Token

新手指南:跟踪LLM应用程序中的token使用
译者 | 布加迪审校 | 重楼引言在构建大语言模型应用程序时,token就是金钱。 如果你曾经使用过像GPT-4这样的 LLM,可能有过这样的经历:查看账单时纳闷“费用怎么这么高? ” 你进行的每次API调用都会消耗token,这直接影响延迟和成本。

同样是用Cursor写代码,为啥你花十倍的费用?Token降本秘籍来了
Cursor官方的Token计费原理明细,也适用于其他按量付费的AI编程工具,分享给大家最有用的技巧我帮你标黄了,赶时间可以直接看高亮内容话说,现在的Cursor用起来就像开电车,一天天精打细算把格局开小了,整个人都变得抠搜了。 以下是 Cursor 中 LLM(AI)Token 使用的详细说明:每次在 Cursor 中与 AI 模型交互时都会使用 Token。 为了透明化,Token 数量会显示为 AI 提供者处理和报告的数量。

实测OpenAI最新模型!亮点真的爽,坑点两行泪!解决GPT5顽疾!犀利吐槽:半发布的实验品,编程生态零件齐了,拼一块儿就散架
编辑 | 云昭出品 | 51CTO技术栈(微信号:blog51cto)今天凌晨 1 点,OpenAI 又搞了一件让开发者大呼过瘾的产品! 图片严格地说,这次的发布是一款新模型,而且是“半发布”:GPT-5-Codex。 这是一个在 GPT-5 基础上专门微调的版本,明确面向 OpenAI 的各种 AI 编程辅助工具。

GPT-5系统提示词突遭泄露,17803 token曝光OpenAI小心思!
新一版疑似GPT-5提示词,在GitHub上曝光了。 图片项目地址:(Tokenizer)中,提示词足足有17803 token,堪称「巨无霸」级别的指令。 图片这份文档出自Ásgeir Thor Johnson,他在Github上持续整理了几乎所有已经泄露的模型提示词。

IDC:未来五年,中国生成式 AI 相关硬件支出将激增至 330 亿元
根据国际数据公司(IDC)发布的最新统计数据,随着中国生成式 AI 技术的快速发展,相关的网络硬件支出预计将在未来五年内大幅增长,从2023年的65亿元上升至2028年的330亿元。 这一趋势主要源于大模型商用的快速落地,预计到2024年下半年,中国日均 Token 消耗量将呈现爆发式增长,达到114.2万亿 Tokens。 这一数据并不包括通过海外 MaaS 平台进行的调用量。

Claude开大!百万 Token 上线,Sonnet 4 将上下文扩至 1M
Anthropic宣布,Claude Sonnet 4的上下文长度,现在达到了史无前例的100万个token。 图片这项功能已经正式上线Anthropic API,并同步登陆Amazon Bedrock,Google Cloud的Vertex AI也即将支持。 相比之前的20万个token,这次扩展是5倍的飞跃。

突袭GPT-5!Claude甩出百万上下文王炸!开发者吵翻:超出LLM极限,贵还没价值?谷歌大佬分享:用好上下文的四个编程技巧
编辑 | 伊风出品 | 51CTO技术栈(微信号:blog51cto)深夜更新! Claude Sonnet 4 已经支持百万级上下文窗口了! 这次升级,将上下文从原本的 20 万 Token 一口气提升 5 倍——百万上下文究竟有多大?

大模型中的嵌入向量
前面文章和小伙伴们聊了 Tokenizer,经过 Tokenizer 之后,自然语言变为 Token,那么大模型就可以直接训练 Token 了嘛? 还不行! 接下来还有一个词嵌入的环境,英文就是 Embedding,Embedding 实际上就是将 Token 转为张量,在有的场景下,Embedding 也指张量本身。
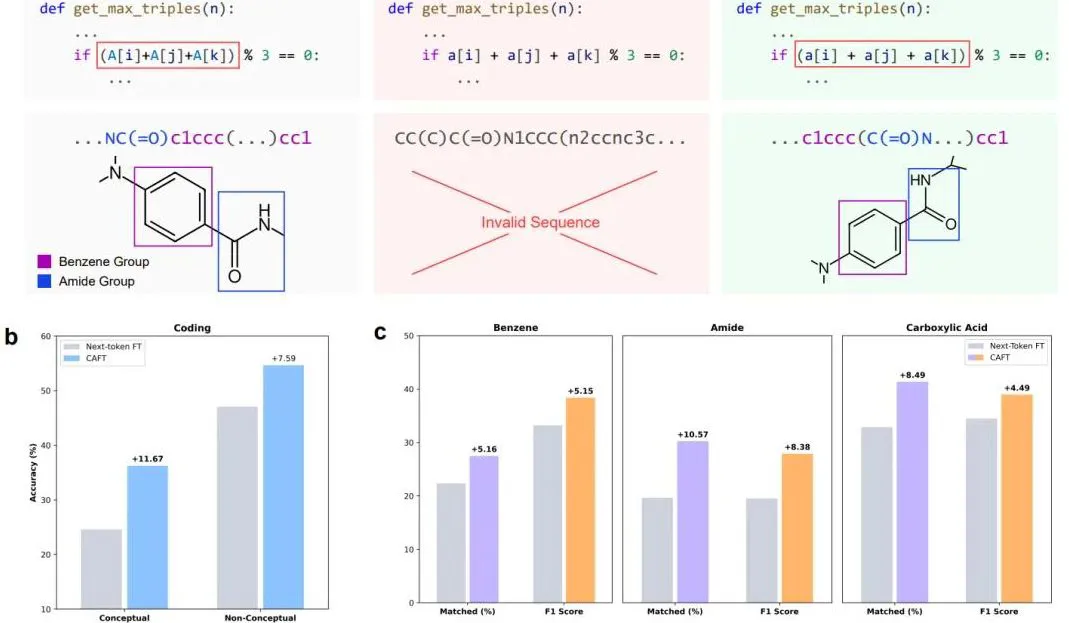
突破单token预测局限!南洋理工首次将多token预测引入微调
告别Next-token,现在模型微调阶段就能直接多token预测! 从GPT到Claude,当前主流LLM都依赖next-token prediction(下一token预测)进行训练,但它却让AI很难真正理解跨越多token的完整概念。 于是南洋理工大学最近提出了一项新技术——概念感知微调(CAFT),首次实现将multi-token prediction(多token预测)引入微调阶段,让模型能够像人类一样理解和学习完整概念。

