在 LangGraph 中基于结构化数据源构建。
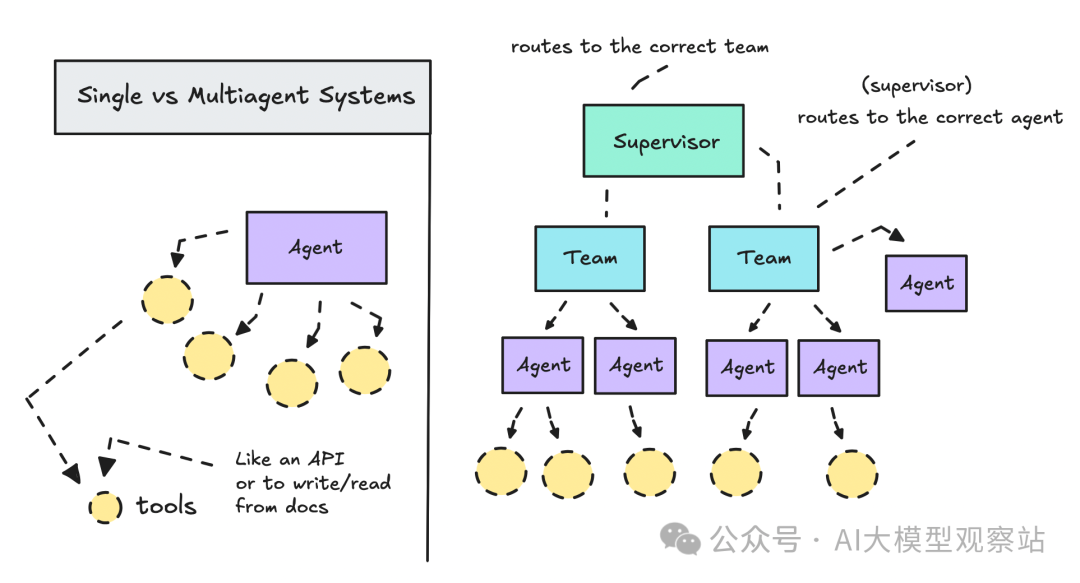 在 LangGraph 中构建不同的 agent 系统 | Image by author
在 LangGraph 中构建不同的 agent 系统 | Image by author
如果你不是会员但想阅读原文,请点击这里。
如果你刚开始搭建不同的 agentic 系统,一个有趣的切入点是比较单智能体工作流与多智能体工作流,或者说更灵活的系统与更可控的系统之间的差异。
本文将帮助你理解什么是 Agentic AI,以及如何用 LangGraph 和 LangSmith Studio 构建 agentic 系统。
我们会用两种不同的架构构建一个 researcher,以便对比结果、判断哪种做得更好。
本文涉及的资源在这里(https://github.com/ilsilfverskiold/Awesome-LLM-Resources-List/tree/main/guides/langgraph)。运行基本都是免费的,除了会用到一些 OpenAI tokens。
使用场景
为了构建一个具体的东西,我们会搭建一个 tech 研究 agent,它能找出昨天或过去一周的趋势,再判断什么值得报道。
在汇总与收集研究这种任务上,Agentic AI 非常能打。
本文会用一个 API 来汇总科技圈大家在讨论和分享的内容,然后让 agentic 系统基于我们的用户画像判断重要性并为我们做摘要。
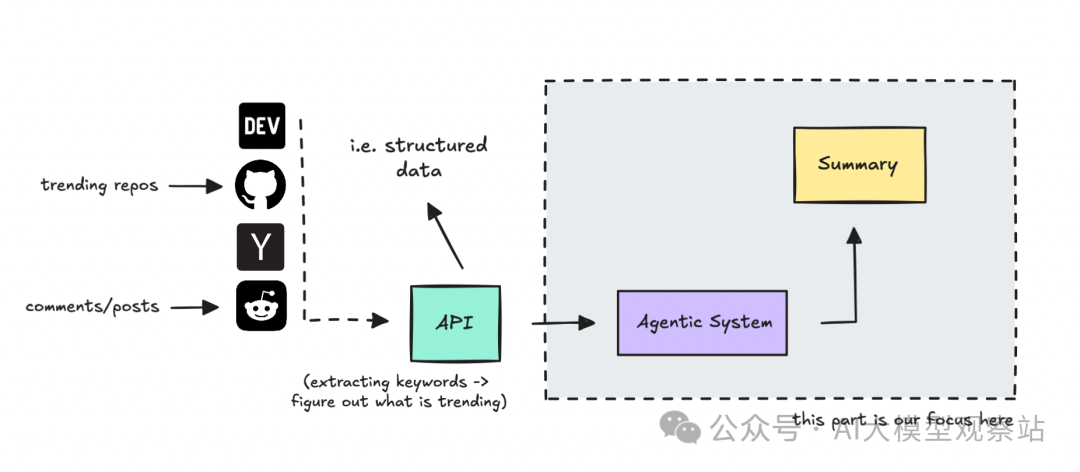 数据源提供了结构化数据,agentic 系统可以据此工作
数据源提供了结构化数据,agentic 系统可以据此工作
这个 agent 不会在正文里添加引用,我们关注的是在只设置单智能体与设置多个协同智能体两种情况下,它分别能覆盖到多少信息。
