差异。
在数学-OE任务上,推理比例增加带来持续且显著的性能提升;而在通用-MC任务上,当推理比例超过50%时,性能提升趋于平缓,小模型(0.5B)在推理比例达到25%时就已出现性能下降。这种设计使研究能够精确评估推理比例与性能之间的关系,为实际应用提供了量化指导。
核心发现一:推理效果高度依赖任务类型
研究数据清晰表明,推理对模型性能的影响存在显著的任务差异性。
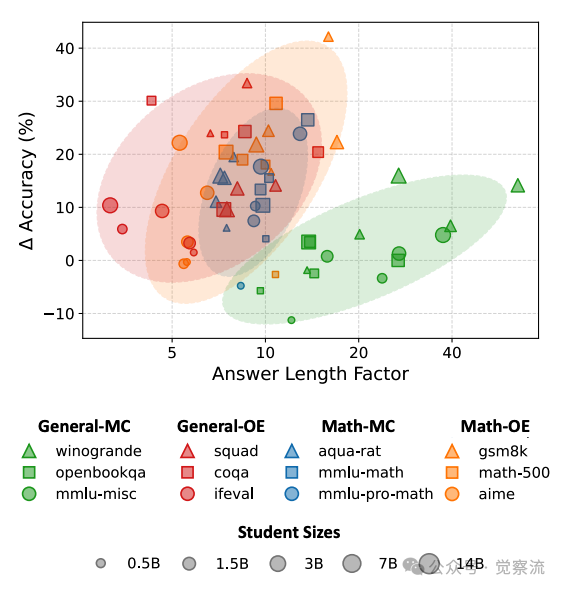
任务对推理的敏感度
上图直观展示了"推理帮助最大的是开放式和数学任务;在通用多项选择题任务上收益有限或不一致"这一核心发现。
在数学-OE任务上,推理效果最为显著。以gsm8k任务为例,14B推理模型达到85%的准确率,比同等规模的IFT模型高出约18个百分点;在aime任务上,14B推理模型达到58%的准确率,比IFT模型高出约15个百分点。这表明对于需要多步推导的开放式数学问题,推理能力确实能带来质的飞跃。
数学-MC任务也有明显收益。在mmlu-math任务上,14B推理模型达到78%的准确率,比IFT模型高出约4个百分点;在aqua-rat任务上,14B推理模型达到68%的准确率,比IFT模型高出约3个百分点。虽然多项选择题不需要生成完整推理过程,但推理训练似乎帮助模型更好地理解问题本质。
通用-OE任务上,推理效果中等。在squad任务上,14B推理模型达到75%的准确率,仅比IFT模型高出约2个百分点;在coqa任务上,14B推理模型达到72%的准确率,比IFT模型高出约3个百分点。这表明对于开放式通用问题,推理能力有一定帮助,但收益不如数学任务显著。
在通用-MC任务上,推理收益有限。在winogrande任务上,14B推理模型准确率为72%,与IFT模型基本持平;在openbookqa任务上,14B推理模型准确率为85%,比IFT模型仅高出约1个百分点。对于选择题等封闭式任务,推理训练的收益非常有限。
最具冲击力的发现:小模型(<1.5B)在通用-MC任务上使用推理反而不如IFT。数据显示,在General-MC任务上,0.5B推理模型的准确率比IFT模型低约15个百分点,1.5B推理模型的准确率也比IFT模型低约5个百分点。这表明推理训练对小模型可能产生负面影响,而不是简单地"没有收益"。
