2022 年 1 月,北京大学数据与智能实验室河图团队负责人苗旭鹏博士做客机器之心「2021-2022 年度 AI 技术趋势洞察」的「工程专场」直播间时,为我们带来了主题为「北大河图在稀疏大模型训练架构上的几点探索」的相关报告。

苗旭鹏博士的分享围绕稀疏大模型训练架构展开,主要从稀疏大模型的相关背景、河图相关研究来展开介绍。
Embedding 模型相关背景
首先苗旭鹏博士向我们介绍了稀疏大模型的相关背景。在过去的这几年,Embedding 模型已经成为了对于高维数据的一种有效的学习范式。例如,在语言模型当中,一条训练样本往往包含若干个单词,它们可以映射到一个统一的词表当中,将表中的索引映射到一个低维向量进行表达,也就是对词的一个分布式表示。近几年,模型规模不断变大,Embedding 模型其实也不例外。实际上,如果稀疏模型真的要扩展到如此巨大的规模,仍然面临着非常严峻的挑战。

稀疏大模型训练面临挑战
接下来苗博士跟我们分享了有关河图的相关研究论文,该论文发表在 VLDB 2022 上的一篇工作:HET: Scaling out Huge Embedding Model Training via Cache-enabled Distributed Framework。稀疏大模型的模型规模比较大,它的一个特殊之处在于可能 99% 的模型参数都会来自于 Embedding 层,也就是 Embedding Table。