因此本文的重点更在 agentic 的构建,而不是数据源本身。
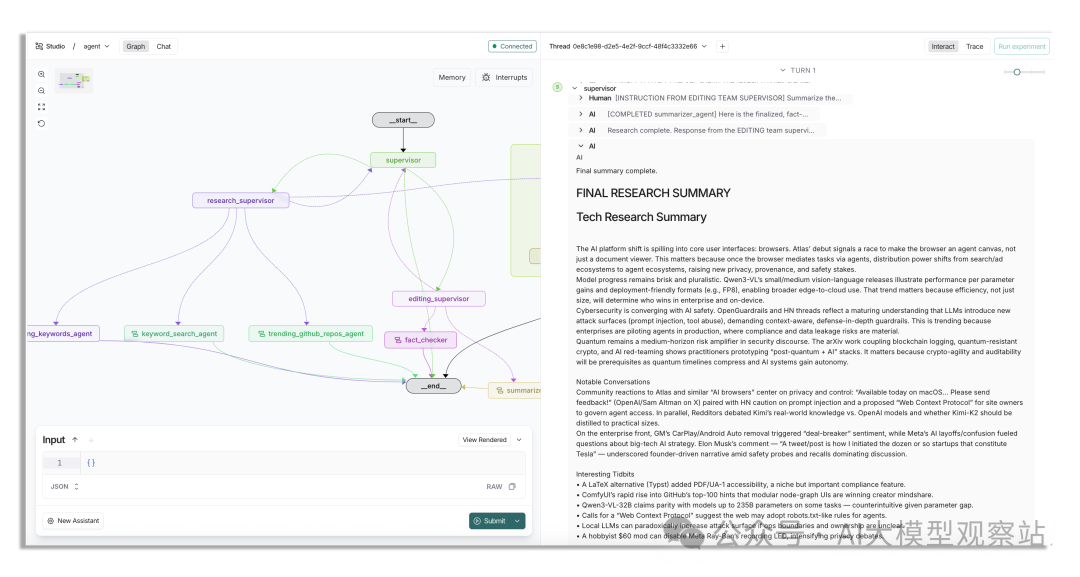 我们的多智能体系统在 LangSmith Studio 中的样子,运行需要几分钟 | Image by author
我们的多智能体系统在 LangSmith Studio 中的样子,运行需要几分钟 | Image by author
我们先用一个简单的 agent(能访问不同的 API endpoints)搭建系统,然后再扩展为多团队、更多工具的系统,看质量差异。
开始之前,我会先给入门者做个简短复习。如果你对 agentic 系统很熟,可以跳过前面的一些部分。
Agentic AI 与 LLMs
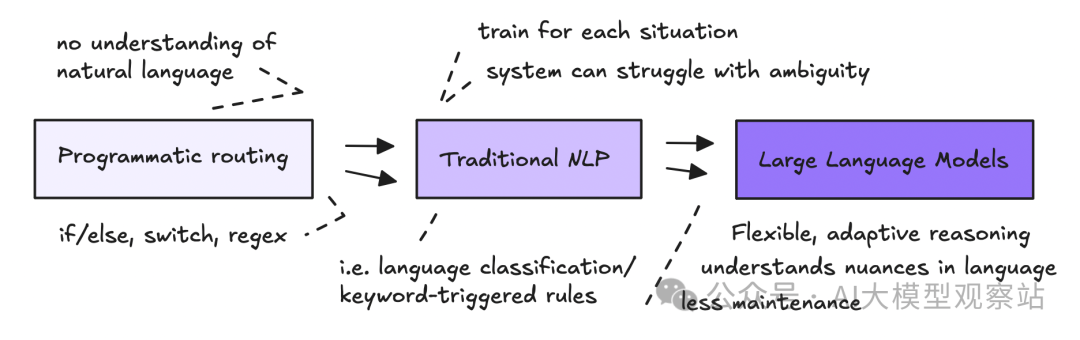
Agentic AI 是用自然语言来编程。与其写死板、显式的代码,不如用自然语言指令让大语言模型(LLMs)负责路由数据并调用动作,实现自动化。
在工作流里使用自然语言并不新鲜,我们已经用了多年的 NLP 来抽取和处理数据。
新的是我们现在能给语言模型更多自由度,让它们处理歧义并做出动态决策。
 图片
图片
但 LLMs 能理解复杂语言,并不意味着它们天然会校验事实或保证数据完整性。
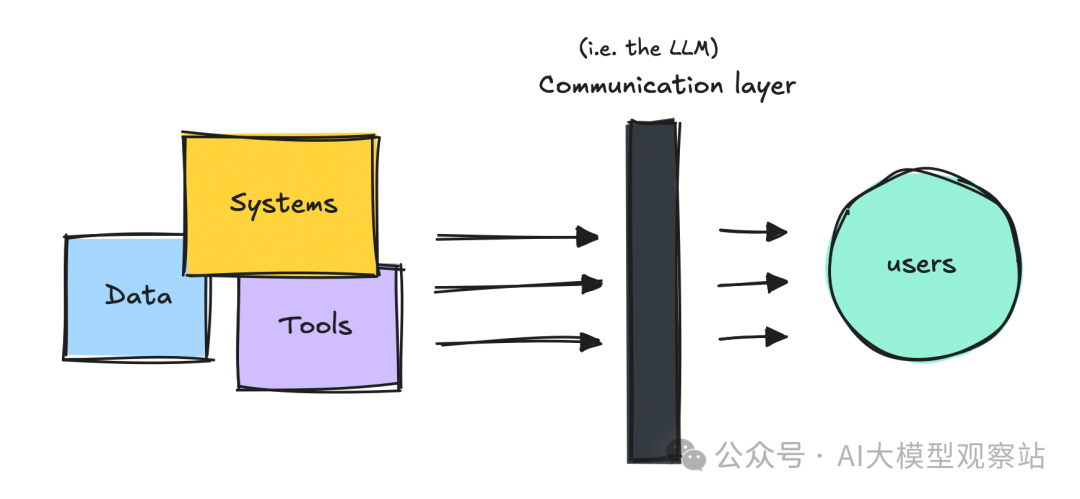
我更把它们看作一个沟通层(至少目前如此),位于结构化系统与既有数据源之上。
 图片
图片
我通常这样向非技术同事解释:它们有点像我们。没有干净、结构化的数据,我们也会开始“编”。LLMs 也是一样。
所以,就像我们一样,它们会尽力而为。如果想要更好的输出,就要为它们构建能提供可靠数据或可操作系统的环境。
因此,在 Agentic 系统中,我们会为它们接入不同的数据源、工具和系统。