刷新世界记录!40B模型+20万亿token,散户组团挑战算力霸权
互联网上最大规模的预训练来了! Nous Research宣布正式推出Psyche网络(Psyche Network),通过去中心化方式革新人工智能(AI)训练。 Psyche网络利用区块链技术,汇聚全球计算资源,成功启动了40B参数大语言模型Consilience的预训练任务,总计20万亿token,创下了迄今为止互联网上最大规模的预训练纪录。

苹果放大招!FastVLM 让视觉语言模型在 iPhone 上飞速 “狂飙”
苹果最近又搞了个大新闻,偷偷摸摸地发布了一个叫 FastVLM 的模型。 听名字可能有点懵,但简单来说,这玩意儿就是让你的 iPhone 瞬间拥有了“火眼金睛”,不仅能看懂图片里的各种复杂信息,还能像个段子手一样跟你“贫嘴”!而且最厉害的是,它速度快到飞起,苹果官方宣称,首次给你“贫嘴”的速度比之前的一些模型快了足足85倍!这简直是要逆天啊!视觉语言模型的 “成长烦恼”现在的视觉语言模型,就像个不断进化的小天才,能同时理解图像和文本信息。 它的应用可广了,从帮咱们理解图片里的内容,到辅助创作图文并茂的作品,都不在话下。

字节跳动携手港大与华中科技大学推出UniTok,革新视觉分词技术
近日,字节跳动联合香港大学和华中科技大学共同推出了全新的视觉分词器 UniTok。 这款工具不仅能在视觉生成和理解任务中发挥作用,还在技术上进行了重要创新,解决了传统分词器在细节捕捉与语义理解之间的矛盾。 UniTok 采用了多码本量化技术,能够将图像特征分割成多个小块,并用独立的子码本进行量化。

250多篇论文,上海AI Lab综述推理大模型高效思考
最近,像 OpenAI o1/o3、DeepSeek-R1 这样的大型推理模型(Large Reasoning Models,LRMs)通过加长「思考链」(Chain-of-Thought,CoT)在推理任务上表现惊艳。 但随之而来的是一个日益严重的问题:它们太能「说」了! 生成的推理过程往往充斥着冗余信息(比如反复定义)、对简单问题过度分析,以及对难题的探索浅尝辄止。

为什么说JSON不一定是LLM结构化输出的最佳选择?
当要求大语言模型(LLM)输出结构化数据时,所采用的格式会对结果产生比较大的影响。 本文对比了六种不同的格式,评估考察了它们的处理速度、tokens 消耗以及各自的限制。 1.简要说明JSON 虽然是多数人的首选,但它对 tokens 的消耗极大。

华为杨超斌:近 8 个月,国内 AI 大模型 Token 所带来的流量增长了 33 倍
杨超斌预计,到2030年,中国市场因为Token带来的网络流量的增加,将会达到每天500TB左右,而现在全中国所有的移动网络流量加起来每天是90TB。这意味着单就Token的数量就可以带来移动网络流量的增长。
AI编程工具Cursor已集成Claude 3.7 Sonnet推理模型
刚刚,Cursor AI宣布已集成Claude 3.7 Sonnet,并更新了用户界面,使其更加简洁易用。 此外,Cursor还引入了跨聊天对话功能,能够自动总结聊天摘要并继承到新开的聊天窗口中,进一步提升了用户体验。 早些时候,Anthropic公司正式发布其最新推理模型——Claude3.7Sonnet。

超越思维链?深度循环隐式推理引爆AI圈,LLM扩展有了新维度
不需要特殊训练数据,能处理语言难以形容的任务,3.5B 参数能实现 50B 的性能。 这是一种全新的语言模型架构,能够通过使用循环语言模型在潜在空间中隐式推理,显著提升模型的计算效率,尤其是在需要复杂推理的任务上。 近日,马里兰大学的一篇论文在 AI 研究社区中引发了关注,其提出的语言模型通过迭代循环块来工作,能在测试时展开到任意深度。

Meta公布BLT新架构:告别token,拥抱patch
译者 | 核子可乐审校 | 重楼Meta发布的BLT架构为大模型扩展找到又一条出路,也开启了用patch方法取代token的全新可能性。 开篇先提问:我们为什么非得把文本拆分成token? 直接用原始字节怎么就不行?
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