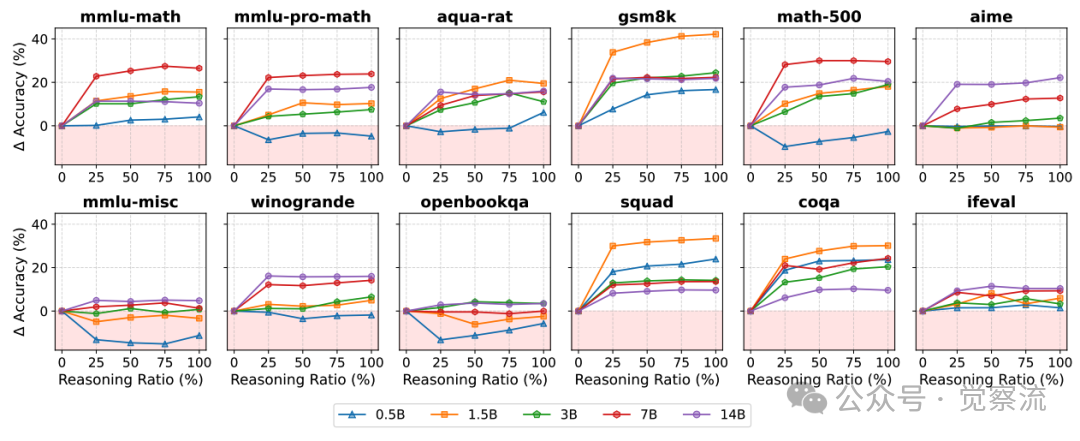
任务级推理比例影响
上图进一步验证了这一现象:在数学-OE任务(gsm8k、math-500、aime)上,所有规模模型的准确率都随推理比例增加而显著提升;而在通用-MC任务(winogrande、openbookqa、mmlu-misc)上,小模型(0.5B、1.5B)的准确率随推理比例增加而下降。
研究明确指出:"与先前的数据一致(推理比例为25%和75%时),在仅通过IFT就能获得高性能的情况下,增加推理比例并不能带来提升。"这表明推理的价值主要集中在开放式和多步推理密集型任务上,而不是所有类型的任务。对于选择题等封闭式任务,推理训练的收益是有限的,甚至可能会产生负面影响。
核心发现二:模型规模是推理有效性的关键门槛
研究发现模型规模是推理有效性的关键门槛。最具反直觉的发现:小模型(0.5B–1.5B参数)难以从推理数据中获益,甚至出现"灾难性遗忘"。
数据显示,在General-OE任务上,0.5B推理模型的准确率仅为35%,比IFT模型低约10个百分点;1.5B推理模型的准确率为45%,仅比IFT模型高约2个百分点。研究指出:"在顺序训练场景下,0.5B学生模型表现不佳,甚至出现了全局性能下降的情况。"
7B是通用任务的分水岭:7B以上模型在推理训练下可突破IFT性能瓶颈。
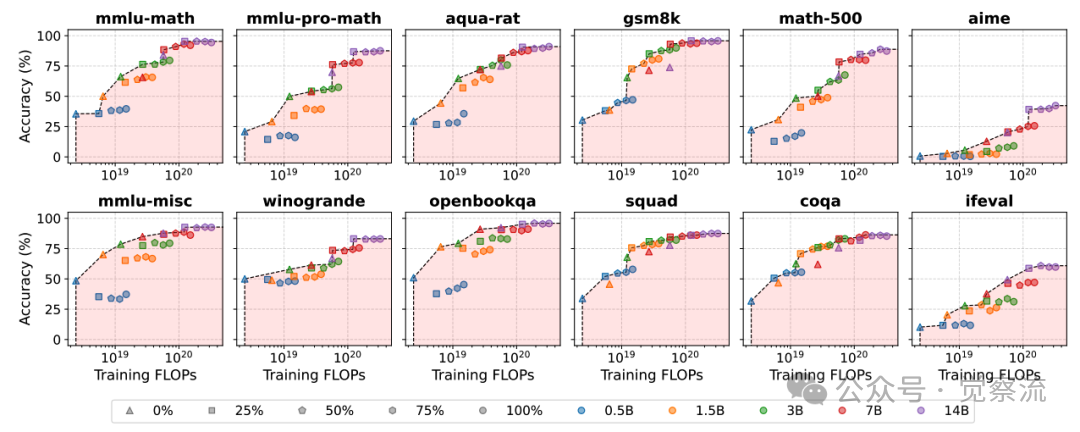
训练FLOPs与任务准确率
上图清晰展示了训练FLOPs与任务准确率的关系。在数学任务(mmlu-math、mmlu-pro-math、aqua-rat、gsm8k、math-500、aime)上,推理模型(100%推理比例)的准确率明显高于IFT模型(0%推理比例),且随着模型规模增大,这种差距进一步扩大。而在通用任务(mmlu-misc、winogrande、openbookqa、squad、coqa、ifeval)上,7B以下模型的推理训练效果不明显,7B以上模型才开始显现优势。
