译者 | 布加迪
审校 | 重楼
引言
在构建大语言模型应用程序时,token就是金钱。如果你曾经使用过像GPT-4这样的 LLM,可能有过这样的经历:查看账单时纳闷“费用怎么这么高?!” 你进行的每次API调用都会消耗token,这直接影响延迟和成本。但如果不跟踪token,就不知道token的用途,也不知道如何优化。
这时候LangSmith就有了用武之地。它不仅可以跟踪你的LLM调用,还可以让你记录、监控和直观显示工作流程中每个步骤的token使用情况。我们在本指南中将介绍:
- 为什么token跟踪很重要?
- 如何设置日志记录机制?
- 如何在LangSmith 仪表板中直观显示token使用情况?
为何token跟踪很重要?
token跟踪至关重要,因为与大语言模型的每次交互都会产生与处理的token数量相关的直接成本,这既包括输入,也包括模型的输出。如果不进行监控,提示中的细微低效、不必要的上下文或冗余请求都可能悄无声息地增加你的费用,并降低性能。
如果跟踪token,你可以准确了解其使用情况。这样一来,你可以优化提示、简化工作流程并控制成本。比如说,如果你的聊天机器人每次请求使用1500个token,那么将其减少到800个token可以将成本降低近一半。token跟踪这个概念大致如下:
设置LangSmith以记录token
第1步:安装所需的软件包
复制第2步:导入所有必要的组件
复制第3步:配置Langsmith
设置你的API 密钥和项目名称:
复制第4步:加载Hugging Face模型
使用对CPU友好的模型(比如google/flan-t5-base),启用采样以获得更自然的输出:
复制第5步:创建提示和链
定义一个提示模板,并使用LLMChain将其连接到Hugging Face管道:
复制第6步:使函数可以用LangSmith 来跟踪
使用@traceable 装饰器自动记录输入、输出、token 使用情况以及运行时:
复制第7步:运行函数,打印输出结果
复制输出:
复制第8步:查看Langsmith仪表板
进入到smith.langchain.com → 跟踪项目。你将看到以下内容:

你甚至可以看到每个项目的相关成本,以便分析你的账单。现在,要查看token使用情况及其他信息,只需点击你的项目。你将看到:
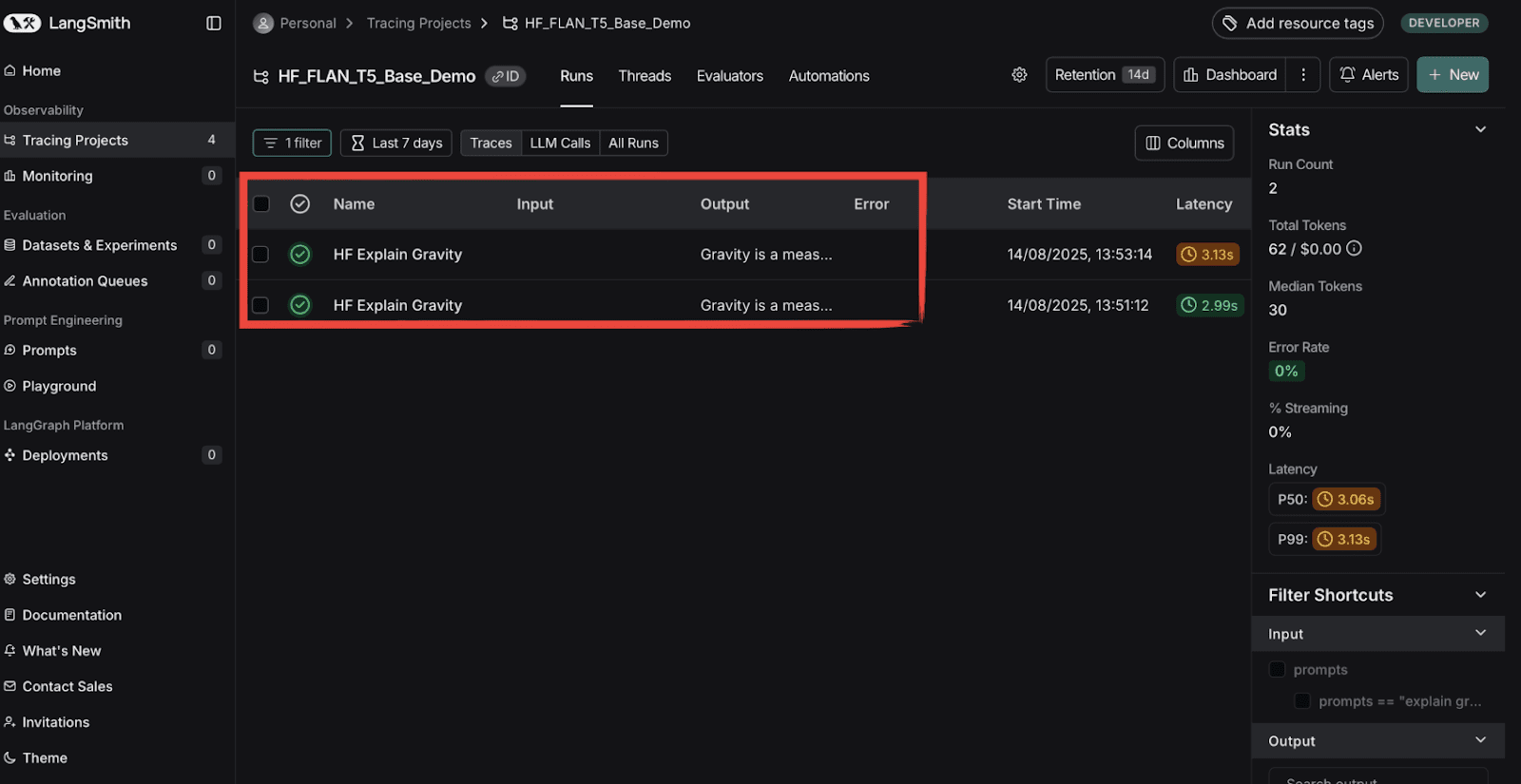
红色框突出显示并列出了你运行项目的次数。点击任意运行的项目,你将看到:
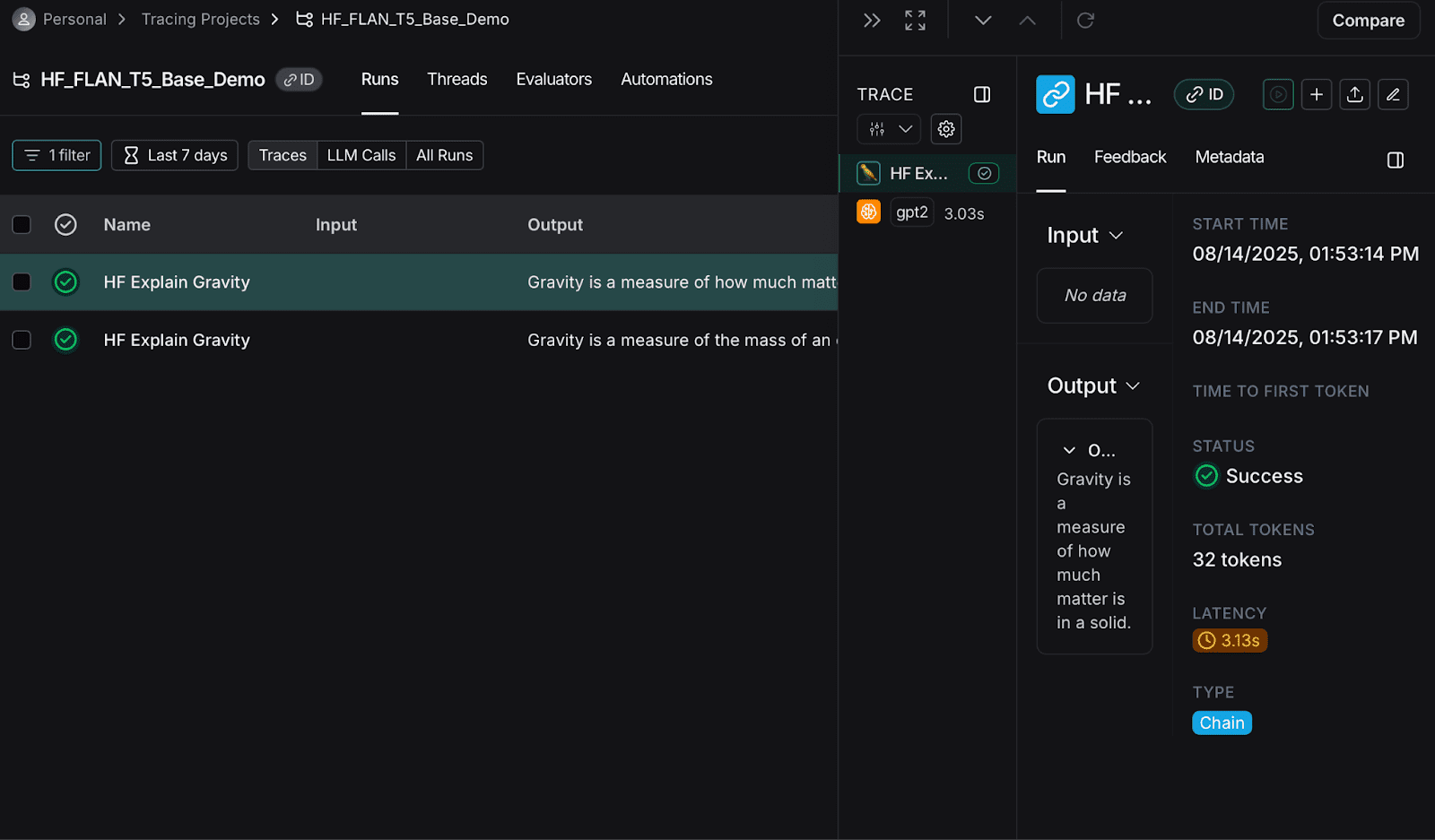
你可以在此处查看各种信息,比如token总数和延迟时间等。点击仪表板,如下所示:

现在,你可以查看随时间变化的图表,以跟踪token使用趋势、检查每个请求的平均延迟时间、比较输入和输出token,并确定峰值使用时段。这些信息有助于优化提示、管理成本并提升模型性能。
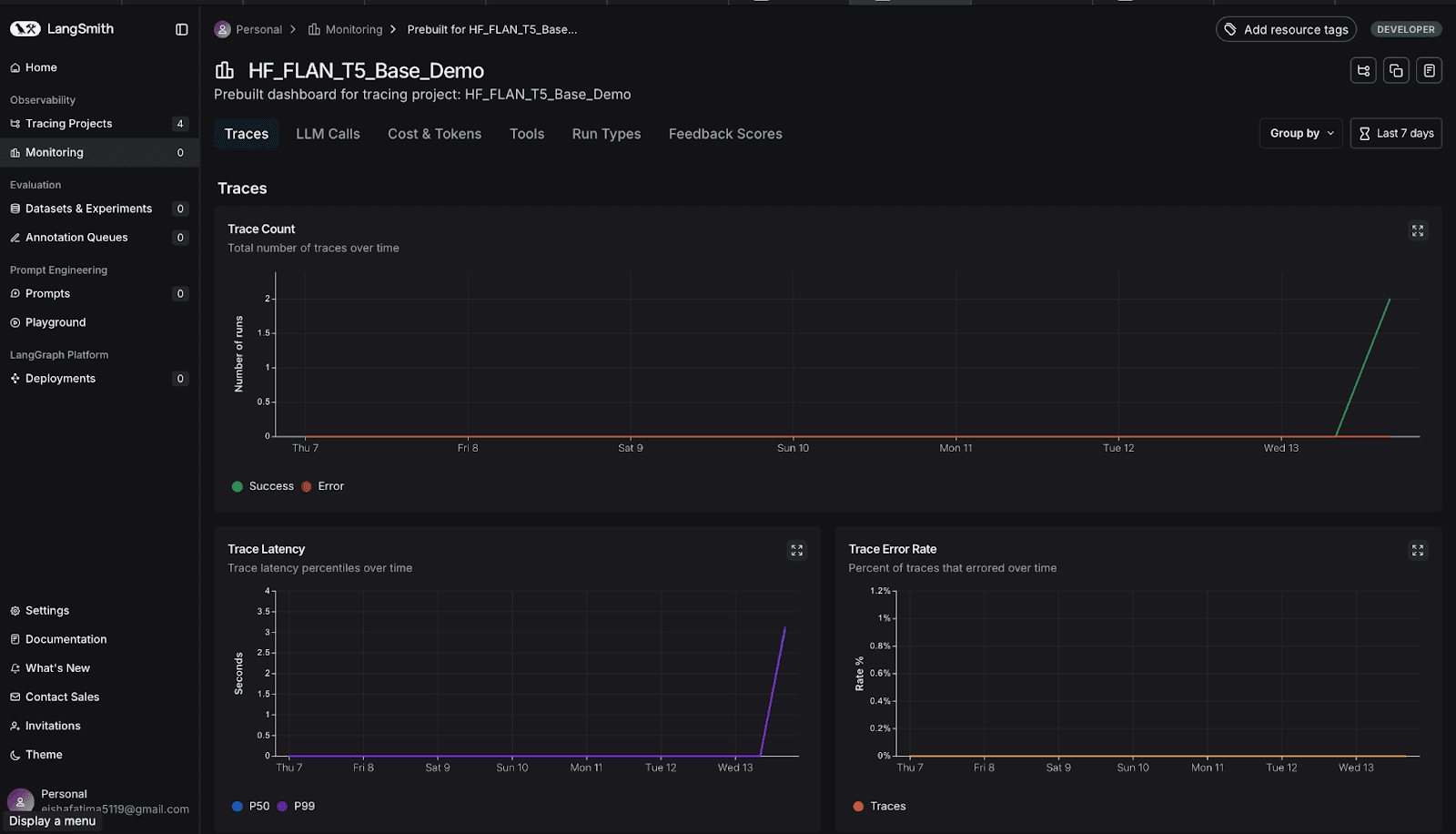
向下滚动以查看与你的项目相关的所有图表。
第9步:探究LangSmith 仪表板
你可以分析大量信息,比如:
- 查看示例跟踪:点击跟踪即可查看详细的执行情况,包括原始输入、生成的输出和性能指标。
- 查看单个跟踪:对于每个跟踪,你可以探究执行的每个步骤,查看提示、输出、token使用情况和延迟。
- 检查token使用情况和延迟:详细的token数量和处理时间有助于识别瓶颈并优化性能。
- 评估链:使用LangSmith的评估工具来测试场景、跟踪模型性能并比较输出。
- 在Playground中进行试验:调整温度、提示模板或采样设置等参数来微调模型的行为。
完成此设置后,你现在可以在LangSmith仪表板中全面了解Hugging Face模型的运行情况、token使用情况和整体性能。
如何发现和修复token消耗大户?
有了日志记录功能后,你可以:
- 检查提示是否过长
- 识别模型过度生成的调用
- 换成较小的模型,以执行成本更低的任务
- 缓存响应以避免重复请求
这对于调试长链或智能体非常有用。找到消耗最多token的那个步骤,并加以调整和完善。
结语
这就是设置和使用Langsmith的方法。记录token使用情况不仅是为了省钱,更在于构建更智能、更高效的LLM应用程序。本指南提供了基础,你可以通过探究、试验和分析自己的工作流程,以了解更多信息。
原文标题:The Beginner’s Guide to Tracking Token Usage in LLM Apps,作者:Kanwal Mehreen


