AI

汽车行业对 AI 热潮难以持久,到 2029 年汽车企业投资可能骤减至 5%
根据科技调研机构 Gartner 的最新研究,当前汽车行业对人工智能(AI)的投资正在急剧上升,超过95% 的车企都在大力投入。 然而,这一热潮在未来可能难以维持,预计到2029年,能够持续保持强劲 AI 投入的车企仅会剩下约5%。 这意味着大部分汽车制造商的投资力度将会显著收缩。

IBM 斥资 110 亿美元收购 Confluent,助力 AI 数据基础设施升级
IBM 近日宣布将以 110 亿美元收购数据流处理公司 Confluent,每股价格为 31 美元。 Confluent 是一家基于 Apache Kafka 构建的平台,能够帮助各类组织实时移动、处理和管理数据。 此次收购表明,科技巨头们在强化生成式和智能 AI 所需的数据基础设施方面的竞争愈发激烈。

IBM 以 110 亿美元收购 Confluent,布局 AI 时代数据管理市场
IBM 近日宣布将以110亿美元的现金收购数据基础设施公司 Confluent,此举旨提升其在云端数据管理和人工智能(AI)领域的能力。 此次交易是 IBM 近年来最大规模的并购之一标志着该公司积极响应企业数字转型和 AI 技术部署的趋势。 根据公告,IBM 将以每股31美元的价格收购 Confluent 的股票,此价格较交易消息发布前一周的收盘价高出约50%。
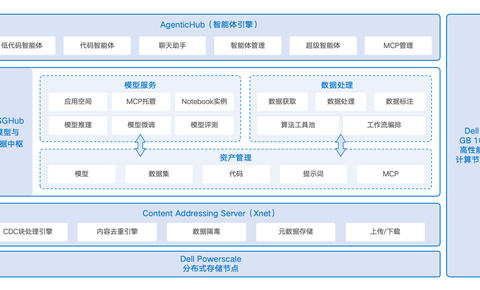
戴尔科技集团 x OpenCSG,推出⾯向智能初创企业的⼀体化 IT 基础架构解决方案
在全球智能革命加速迈进“智能体时代”的背景下, 企业级智能平台OpenCSG与戴尔科技合作,推出智算基础设施深度集成的参考架构方案。 双方将结合 OpenCSG 的 AgenticOps 方法论和 AgenticHub 平台能力,以及 Dell Pro Max with GB10 高性能计算节点与 PowerScale 智能存储系统,为企业提供低门槛、高效益、高性能的 智能化转型路径.通过这套方案,组织能够从传统信息化架构,平滑跃迁到智能原生化架构,让智能体真正走进业务一线。 CSGHub:统一算力与数据的企业级智能中枢作为 OpenCSG 的企业级 智能中枢平台,CSGHub将算力和 PowerScale 智能存储统一纳入同一套工程化工作流之中:从数据采集、特征工程、模型训练、评估与上线,到后续的监控、回滚与再训练,全流程都在 CSGHub 上被标准化编排与可视化管理。

第二十五届中国股权投资大会圆满落幕, 领航行业向新而行
2025年12月2日至5日,由清科控股(01945.HK)、投资界主办,汇通金控、南山战新投联合主办的第二十五届中国股权投资年度大会在深圳成功举行。 本届大会以“向未来,赋新生”为主题,不仅全面升级为“清科·南山创投周”,更全程创新性地融入AI科技元素,以科技感十足的呈现形式吸引了全场嘉宾的高度关注。 大会携手行业头部投资机构、产业领 袖与科技创新者,为行业发展把脉、为未来篇章布局。

解锁产业互联网新周期,他们都说了什么
离新一年的开始,只剩三个完整礼拜。 站在这个时点,我们应该如何描述产业互联网所处的阶段和挑战? “在求变生存中,产业互联网企业的思考和实践不断深化,形成三大战略方向,也是解锁新周期的三把钥匙,即产业AI、深度价值链和产业出海。

调查显示 59% 美国年轻人担心 AI 影响就业前景
根据哈佛大学青年民调(Harvard Youth Poll)最新发布的调查结果,59% 的美国年轻人(18至29岁)对人工智能(AI)可能对他们的就业前景造成冲击表示担忧。 在这群年轻人中,有26% 认为这种威胁是 “严重” 的,只有23% 的人表示完全不担心。 调查还显示,与外包和移民对就业的影响相比,年轻人对 AI 的忧虑更为显著。

Micro1 宣布年收入突破 1 亿美元,快速崛起成为 AI 数据领域新秀
成立仅三年的初创公司 Micro1近日宣布,其年度经常性收入(ARR)已超过1亿美元。 这一消息令人振奋,因为在今年年初,该公司的 ARR 仅为700万美元。 在今年9月,Micro1刚刚完成3500万美元的 A 轮融资,估值为5亿美元。

