自香农在《通信的数学原理》一书中提出「下一个 token 预测任务」之后,这一概念逐渐成为现代语言模型的核心部分。最近,围绕下一个 token 预测的讨论日趋激烈。
然而,越来越多的人认为,以下一个 token 的预测为目标只能得到一个优秀的「即兴表演艺术家」,并不能真正模拟人类思维。人类会在执行计划之前在头脑中进行细致的想象、策划和回溯。遗憾的是,这种策略并没有明确地构建在当今语言模型的框架中。对此,部分学者如 LeCun,在其论文中已有所评判。
在一篇论文中,来自苏黎世联邦理工学院的 Gregor Bachmann 和谷歌研究院的 Vaishnavh Nagarajan 对这个话题进行了深入分析,指出了当前争论没有关注到的本质问题:即没有将训练阶段的 teacher forcing 模式和推理阶段的自回归模式加以区分。
论文标题:THE PITFALLS OF NEXT-TOKEN PREDICTION
论文地址:https://arxiv.org/pdf/2403.06963.pdf
项目地址:https://github.com/gregorbachmann/Next-Token-Failures
读完此文,也许会让你对下一个 token 预测的内涵有不一样的理解。
研究背景
首先,让我们对 「人们在进行语言表达或者完成某项任务时,并不是在做下一个 token 的预测」这个表述的含义进行分析。对于这种反对意见,可能马上就会有 token 预测理论的支持者反驳到:不是每一个序列生成任务都可能是自回归的吗?咋一看确实如此,每一个 token 序列的分布都可以是一种链式规则,通过复杂的 token 预测模型进行模拟之后,这种规则就可以被捕捉到,即 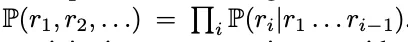 。看上去似乎自回归学习方式与让模型学习人类语言的目的是统一的。
。看上去似乎自回归学习方式与让模型学习人类语言的目的是统一的。
然而,这种简单粗暴的想法并不妨碍我们认为 token 预测模型的规划能力可能是很糟糕的。很重要的一点是,在这场争论中人们并没有仔细区分以下两种类型的 token 预测方式:推理阶段的自回归(模型将自己之前的输出作为输入)和训练阶段的 teacher-forcing(模型逐个对 token 进行预测,将所有之前的真值 token 作为输入)。如果不能对这两种情况做出区分,那当模型预测错误时,对复合误差的分析往往只会将问题导向至推理过程,让人们觉得这是模型执行方面的问题。但这是一种肤浅的认知,人们会觉得已经得到了一个近乎完美的 token 预测模型;也许,通过一个适当的后处理模型进行验证和回溯后,可以在不产生复合错误的情况下就能得出正确的计划。
在明确问题之后,紧接着我们就需要想清楚一件事:我们能放心地认为基于 token 预测的学习方式(teacher-forcing)总是能学习到准确的 token 预测模型吗?本文作者认为情况并非总是如此。
