Token
讨论下一个token预测时,我们可能正在走进陷阱
自香农在《通信的数学原理》一书中提出「下一个 token 预测任务」之后,这一概念逐渐成为现代语言模型的核心部分。最近,围绕下一个 token 预测的讨论日趋激烈。然而,越来越多的人认为,以下一个 token 的预测为目标只能得到一个优秀的「即兴表演艺术家」,并不能真正模拟人类思维。人类会在执行计划之前在头脑中进行细致的想象、策划和回溯。遗憾的是,这种策略并没有明确地构建在当今语言模型的框架中。对此,部分学者如 LeCun,在其论文中已有所评判。在一篇论文中,来自苏黎世联邦理工学院的 Gregor Bachmann

进我的收藏夹吃灰吧:大模型加速超全指南来了
2023 年,大型 语言模型(LLM)以其强大的生成、理解、推理等能力而持续受到高度关注。然而,训练和部署 LLM 非常昂贵,需要大量的计算资源和内存,因此研究人员开发了许多用于加速 LLM 预训练、微调和推理的方法。最近,一位名为 Theia Vogel 的博主整理撰写了一篇长文博客,对加速 LLM 推理的方法进行了全面的总结,对各种方法展开了详细的介绍,值得 LLM 研究人员收藏查阅。以下是博客原文内容。之前,我使用经典的自回归采样器手动制作了一个 transformer,大致如下:这种推理方法很优雅,是 LL
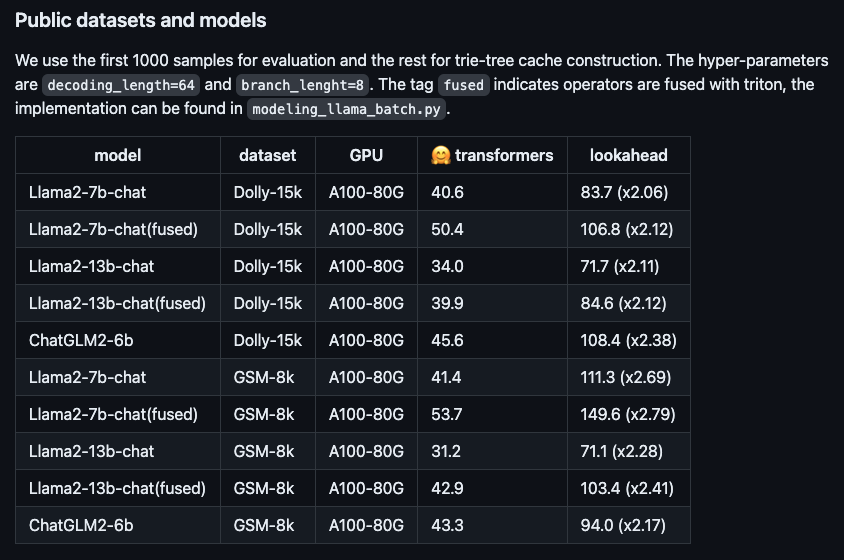
蚂蚁集团开源新算法,可助大模型推理提速2-6倍
近日,蚂蚁集团开源了一套新算法,可帮助大模型在推理时,提速2至6倍,引起业内关注。图:新算法在不同开源大模型上的提速表现。这套新算法名为Lookahead推理加速框架,能做到效果无损,即插即用,该算法已在蚂蚁大量场景进行了落地,大幅降低了推理耗时。以Llama2-7B-chat模型与Dolly数据集为例,实测token生成速度可由48.2个/秒,升至112.9个/秒,提速2.34倍。而在蚂蚁内部的RAG(检索增强生成)数据集上,百灵大模型AntGLM 10B版本的加速比达到5.36,与此同时,显存增加和内存消耗几乎

连看好莱坞大片都学会了!贾佳亚团队用2token让大模型卷出新境界
家人们谁懂,连大模型都学会看好莱坞大片了,播放过亿的GTA6预告片大模型还看得津津有味,实在太卷了!而让LLM卷出新境界的办法简单到只有2token——将每一帧编码成2个词即可搞定。等等!这种大道至简的方法有种莫名的熟悉感。不错,又是出自香港中文大学贾佳亚团队。这是贾佳亚团队自8月提出主攻推理分割的LISA多模态大模型、10月发布的70B参数长文本开源大语言模型LongAlpaca和超长文本扩展术LongLoRA后的又一次重磅技术更新。而LongLoRA只需两行代码便可将7B模型的文本长度拓展到100k token
Transformer速查宝典:模型、架构、训练方法的论文都在这里了
论文大合集,一篇文章就搞定。

30%Token就能实现SOTA性能,华为诺亚轻量目标检测器Focus-DETR效率倍增
轻量化模型 Focus-DETR 提速也提质。

苹果、俄勒冈州立提出AutoFocusFormer: 摆脱传统栅格,采用自适应下采样的图像分割
AFF 在小物体识别上向前再迈一步。

将26个token压缩成1个,新方法极致节省ChatGPT输入框空间
进入正文之前,先考虑一下像 ChatGPT 这样的 Transformer 语言模型(LM)的 prompt:

ICASSP 2022 | 用于多模态情感识别的KS-Transformer
多模态情感识别是人机交互中的重要技术,也是人工智能走向类人智能时所需要攻克的关键难题。

CVPR 2022 | 图像也是德布罗意波!华为诺亚&北大提出量子启发MLP,性能超越Swin Transfomer
来自华为诺亚方舟实验室、北京大学、悉尼大学的研究者提出了一种受量子力学启发的视觉 MLP 新架构。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