当然,就算我们_可以_在更多地方使用更大的模型,也不代表我们总是_应该_这么做。LLMs 在理解细腻自然语言时大放异彩,比如客服、研究或 human-in-the-loop 协作。
但对于结构化任务(例如提取数字并发送到某处),你应该优先使用传统方法与自动化。
LLMs 并不比计算器更擅长算术。所以,不是让 LLM 直接算,而是给 LLM 一个计算器的调用能力。
因此,只要_可以_用程序化的方式构建工作流的部分,通常都更优。
尽管如此,LLMs 擅长适应现实世界的“脏输入”和理解模糊指令,把两者结合起来是构建系统的好方法。
如果你还很新手,并且仍有些困惑,可以去看看我其他更详细的内容。等我们动手搭建时,可能会更清晰。
Agentic 框架与 LangGraph
很多人第一次做 agent 就直接上 CrewAI 或 AutoGen,但我们有很多选择。
我之前在这里写过一些综述,阅读量超过 10 万,想要总览可以先看。
LangGraph 技术性更强,也更复杂,它是基于 LangChain 的图式框架。很多开发者都偏爱它,所以至少做点东西是值得的。
我现在更喜欢无框架的做法,但会借鉴各框架里学到的好东西,所以学习它们仍然有价值。
不过 LangGraph 有不少抽象层,你可能会想重构部分以便更好地控制与理解。
这里我不详细展开 LangGraph,所以我单独做了一个简短指南给需要复习的人。
在这个用例里,你可以不写代码就跑起来工作流,但如果你来此是为了学习,也可以顺便理解 LangGraph 的工作方式。
单智能体 vs 多智能体系统
在开工之前,先说说单智能体与多智能体的差异。
如果你围绕一个 LLM 并给它一堆 tools来构建系统,你就是在做单智能体工作流。它很快,而且如果你是 agentic AI 新手,你可能觉得模型“应该能自己搞定”。
 图片