抢到票的必读:创新大会 2026 超全攻略!
点开这篇文章的朋友,恭喜你! 你们是凭手速和运气突围,成功锁定今年极客公园创新大会入场券的少数派。 为了不辜负这份期待,今年我们筹备了史上最全的内容版块,也倾注了最硬核的心思。

做难而正确的AI Infra创新——专访国产大模型推理引擎xLLM社区负责人刘童璇
在DeepSeek等国产大模型加速普及的今天,AI基础设施(AI Infra)如同数字时代的“水电煤”。 然而,长期以来,这一领域的核心技术被vLLM、TensorRT-LLM等海外框架牢牢占据。 随着一支年轻团队打造的xLLM在今年8月底出世,这一局面正悄然改变。

马斯克最新发声:奇点时代一触即发,工作将彻底可选
马斯克近日在社交平台上再度抛出颠覆性观点:人类正急速逼近“奇点”(Singularity)——一个AI与机器人主导的未来图景。 在这个时代,工作将成为纯粹的个人选择,只要你能想象,就能即时拥有所需的一切。 这番言论迅速引爆全球科技圈讨论,数小时内相关话题阅读量突破百万,引发从AI伦理到人类目的的热议。

GAIR 2025 世界模型论坛:走向真实智能的起点
这是一场关于智能体未来的深度探讨,也是一场面向青年科学家的开放对话。 在模型与智能体高速演化的当下,理解“世界”如何被建模、经验如何被抽象、行动如何被模拟,正在成为所有人工智能研究者共同追问的核心命题。 来自世界模型、智能体、强化学习、多模态理解、评估体系与开源实践领域的青年学者,将在这里共聚一堂,探讨构建“能看、能想、能行动”的下一代智能体所需的原理突破与研究路线。

报告:近半数亚洲企业将 AI 作为 2026 年战略优先事项
根据 Diligent Institute 与新加坡董事协会(SID)及澳大利亚治理协会(GIA)联合发布的《亚太治理展望 2026》报告,越来越多的亚洲企业正将人工智能(AI)作为未来战略的重中之重。 在面对日益加剧的经济和地缘政治不确定性时,近 48% 的治理领导者表示,AI 采用已成为 2026 年的首要战略优先事项。 这一比例高于追求增长机会(45%)、管理网络安全风险(39%)和应对地缘政治风险(32%)。

麦肯锡裁员约 200 个科技岗位,人工智能技术应用加速
全球知名咨询公司麦肯锡公司在过去一周内裁减了约200个科技岗位。 这一举措标志着麦肯锡在人工智能(AI)领域的应用正逐步加深,旨在通过自动化一些工作来提升效率。 这一变化与业内其他竞争对手的做法类似,许多公司正在利用 AI 来优化工作流程,减少人力成本。

研究显示:AI 到 2035 年或将取代英国 300 万个低技能岗位
根据英国国家教育研究基金会最新发布的一份报告,预计到2035年,人工智能(AI)和自动化技术可能使英国300万个 “低技能” 岗位消失。 这项研究指出,受影响最严重的职业包括技术工人、机械操作员及各类行政职位。 与此同时,AI 的发展也将导致对高技能专业人才的需求增加。

实测完“灵光”,我意识到人类对 AI 助手的开发不足1%
今天的朋友圈,被一款叫「灵光」的APP刷屏了。 了解了一下,这是一款来自蚂蚁集团的AI 应用,定位是面向普通人的零门槛全模态 AI 助手,还可以自然语言30秒生成可互动的小应用。 这让我想到了还在预热,这周即将发布的Gemini3.0,一句话生成操作系统,这都给了我们一个无限想象力的画面。

BFM-Zero,让人形机器人不再依赖高质量动捕数据
让人形机器人真正走出实验室,一直是这个领域最难的挑战。 仿真里的机器人往往动作流畅、执行准确,但一旦来到现实世界,很多看似强大的方法都会因为环境差异而迅速失效。 地面摩擦稍微变一下、身体负载多一点、传感器噪声大一些,甚至只是被人轻轻推一把,机器人就可能动作僵硬、站不稳甚至直接倒下。

当 AI 出错时,谁该为其负责?研究揭示共享责任的重要性
随着人工智能(AI)日益融入我们的日常生活,一个重要的问题随之而来:当 AI 出现错误时,谁应承担责任?AI 缺乏意识和自由意志,这使得直接指责系统本身的错误变得困难。 最近,釜山国立大学的助理教授罗亨来(Dr. Hyungrae Noh)对这一问题进行了深入研究,并提出了关于 AI 责任的分布式模型。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