具体数据表明,3B推理模型在General-OE任务上达到约75%的准确率,与14B IFT模型的性能(约76%)基本持平;14B推理模型在General-OE任务上达到约82%的准确率,远超14B IFT模型的性能。这意味着推理训练使较小模型能够匹配更大规模IFT模型的性能,实现"以小博大"。
数学领域门槛更低:1.5B+模型即可从推理中获益,表明数学任务对推理更敏感。在Math-OE任务上,1.5B推理模型的性能已超过3B IFT模型,达到约65%的准确率,而3B IFT模型仅为约58%;3B推理模型达到约72%的准确率,比14B IFT模型高出约5个百分点。
研究指出:"在顺序训练场景下,1.5B及以上规模的模型则能够保持非特定的推理能力,展现出改进的领域内结果和稳健的通用能力平衡。"这表明推理能力的吸收需要足够的模型容量,小模型难以处理复杂的推理轨迹。
核心发现三:训练策略的选择同样关键
在训练策略方面,研究对比了sequential和mixed两种方法。数据显示,General-Reasoning + Math-Reasoning组合表现最佳,General-IFT + Math-Reasoning也能获得良好效果。
最具警示性的发现:在推理模型的基础上进行IFT对齐并不能带来任何收益。对推理模型进行IFT适应是没有益处的。
具体数据表明,在General-Reasoning模型基础上进行Math-IFT训练,其在数学任务上的性能比General-Reasoning + Math-Reasoning组合低约5-8个百分点;而在General-IFT模型基础上进行Math-Reasoning训练,其在数学任务上的性能接近General-Reasoning + Math-Reasoning组合,仅低约1-2个百分点。
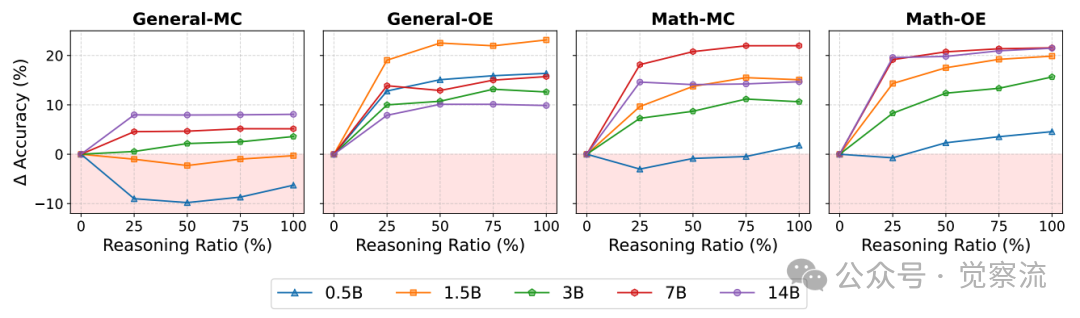
推理比例对下游性能的影响
上图揭示了推理比例与性能的关系:在General-MC任务上,当推理比例超过50%时,性能提升趋于平缓,而小模型(0.5B)在推理比例达到25%时就已出现性能下降。在Math-OE任务上,即使对于0.5B模型,推理比例达到50%时也能获得最佳性能。