图片
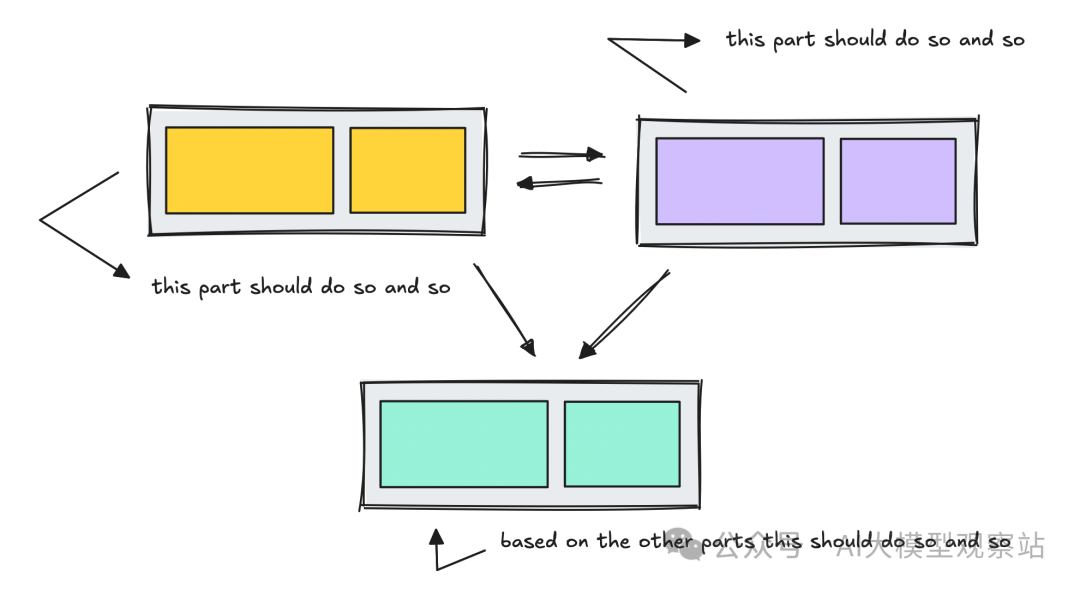
但说到底,这些工作流也是一种系统设计。
就像任何软件项目一样,你需要规划流程、定义步骤、组织逻辑,并决定每一部分如何行为。
 图片
图片
这就是多智能体工作流的用武之地。
并不是所有多智能体都是层级式或线性的,有些是协作式的。协作式工作流也更偏灵活,我觉得在当下能力水平下,这类工作流相对更难驾驭。
不过,协作式工作流同样会把不同功能拆解为独立模块。
当你只是试验时,协作式工作流非常合适,但它不一定能提供完成实际任务所需的精确度。
在本文要搭的工作流中,我已经知道该如何使用这些 APIs,因此我需要引导系统以正确方式使用它们。
我们会对比一个单智能体的设置与一个层级式多智能体系统:由一个 lead agent 把任务分发给一个小团队,让你看看它们在实践中的行为差异。
构建单智能体
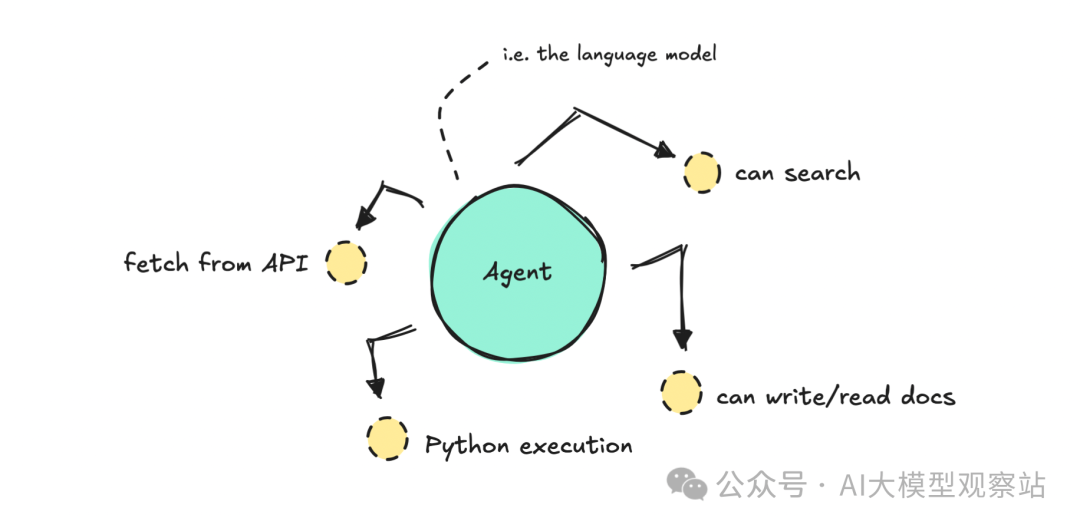
构建单智能体时,我们用一个 LLM 和一个 system prompt,然后给它若干 tools 的访问权。
智能体会基于用户的问题自行决定该用哪个 tool、何时用。
 图片
图片
单智能体的挑战在于“可控性”。
不论 system prompt 多么详细,模型都可能不按我们要求执行(更受控的环境也可能如此)。如果我们给太多 tools 或选项,它很可能不会全部使用,甚至用错。
你能写进指令里让它“照做”的空间是有限的。
为说明这一点,我们会构建一个 tech news agent,它能访问多个自定义数据的 API endpoints,并且 tools 中有多种可选参数。
由智能体决定使用多少工具、如何组织最终摘要。
提醒一下,我是用 LangGraph 来构建这些工作流的。这里不会深讲 LangGraph,如果你想学基础以便修改代码,看这里(这份指南写于 2025 年 4 月)。