对于一个万亿规模的稀疏大模型,它的参数量仅仅模型参数就需要占据 3.7 TB 这样的一个存储空间,显然是无法在单机进行训练的。在过去的这几年,工业界一直努力在这个方向上进行探索,但大多数都还是基于采用结合现有的深度学习系统和高度工程优化的参数服务器的这种方案,希望能够把这个硬件的性能利用到极致。而事实上由于我们的网络带宽其实都是有限的,这些方案并没有从根本上去解决这个稀疏大模型训练的问题。

河图研究基于两点观察:Skewness、Robustness
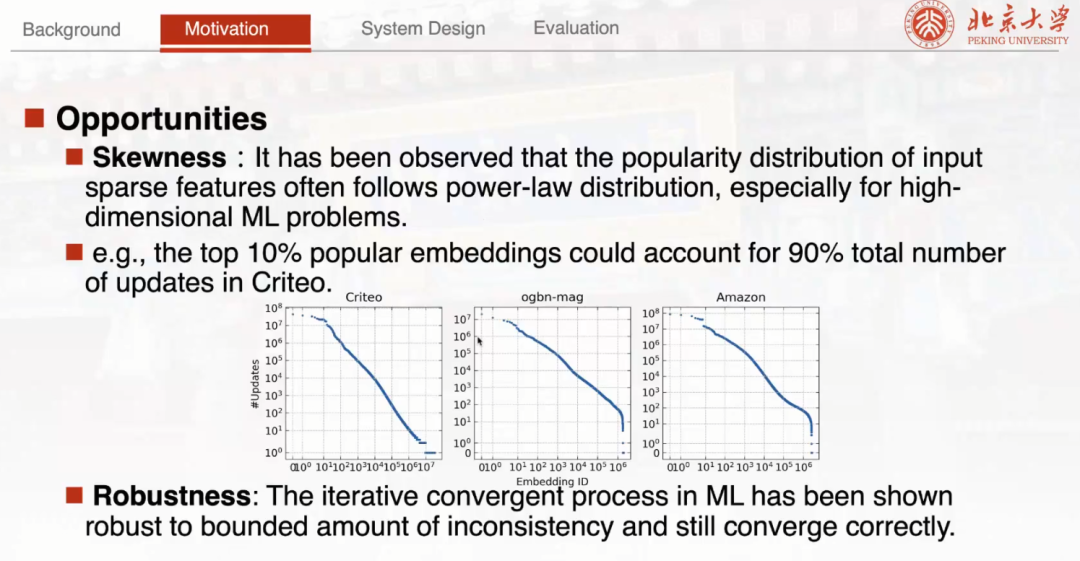
HET 在尝试解决稀疏大模型训练架构上的问题时,主要是基于两点观察。第一点是 Skewness 。可以注意到很多真实的稀疏大模型,它的输入数据的特征分布往往具有倾斜分布的性质。举例来说,比如最常用的公开推荐数据集 Criteo 上面前 10% 的高频 Embedding 。经过统计,它已经占据整个数据集当中 90% 的 Embedding 通信。基于这种性质启发了苗博士团队在 HET 当中对这些不均衡的 Embedding 分布去进行设计和讨论。第二个点是 Robustness。它并不是只针对稀疏大模型,是机器学习本身的一个性质。
由于稀疏大模型具有稀疏模型参数以及稠密模型参数两部分,它们具有天然不同的访问性质,所以总体上还是采用一种混合的通信架构。对于稠密的参数,采用 GPU 间性能比较高的 Allreduce 的方式进行同步。对于稀疏的 Embedding 参数,采用类似参数服务器的架构,并在参数服务器的架构上进行一个改变。