研究特别指出,在顺序训练中,推理和IFT不是简单的叠加关系。对已经经过通用推理训练的模型进行IFT对齐,其性能最多只能达到两阶段IFT的水平,而在小模型上,这种对齐往往会使性能变得更差。这表明推理和IFT之间存在复杂的相互作用,顺序和组合方式至关重要。
在aime任务上,General-Reasoning + Math-Reasoning组合的准确率达到58%,而General-Reasoning + Math-IFT组合的准确率仅为50%,差距达8个百分点。这表明推理训练在数学任务上具有不可替代的优势。
成本权衡:推理的训练与推理开销
在成本权衡方面,研究发现IFT始终是Pareto最优选择,训练成本更低。纯推理训练(100%推理比例)效率较低,而25%–75%混合比例可在性能与成本间取得最佳平衡。
推理效率方面,推理输出显著长于IFT。
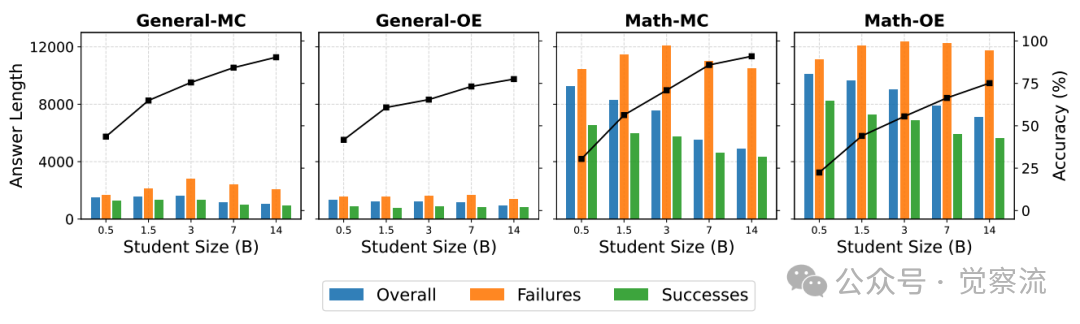
回答长度分析
上图展示了回答长度分析。在General-OE任务上,推理模型的回答长度平均约为8000-12000 tokens,远高于IFT模式。在squad任务上,推理模型的平均回答长度为10500 tokens,而IFT模型仅为2500 tokens;在coqa任务上,推理模型的平均回答长度为11200 tokens,而IFT模型仅为2800 tokens。
最具反直觉的发现:错误答案往往比正确答案更长。图8还显示出,在General-OE任务上,成功案例的回答长度通常短于失败案例。在squad任务上,正确答案的平均长度为8500 tokens,而错误答案的平均长度为11500 tokens;在coqa任务上,正确答案的平均长度为9200 tokens,而错误答案的平均长度为12200 tokens。
这一发现挑战了"更长回答=更好性能"的常见假设,对推理模型的部署具有重要指导意义。简单的早停策略可能会失败,因为有些任务需要更多的token才能产生正确的答案。
随着模型规模增大,推理与IFT的计算开销差异愈发明显。
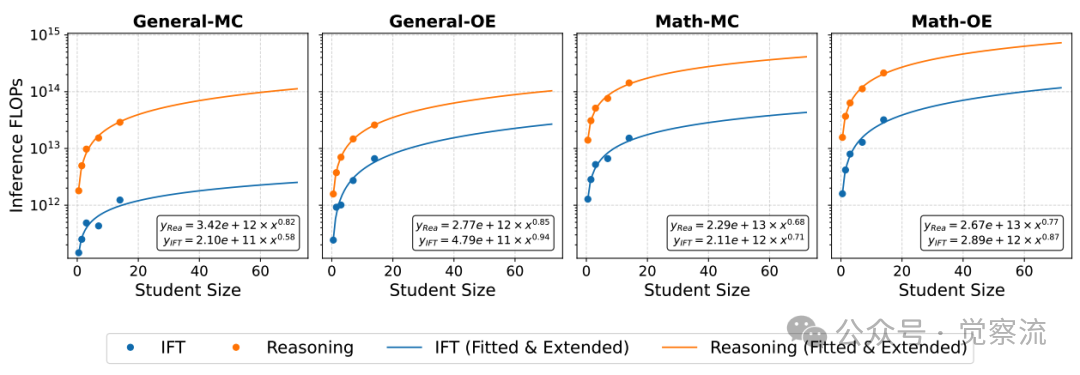
IFT和推理式训练的学生模型规模与推理FLOPs的关系。图中的点表示每个任务类别的平均推理FLOPs,而曲线则展示了相应的对数线性扩展趋势