你可以在这里找到单智能体工作流。要运行它,你需要 LangSmith 的账号(可访问 LangSmith Studio)以及安装了 Python 3。
有了账号后,把单智能体工作流 clone 到你的电脑。
目录结构如下:
复制创建一个 .env 文件并添加 Google API key。这个单智能体我们会用 Gemini。
复制然后创建环境:
复制复制安装 LangGraph CLI:
复制requirements 在 my_agent 文件夹下,也需要安装:
复制安装完成后,你可以在 LangSmith Studio 打开这个单智能体工作流:
复制这会自动打开 LangSmith Studio(之前叫 LangGraph Studio)。
 图片
图片
这里还需要创建一个 assistant,默认是 Anthropic,而我们这个 agent 使用 Gemini。
点击左下角按钮管理 assistants。
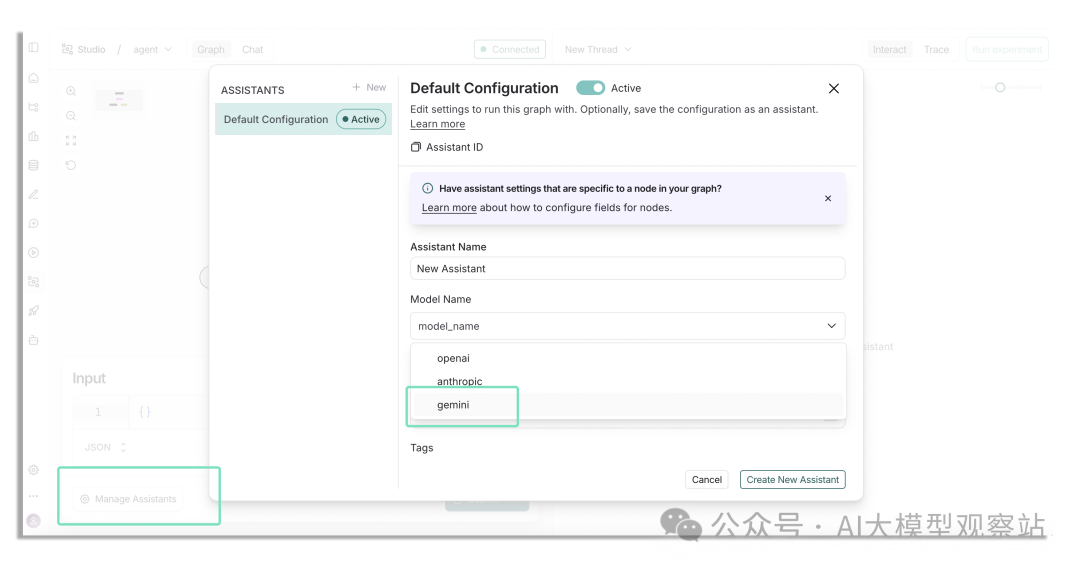 请确保创建一个模型为“gemini”的新 assistant,并点击“create new assistant” | Image by author
请确保创建一个模型为“gemini”的新 assistant,并点击“create new assistant” | Image by author
请确保创建一个模型为“gemini”的新 assistant,并点击“create new assistant” | Image by author
会弹出上图类似的 modal。把模型设为“gemini”,然后点击“Create New Assistant”。
回到主界面后,你可以设置起始消息。
比如告诉它你的身份、希望获取每日/每周/每月的信息(见下例)。