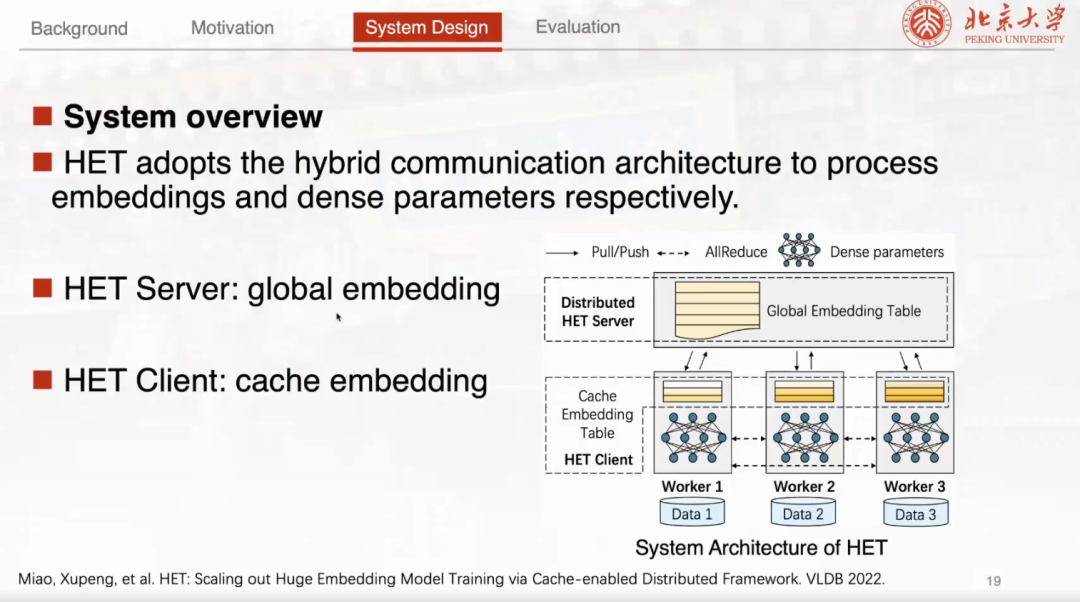
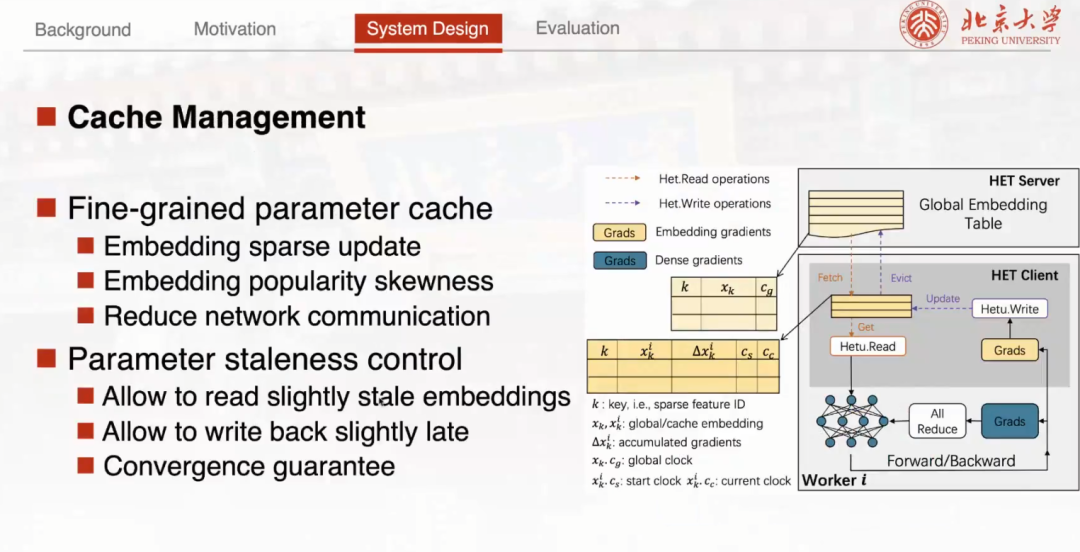
采用 Cache Embedding Table 来缓存这些高频访问的 Embedding 参数
比较不一样的是, HET Client 在这里设计了一个 Cache Embedding Table 这样的一个概念。这个 Embedding 缓存是整个设计方案的一个核心。具体来说采用 Cache Embedding Table 来缓存这些高频访问的 Embedding 参数。同时,为了保证模型的收敛性,苗博士团队提出了一种细粒度基于 Emending Clock 的有限异步协议来解决如何在不同的节点当中去同步这些 Embedding 副本,既允许读取一些比较旧的 Embedding 同时也允许延迟写回缓存上的梯度更新。在这个结构基础上去引入一个比较重要的 Lamport Clock ,用来记录 Embedding 向量的状态。在训练过程中,通过比较 Embedding 的时钟就可以知道这个副本的延迟或者超前的程度。
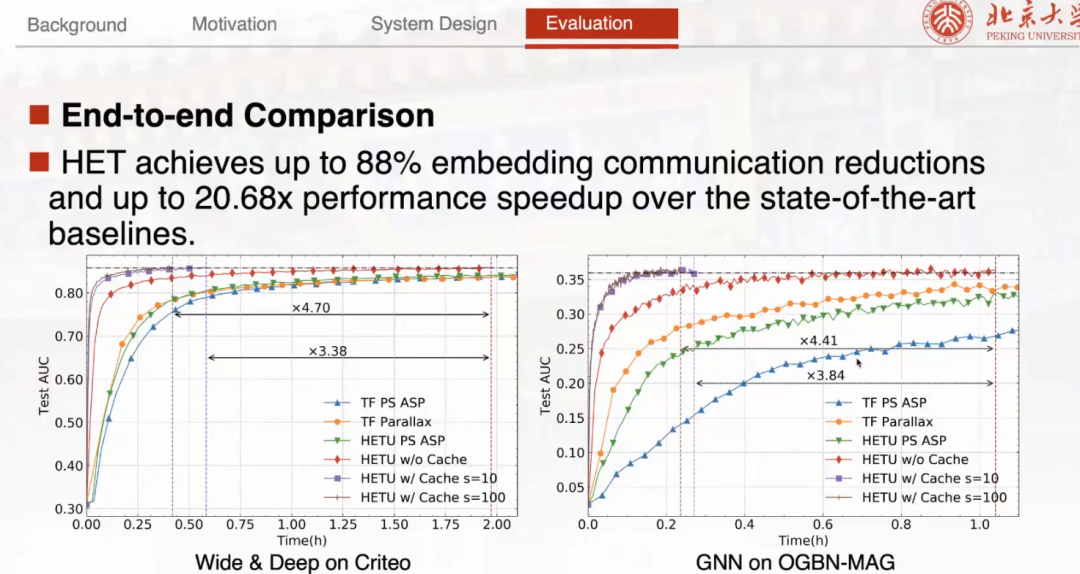
最后苗博士向我们展示了 HET 的相关实验数据。实验结果发现 HET 能够减少超过 88% 的 Embedding 通信。在整体的 End to End 的训练时间上,可以实现 20 倍以上的加速。