以如下这个任务为例:如果希望模型在看到问题陈述 p = (p_1, p_2 ... ,) 后产生基本真实的响应 token (r_1, r_2, ...) 。teacher-forcing 在训练模型生成 token r_i 时,不仅要提供问题陈述 p,还要部分基本事实 toekn r_1、...r_(i-1)。根据任务的不同,本文作者认为这可能会产生「捷径」,即利用产生的基本事实答案来虚假地拟合未来的答案 token。这种作弊方式可以称之为 「聪明的汉斯 」。接下来,当后面的 token 在这种作弊方法的作用下变得容易拟合时,相反,前面的答案 token(如 r_0、r_1 等)却变得更难学习。这是因为它们不再附带任何关于完整答案的监督信息,因为部分监督信息被「聪明的汉斯 」所剥夺。
作者认为,这两个缺陷会同时出现在 「前瞻性任务 」中:即需要在前一个 token 之前隐含地规划后一个 token 的任务。在这类任务中,teacher-forcing 会导致 token 预测器的结果非常不准确,无法推广到未知问题 p,甚至是独立同分布下的采样问题。
根据经验,本文作者证明了上述机制会导致在图的路径搜索任务中会产生分布上的问题。他们设计了一种能观察到模型的任何错误,并都可以通过直接求解来解决的方式。
作者观察到 Transformer 和 Mamba 架构(一种结构化状态空间模型)都失败了。他们还发现,一种预测未来多个 token 的无教师训练形式(在某些情况下)能够规避这种失败。因此,本文精心设计了一种易于学习的场景。在这种场景下会发现不是现有文献中所批评的环节,如卷积、递归或自回归推理,而是训练过程中的 token 预测环节出了问题。
本文作者希望这些研究结果能够启发未来围绕下一个 token 预测的讨论,并为其奠定坚实的基础。具体来说,作者认为,下一个 token 预测目标在上述这个简单任务上的失败,为其在更复杂任务(比如学习写故事)上的应用前景蒙上了阴影。作者还希望,这个失败的例子和无教师训练方法所产生的正面结果,能够激励人们采用其他的训练范式。
贡献总结如下:
1. 本文整合了针对下一个 token 预测的现有批评意见,并将新的核心争议点具体化;
2. 本文指出,对下一个 token 预测的争论不能混淆自回归推断与 teacher-forcing,两者导致的失败的原因大相径庭;
3. 本文从概念上论证了在前瞻任务中,训练过程中的下一个 token 预测(即 teacher-forcing)可能会产生有问题的学习机制,甚至产生分布上的问题;
4. 本文设计了一个最小前瞻任务。通过实证证明,尽管该任务很容易学习,但对于 Transformer 和 Mamba 架构来说,teacher-forcing 是失败的;
5. 本文发现,Monea et al. 为实现正交推理时间效率目标而提出的同时预测多个未来 token 的无教师训练形式,有望在某些情况下规避这些训练阶段上的失败。这进一步证明了下一个 token 预测的局限性。
