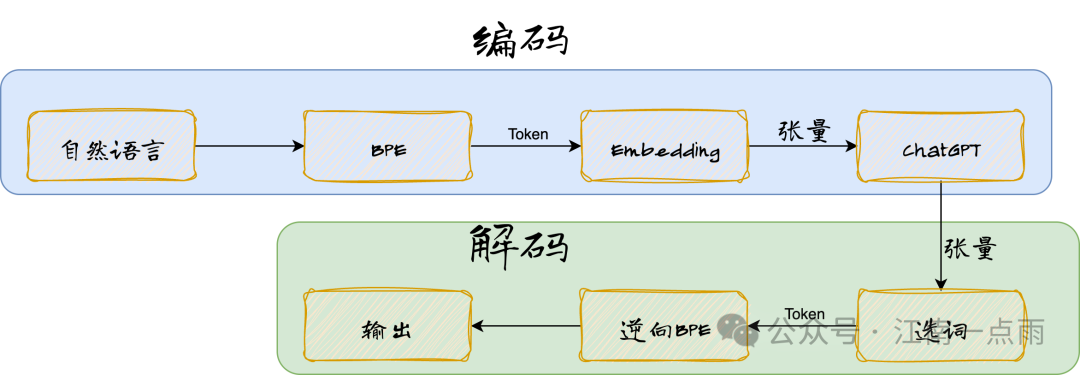
前面文章和小伙伴们聊了 Tokenizer,经过 Tokenizer 之后,自然语言变为 Token,那么大模型就可以直接训练 Token 了嘛?还不行!
接下来还有一个词嵌入的环境,英文就是 Embedding,Embedding 实际上就是将 Token 转为张量,在有的场景下,Embedding 也指张量本身。
这里涉及到一个概念,张量,那么什么是张量呢?
- 标量 (Scalar): 0 维张量,一个单一的数字 (温度 = 25 是一个标量)。
- 向量 (Vector): 1 维张量,一列数字 (猫的 Embedding = [0.21, -0.57, ..., 0.02] 就是一个向量,即 1 维张量)。
- 矩阵 (Matrix): 2 维张量,一个二维表格或网格 (最重要的那个 Embedding Table/Lookup Table 就是一个 2 维张量!它的行数是词表大小 V,列数是嵌入维度 D)。
说白了,张量就是多维数组,是存储数值数据的通用容器。
计算机无法直接对文本进行数学运算,需要先将文本(token)转为张量,然后才可以进行数学运算,这个将文本转为张量的过程,也就是词嵌入(Embedding)。当然,当计算机运算完成后,Embedding 又需要逆向转为具体的 token。
简单总结下,就是下面这样:
 图片
图片
一 Word Embedding 和 Position Embedding
1.1 Word Embedding
前面我们提到的 Embedding 算是一种 Word Embedding。
假设我们有一个文本语料,经过 Tokenizer 之后,得到 N 个 Token,每个 Token 都用一个 M 维的向量表示,那么最终我们就会得到一个 N * M 维张量。
举个简单例子,假设我现在有如下 Token:
- low
- new
- er
每个 Token 对应了一个 M 维向量:
- low:[0.6241,-0.3872,......,0.1593,-0.9017,0.4725]
- new:[-0.2715,0.8362,......,-0.5147,0.1908,-0.9423]
- er:[0.7321,-0.4156,......,0.2893,-0.6702,0.0549]
那么最终我们就会得到一个 N*M 维张量。
Token 在输入大模型的时候,位置顺序也是非常重要的,不同的位置顺序往往就意味着不同的含义。
1.2 Position Embedding
为什么需要 Position Embedding?这和 Transformer 模型天生的“盲目性”有关。
Transformer 看词是“一团乱麻”的: Transformer 的核心机制叫做“自注意力机制”。它可以让模型在处理一个词的时候,“同时”看到句子里的所有其他词,并计算哪些词是重要的。这就像你读书时,不是从左到右一个字一个字看,而是一眼扫过整行(甚至整页),同时关注每个字。
这就带来了一个天然的缺陷:忽略顺序信息。因为模型在计算一个词如何影响另一个词时,它并不知道这两个词在句子里的物理位置(谁前谁后、谁挨着谁)。它只看到“这个词 A”和“那个词 B”存在。
然而,在人类在语言中,词出现的顺序至关重要!“狗咬人”和“人咬狗”意思完全相反,词一样,但顺序变了,意义就颠倒了。再比如,“我爱你”和“你爱我”传达的情感对象也完全不同。
因此,我们需要一个能标记 Token 顺序的东西,这就是 Position Embedding。
Position Embedding 就是为了解决这个“不知道谁先谁后”的问题。
Position Embedding 的原理很简单:
- 给每个位置一个“地址”: 对句子里的每个位置(比如第 1 个位置、第 2 个位置……第 512 个位置),我们生成一个独特的、固定模式的“编码向量”。
- 把位置“地址”加到词上: 句子输入模型时,每个词有自己的表示也就是 Word Embedding。然后,我们把这个词的位置对应的位置编码向量加到词的表示上,也就是 Word Embedding + Position Embedding。