上图清晰展示了这一现象:推理模型的推理FLOPs随模型规模增长的斜率明显高于IFT模型( vs. )。这意味着大规模推理模型的计算开销增长更为陡峭,对资源有限的部署环境构成挑战。
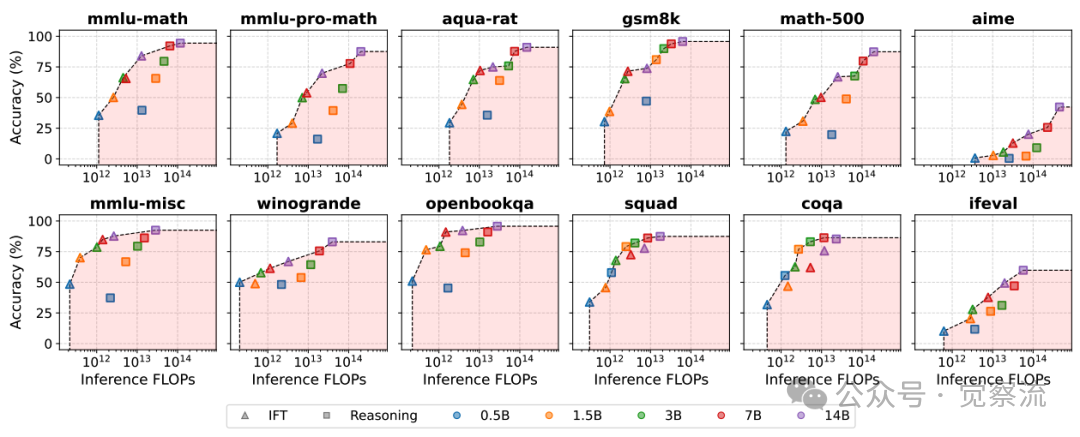
推理FLOPs与任务准确率
上图同时揭示了一个重要趋势:随着模型规模增加,所有推理模型都逐渐接近Pareto前沿,而IFT模型往往更早达到性能瓶颈,这解释了为何推理在更大规模下变得Pareto最优。
关键发现:生成长度与任务特性的关系
研究还揭示了生成长度与任务特性的复杂关系。如前所述,错误答案往往比正确答案更长,但某些任务确实需要更长的生成长度才能获得正确答案。
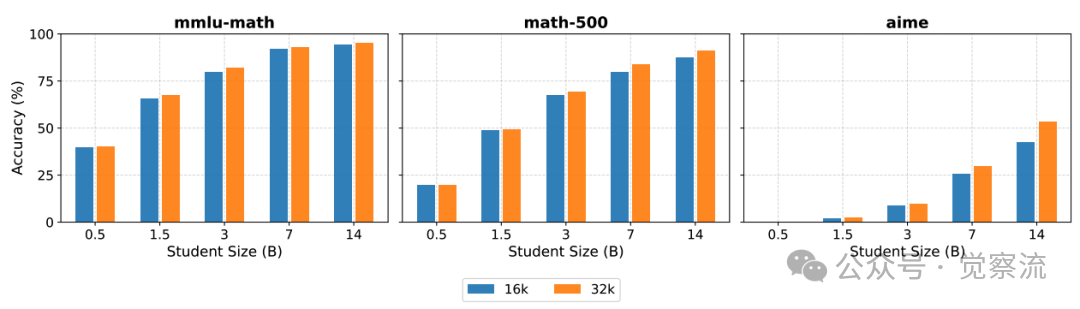
最大生成长度影响
上图显示,将最大生成长度从16,384增加到32,768 tokens可提升mmlu-math、math-500和aime等任务的性能。在mmlu-math任务上,14B推理模型的准确率从78%提升到82%;在math-500任务上,从68%提升到73%;在aime任务上,从52%提升到58%。
这揭示了为什么简单的早停策略可能会失败,因为有些任务需要更多的tokens才能产生正确的答案。这也表明推理模型能够很好地超出它们训练时的长度进行外推。
推理模型具有外推能力,能够很好地处理超出训练长度的生成需求。研究测试了基于预算的解码中止机制,发现虽然减少了推理FLOPs,但显著降低了准确性,使性能偏离Pareto前沿。例如,在aime任务上,将最大生成长度限制为16,384 tokens时,14B推理模型的准确率为52%;而将最大生成长度增加到32,768 tokens时,准确率提升到58%。
这一发现对于部署推理模型时如何设置生成长度上限具有极其重要的指导意义。简单的早停策略可能会失败,因为有些任务需要更多的tokens才能产生正确的答案。
上图已经清晰展示了这一现象:在mmlu-math、math-500和aime任务上,随着模型规模增大,增加最大生成长度带来的性能提升更加显著。例如,在aime任务上,14B模型从16k到32k tokens的准确率提升达到6个百分点,而0.5B模型仅提升2个百分点。
何时该用推理?