方法介绍
自回归推理导致的问题
本文的目标是更系统地分析并细致区分下一个 token 预测的两个阶段:teacher forcing 和自回归。本文作者认为,现有的论证没有完全分析出 token 预测模型无法规划任务的全部原因。
正方:概率链规则永远滴神
支持者对下一个 token 预测最热的呼声是:概率链规则总能推出一个能够符合概率分布的 token 预测。
反方:误差会像雪球一样越滚越大
反对者认为,在自回归的每一步中都有可能出现微小的错误,而且一旦出错就没有明确的回溯机制来挽救模型。这样一来,每个 token 中的错误概率,无论多么微小,都会以指数级的速度越滚越大。
反方抓住的是自回归在结构上的缺点。而正方对概率链规则的强调也只是抓住了自回归架构的表现力。这两个论点都没有解决一个问题,即利用下一个 token 预测进行的学习本身可能在学习如何规划方面存在缺陷。从这个意义上说,本文作者认为现有的论证只捕捉到了问题的表象,即下一个 token 预测在规划方面表现不佳。
teacher forcing 导致的问题
token 预测模型是否会在测试期间无法高精度地预测下一个 token?从数学上讲,这意味着用 teacher forcing 目标训练的模型在其训练的分布上误差较大(从而打破了滚雪球模式的假设)。因此,任何后处理模型都无法找到一个能用的计划。从概念上来说,这种失败可能发生在「前瞻性任务」中,因为这些任务隐含地要求在更早的 token 之前提前计算未来的 token。
为了更好地表述本文的论点所在,作者设计了一个图的简单寻路问题,深刻地抓住了解决前瞻性问题的核心本质。这项任务本身很容易解决,所以任何失误都会非常直观地体现出来。作者将这个例子视为其论点的模板,该论点覆盖了 teacher forcing 下的前瞻性问题中的更一般、更困难的问题。
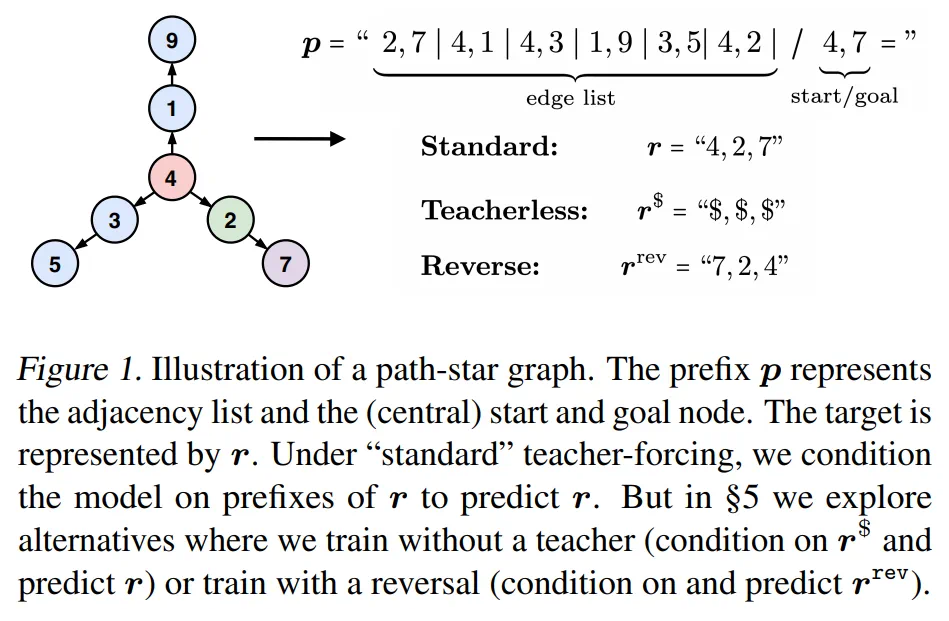
这个论点就是,本文作者认为 teacher-forcing 可能会导致以下问题,尤其是在前瞻性问题中。
问题 1:由于 teacher forcing 产生的「聪明的汉斯」作弊行为
尽管存在着一种机制可以从原始前缀 p 中恢复每个 token r_i,但也可以有多种其他机制可以从 teacher forcing 的前缀(p,r<i)中恢复 token r_i。这些机制可以更容易地被学习到,相应地就会抑制模型学习真正的机制。
问题 2:由于失去监督而无法加密的 token
在训练中解决了「聪明的汉斯」作弊行为后,模型被剥夺了一部分监督(尤其是对于较大的 i,r_i),这使得模型更难,甚至可能难以单独从剩余的 token 中学习真正的机制。
实验
本文通过图路径搜索任务的实践,演示了一种假设的故障模式。本文在 Transformer 和 Mamba 中进行了实验,以证明这些问题对于 teacher-forced 模型来说是普遍的。具体来说,先确定 teacher-forced 模型能符合训练数据,但在满足数据分布这个问题上存在不足。接下来,设计指标来量化上述两种假设机制发生的程度。最后,设计了替代目标来干预和消除两种故障模式中的每一种,以测试性能是否有所改善。