- 模型学会利用位置信息: 通过这种方式,模型在计算词语之间的关系(自注意力)时,不仅能知道“苹果”这个词存在,还能通过那个独特的“地址”,感知到:当“苹果”出现在句首(位置 1)时,它作为主语的倾向更强;当“苹果”出现在“我吃”之后(比如位置 4),那它更大概率是宾语;“苹果”紧挨着“大的”(位置相邻),那是在描述这个苹果的特性。
1.3 融合计算
Word Embedding 和 Position Embedding 通过简单的向量加法融合,生成最终输入表示:
具体操作步骤是这样(以下均为模拟数据):
- 生成词嵌入:输入序列 ["我", "爱", "NLP"],通过词嵌入矩阵映射为向量:
"我" → [0.2, -1.3, 0.8, 0.5]
"爱" → [1.1, 0.4, -0.2, 0.9]
"NLP" → [-0.5, 1.7, 0.3, -0.1]
- 生成位置嵌入,这块有两种方案,一种是原始 Transformer 方案,使用正弦/余弦函数生成固定编码,还有一种是 ChatGPT/GPT 系列方案,这种可学习的位置嵌入,通过训练更新位置向量参数。这里我们来看下第一种。
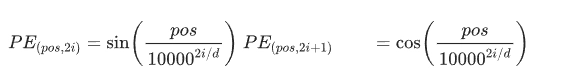
- 相加融合每个位置的词嵌入与位置嵌入逐元素相加:
位置0(“我”): [0.2, -1.3, 0.8, 0.5] + [0.0, 1.0, 0.0, 1.0] = [0.2, -0.3, 0.8, 1.5]
位置1(“爱”): [1.1, 0.4, -0.2, 0.9] + [0.84, 0.54, 0.0, 1.0] = [1.94, 0.94, -0.2, 1.9]
经过上面的融合计算之后,由于加法操作不改变向量空间维度,且能保留两种嵌入的线性关系,因此模型通过后续的自注意力机制,可同时学习词汇语义和位置依赖关系。并且还能实现同一词汇在不同位置可能获得不同表示(如“苹果”在句首偏向公司名,在句中可能指水果)。
ChatGPT 通过向量加法融合词嵌入(语义)和位置嵌入(顺序),生成兼具词汇含义和位置信息的输入表示。这一设计是 Transformer 理解语言结构的核心基础:没有位置嵌入,模型无法区分“猫追狗”和“狗追猫”;没有词嵌入,模型无法理解“猫”和“狗”的语义关系。两者的结合使模型能够动态捕捉上下文相关的语义,支撑其强大的语言生成能力。
二 Segment Embedding
Segment Embedding 是大语言模型(如 BERT)中用于区分输入序列中不同句子或逻辑段落的关键组件。它通过为不同片段分配唯一的向量标识,帮助模型理解句子边界和段落关系,尤其在处理多句输入的任务中至关重要。
比如我们在和 DeepSeek 对话时,每当我们发送一个问题时,实际上会把之前对话的上下文也作为输入一起发送给大模型,此时就需要区分之前对话内容中,哪些是我们提问的问题,哪些是大模型的回答。
Segment Embedding 通过为不同句子分配独立的向量标识(如句子 A 用 0、句子 B 用 1),使模型能识别它们属于不同逻辑单元。
Segment Embedding 是一个可学习的嵌入矩阵,维度与 Token Embedding 相同(如 BERT-base 为 768 维)。每个分段类型(A/B)对应一个唯一向量,直接与 Token Embedding、Position Embedding 逐元素相加,形成最终输入表示。
换句话说,我们最终输入给大模型的 Embedding 应该是这样的:
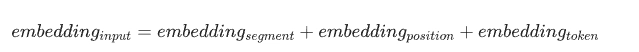
三 为什么需要 Embedding
Embedding 主要解决了语言的离散性与模型计算的连续性之间的问题,将离散的语言问题,变为了可计算的数学问题。
通过 Embedding,我们就可以通过余弦距离计算语义之间的相似性,如 vec("猫") 与 vec ("狗") 的相似度 >> vec ("猫") 与 vec ("汽车") 的相似度,也可以进行语义之间的类比关系,如 vec("巴黎") - vec("法国") ≈ vec("东京") - vec("日本")。