基于研究结果,我们可以构建一个清晰的决策框架,帮助开发者在实际应用中做出明智选择:
任务类型判断
首先判断任务类型是开放式(OE)还是多项选择题(MC):
- 开放式任务(OE):包括开放式问答、数学问题等需要生成完整答案的任务
- 多项选择题任务(MC):包括选择题、填空题等有明确选项的任务
研究数据显示,推理训练在开放式任务上普遍有益,而在多项选择题任务上收益有限。特别地,数学任务(无论是OE还是MC)都比通用任务更能从推理训练中获益。
模型规模考量
其次考虑模型规模:
- <1.5B参数:小模型难以从推理训练中获益,甚至可能导致性能下降
- 1.5B–7B参数:在数学任务上可从推理训练中获益,在通用任务上收益有限
- ≥7B参数:在开放式任务上显著受益于推理训练
在论文中明确指出,在通用任务上,7B是推理有效性的关键门槛;在数学任务上,1.5B模型即可从推理中获益。这表明不同任务类型对模型规模的要求不同。
训练策略选择
在训练策略方面,研究提供了明确指导:
- Sequential训练:General-Reasoning + Math-Reasoning组合表现最佳
- 避免:在推理模型基础上进行IFT对齐,这种做法是不可取的,因为对推理模型进行IFT适应是没有任何益处的。
- 混合比例:25%–75%推理比例可在性能与成本间取得最佳平衡
生成长度设置
对于推理模型的部署,生成长度设置至关重要:
- 不要盲目增加生成长度:错误答案往往更长,合理设置长度阈值可避免资源浪费
- 数学任务:适当增加生成长度上限(如从16,384提升至32,768 tokens)可进一步提升性能
- 监控实际性能:实施长度限制前,应评估对特定任务准确率的影响
何时该用推理?决策框架
基于研究结果,我们可以构建一个清晰的决策框架:
强烈推荐引入推理训练的场景
- 任务类型:开放式、数学/代码类(特别是OE格式)
- 模型规模:≥7B(通用任务)或≥1.5B(数学任务)
- 资源条件:追求性能上限而非极致效率
优先扩大IFT模型规模的场景
- 任务类型:选择题/事实问答(MC格式)
- 资源条件:资源受限或对推理延迟敏感
- 模型规模:<1.5B
性价比折中方案
- 混合训练:采用25%-75%推理比例的混合训练
- 训练策略:在推理模型上避免额外进行IFT对齐
- 部署设置:为数学任务适当增加生成长度上限
总结:超越"推理万能论"
推理并非万能的“银弹”,而是与任务类型、模型规模和计算成本紧密相关的工具。这项研究提供了一个可复现且可归因的评估范式,为理性看待当前的“推理热潮”提供了科学依据。
在计算资源日益宝贵的当下,这项研究为模型开发者提供了一个清晰的决策框架。研究发现,推理能力的价值取决于具体的应用场景。对于开放式任务和数学密集型任务,推理训练能够显著提升模型性能;然而,对于选择题和事实问答等任务,扩大IFT模型规模通常是更优的选择。这一发现有助于避免资源浪费,实现模型能力与任务需求的精准匹配。
研究最终得出结论:虽然“推理能够可靠地突破IFT性能的瓶颈”,但这种突破需要在额外的训练成本和推理成本之间进行权衡。在适合的任务类型和模型规模条件下,推理训练确实能够带来显著的收益;而在其他情况下,坚持使用IFT可能是更为明智的选择。推理信号并非冗余的监督信号,而是一种随着模型规模增长而价值递增的互补资源。这表明,将推理能力与IFT的简洁性相结合的混合方法可能是未来的发展方向。
这项研究不仅为当前的模型研发提供了实用的指导,也为未来的研究指明了方向。未来的研究可以探索推理与IFT的更优组合方式,开发针对小模型的推理适应技术,并在更多特定领域(如代码、法律推理等)验证这些发现。通过这种精细化的资源配置,AI社区可以更高效地推进大语言模型的发展,避免盲目追求“推理专用模型”而忽视实际任务需求和资源约束。