复制在 LangSmith Studio 里会像这样显示:
 图片
图片
点击提交,结果会很快,因为我们是单智能体。
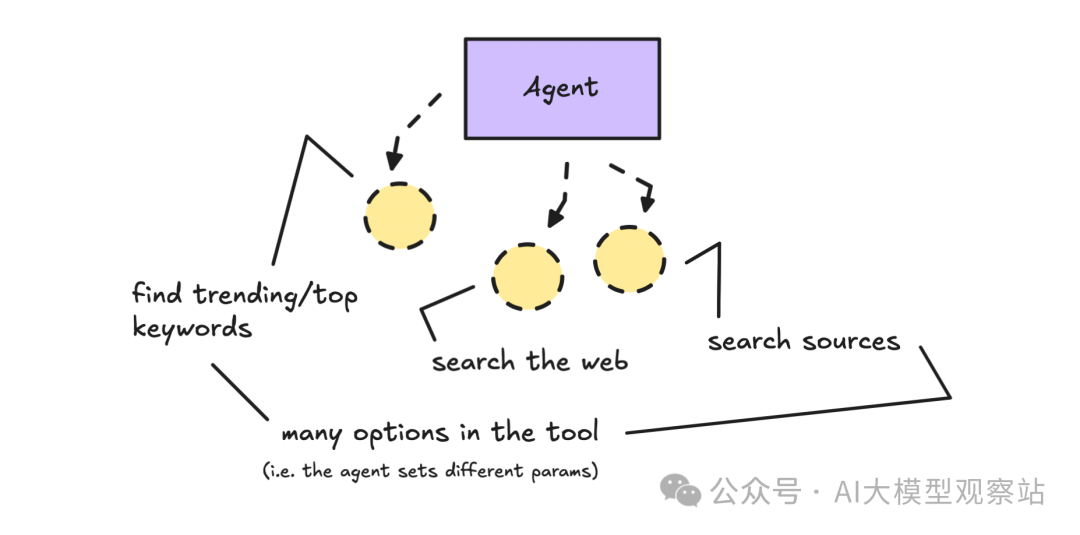
它会先在 3 个不同类别下检查一些 trending keywords,然后对其中几个关键词再看大家都在说什么。
如果你想了解这些 tools 是如何创建的,去看看代码即可,本质上就是调用一个 API。
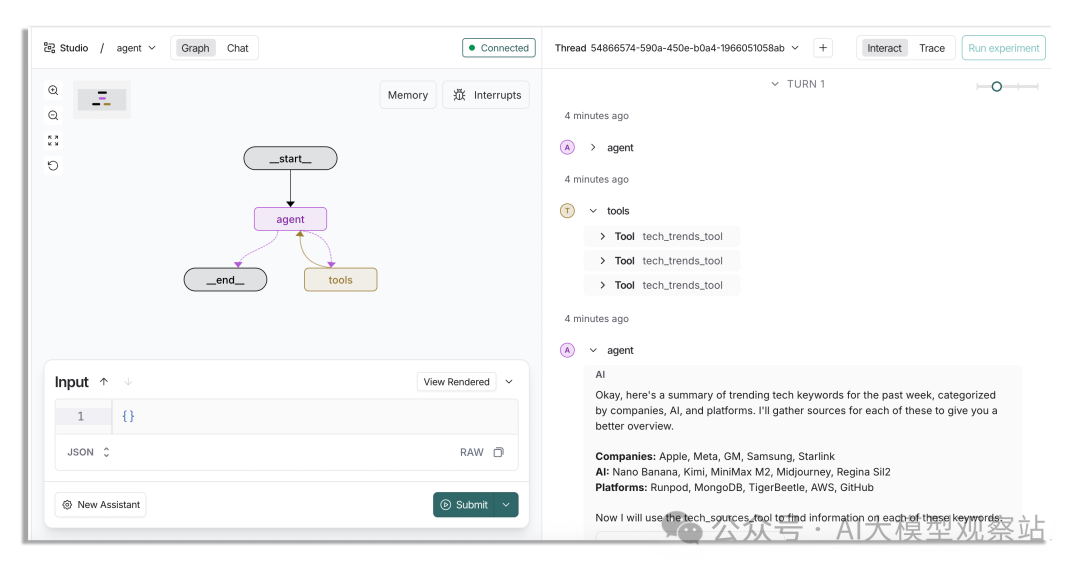 图片
图片
最终结果类似这样(当然取决于你运行的时间,信息每天都会变化):
复制如果你不想自己运行 agent 又想看完整结果,点这里。结果还可以,但你会发现它挖掘得不够深。
当然我们可以继续追问它,但你可以想象,如果任务再复杂一些,它就会在工作流里开始走捷径。
关键在于:agent 系统不会“自动照着我们脑海中的方式思考”,我们必须对它进行编排,让它按我们的意愿工作。
只要有人在环,比如做问答,这没问题。
在这个场景里,如果人类问一个问题、agent 去取回对应信息,那会很好用。
但如果是深度研究,我们需要更复杂一点的系统。可以用工作流式(每个环节做一件事),也可以尝试构建一个层级式系统,让一个 agent(或团队)对某一件事负责。
测试多智能体工作流
搭建多智能体系统要比给单智能体配几样工具难多了。
你需要在此之前仔细思考系统架构,以及数据如何在 agents 之间流动。
这里我搭的多智能体工作流使用两个团队(research team 和 editing team),每个团队下有若干 agents。
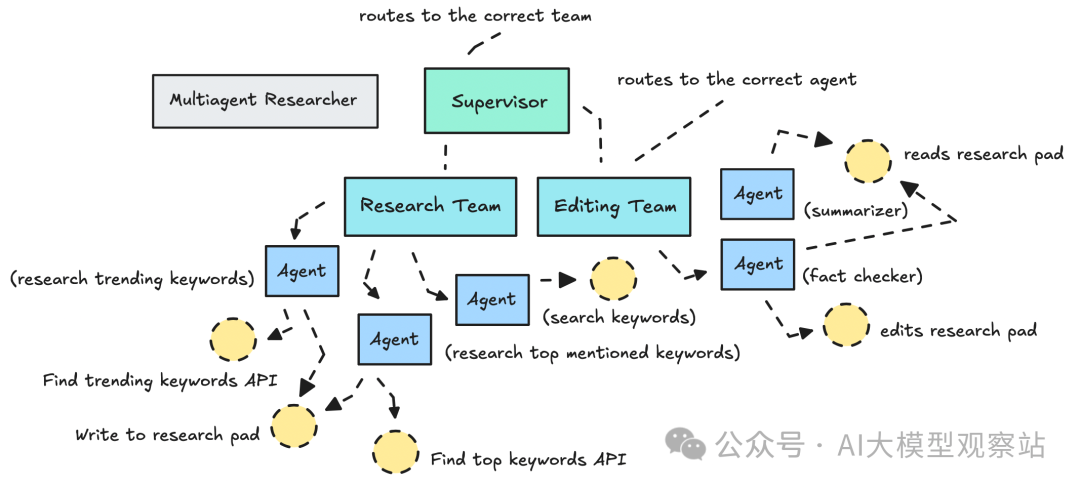 我们多智能体系统中的团队/agents 架构示意 | Image by author