模型配置
本文对两种模型家族进行了评估,以强调问题的出现与某种特定体系结构无关,而是源于下一个 token 预测这个设计目标。对于 Transformer,使用从头开始的 GPT-Mini 和预训练的 GPT-2 大模型。对于递归模型,使用从头开始的 Mamba 模型。本文使用 AdamW 进行优化,直到达到完美的训练精度。为了排除顿悟现象(grokking),本文对成本相对较低的模型进行了长达 500 个 epoch 的训练。
本文在图 3 和表 2 中描述了不同拓扑路径的星形图的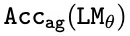 。可以观察到,所有模型(即使经过预训练)都很难准确地学习任务。如果模型一致地猜测认为 v_start≈1 /d,并由此在分布上产生问题,则精度值能被严格限制。即使在训练以拟合高达 200k 的量级到 100% 准确度的样本量时也是如此,尽管训练用的图结构和测试用的图结构具有相同的拓扑结构。接下来,本文定量地证明了这种明显的问题是如何由上述两个假设机制产生的。
。可以观察到,所有模型(即使经过预训练)都很难准确地学习任务。如果模型一致地猜测认为 v_start≈1 /d,并由此在分布上产生问题,则精度值能被严格限制。即使在训练以拟合高达 200k 的量级到 100% 准确度的样本量时也是如此,尽管训练用的图结构和测试用的图结构具有相同的拓扑结构。接下来,本文定量地证明了这种明显的问题是如何由上述两个假设机制产生的。

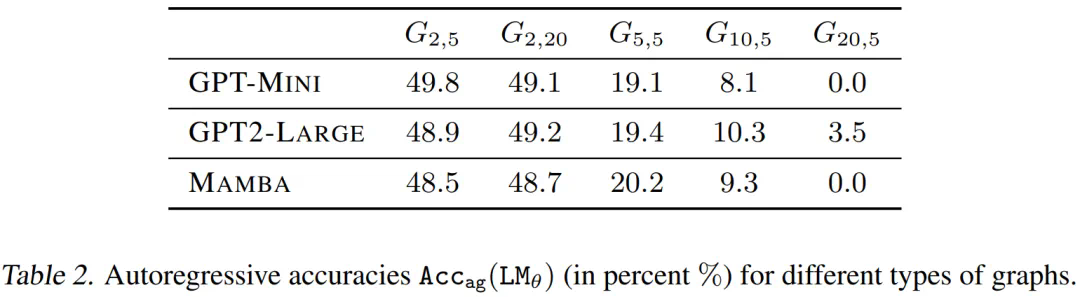
通过表 1 可以发现,为了拟合训练数据,teacher-forced 模型利用了「聪明的汉斯」作弊方法。
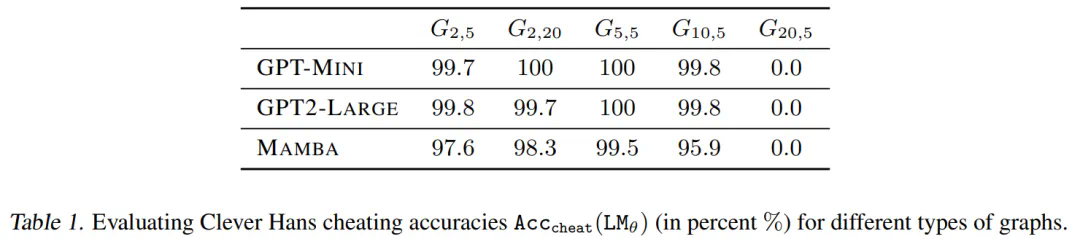
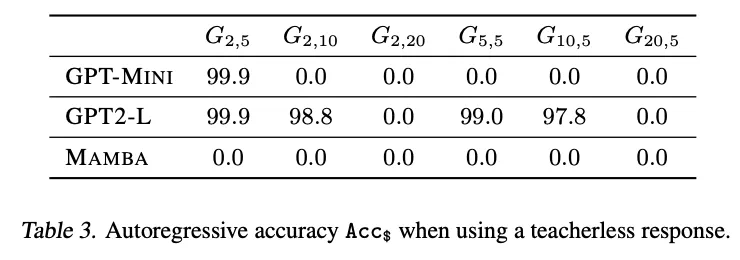
图 3 和表 3 显示了无教师模型的准确率。不幸的是,在大多数情况下,无教师的训练目标对模型来说太难了,甚至无法拟合训练数据,这可能是因为缺乏简单有效的欺骗手段。然而,令人惊讶的是,在一些更容易的图结构上,模型不仅适合于训练数据,而且可以很好地泛化到测试数据。这个优秀的结果(即使在有限的环境中)验证了两个假设。首先,「聪明的汉斯」作弊方法确实是造成原有 teacher-forcing 模式失败的原因之一。其次,值得注意的是,随着作弊行为的消失,这些模型能够拟合第一个节点,而这个节点曾经在 teacher-forcing 模式下是不可破译的。综上所述,本文所提出的假设可以说是得到了验证了,即「聪明的汉斯」作弊方法抹去了对学习第一个 token 的至关重要的监督。
更多研究细节,可参考原论文。