我们多智能体系统中的团队/agents 架构示意 | Image by author
每个 agent 只能访问特定的一小组 tools(不宜过多),并有清晰的指令。
这种对每个 agent 的职责收敛,对于较低级别的 LLMs(例如 Gemini Flash 2.0)非常有益;不过我仍然喜欢用更强的 LLM 来做 summarizing(这里我们用 GPT-5 作为 summarizer agent)。
我们引入了一些新工具,比如一个 research pad,充当共享空间(一个团队写入发现,另一个团队读取)。最后一个 LLM 会读取所有已研究与编辑的内容来生成摘要。
另一种替代 research pad 的方式是在 state 中存储数据到 scratchpad,为每个团队或 agent 隔离短期记忆。但这也意味着需要仔细思考每个 agent 的记忆应包含什么。
我还决定把 tools 再丰富一些,以便在前期就提供更充实的数据,这样 agents 就不必对每个关键词逐个拉取来源。在这里我之所以这么做,是因为可以用常规编程逻辑来搞定。
要点:如果能用常规编程逻辑,就用它。
工作流在这里为你准备好了。加载之前,请在 .env 文件中同时添加你的 OpenAI 与 Google API keys。
复制只有在你要尝试更换 agents 时才需要设置 Anthropic key(但如果不设可能会报错;遇到报错就新建一个只包含 Gemini 的 assistant)。
剩下步骤与单智能体类似:创建环境、安装依赖并打开工作流。
复制打开后你会看到它看起来比单智能体复杂多了。
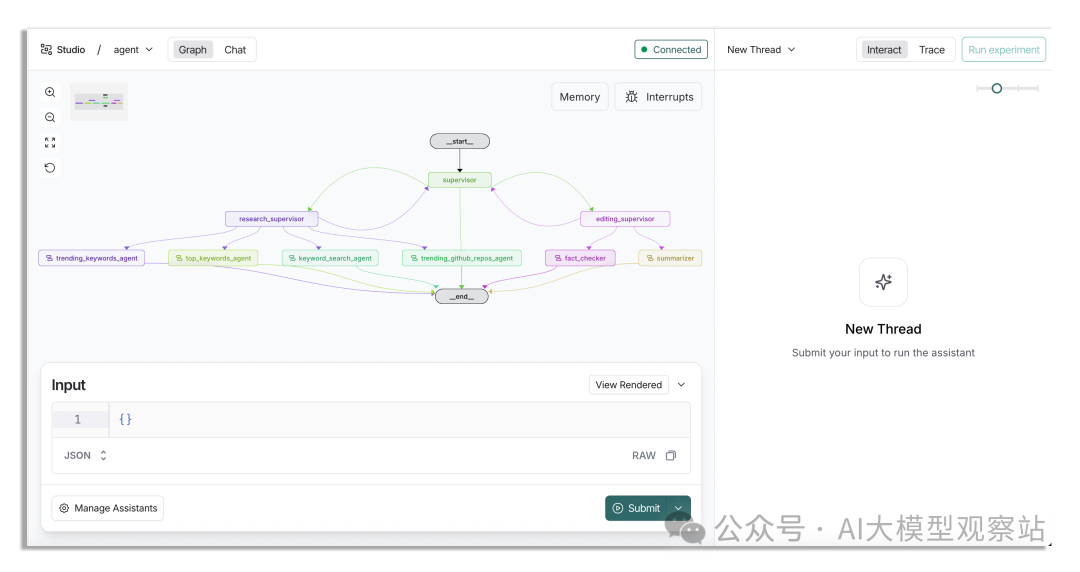 图片
图片
在这个工作流中,routes(edges)是动态设置的,而不是像单智能体那样手动设定。如果你去看代码,会显得更复杂。
运行时同样需要像上次那样给一个消息。
我这次把 prompt 写得更详细了一点,这算是有点“作弊”,你可以试试更简单的。
复制最好还是用你之前的设置,这样才能有可比性,但随你。
一旦开始运行会花挺久,你可以先离开,几分钟后再回来。
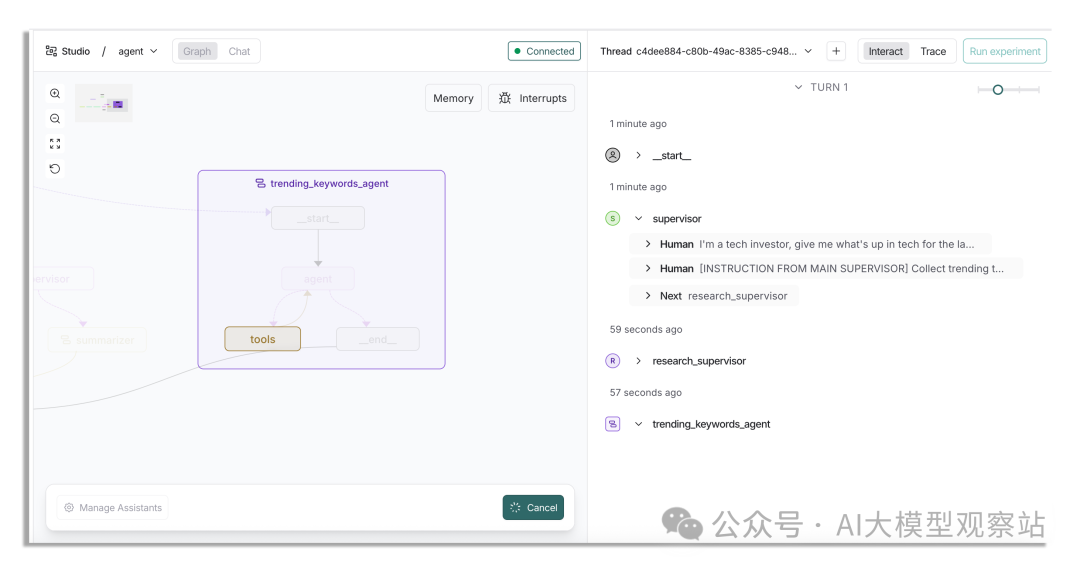 图片
图片
trending keywords agent 可用的 tools 比单智能体要复杂,因此返回更慢。
总体而言,这类系统需要时间来收集与处理信息,这点我们需要习惯。
稍后你可以在根目录下的“notes”文件夹看到它收集的笔记。示例见这里。
最终的摘要大致如下:
复制如果你不想自己运行也想看完整内容,可以点这里。
新闻内容当然会因运行时间不同而变化。我是在 10 月 28 日运行的,所以示例报告对应这一天。
关于结果,就留给你自己判断:更复杂的系统 vs 简单系统,在过程控制与输出质量上的差异。
一些收尾说明
我这里用的是一个不错的数据源。没有这一点,你就需要加很多错误处理,这会让一切更慢。
干净、结构化的数据是关键。没有它,LLM 发挥不出水平。即便数据靠谱,也不完美。你仍需打磨 agents,确保它们按预期行事。
你可能已经注意到,这个系统是可用的,但还没到“完美”。还有不少地方要改进:把用户查询解析得更结构化、为 agents 加护栏让它们总是使用自己的 tools,以及优化摘要的有效性,确保研究文档言简意赅。
我们需要更好的错误处理,或许还要加入“长期”记忆,以更好理解用户真正需要什么。State(短期记忆)在你优化性能与成本时尤其重要。
现在我们只是把每条消息都塞进 state 并让所有 agents 都能访问,这不理想。理想情况下应该按团队分离 state。在这个案例里我还没做这件事,但你可以尝试在 state schema 中引入 scratchpad 来隔离每个团队所知。


