解几何题时,你是否会先画一条辅助线来帮助思考?创作一幅画时,你是否需要先理解光影和物理原理?
这种「理解」与「生成」的紧密协同,是人类智能的核心特征。近年来,AI社区致力于构建「统一多模态模型」,期望它们能像人一样,在单个模型内同时具备强大的视觉理解和内容生成能力 。
我们如何知道统一模型的生成和理解能力有何协同作用?
过去多模态评测常把理解与生成分开测,或只看表层一致性,难以揭示两者真正的交互与依赖。但很多真实任务恰恰要求“边画边想、边想边画”,体现出逻辑耦合。

为了解决这一问题,来自 S-Lab(南洋理工大学)、上海人工智能实验室、中国科学技术大学和香港中文大学的研究者们推出了 Uni-MMMU :
1.首个系统性评“理解↔生成双向增益”的基准:8 个推理中心任务,覆盖几何空间推理、STEM等强逻辑学科,分别检验“生成助理解”“理解助生成”。
2.过程+结果“双通道打分”:既看最终答案,也严查中间视觉步骤(如每一步生成图是否正确),并以可复现的程序化解析器/感知度量/模型打分综合评估,精准可复现。
3.关键发现:当前“统一模型”整体理解显著强于生成;“先生成中间态→再推理”比端到端更稳,若给到 “正确中间态(oracle)”,成绩还会显著上升。
🚀 Uni-MMMU:一个“双向奔赴”的协同基准Uni-MMMU的设计理念是“双向耦合” (bidirectionally coupled)。它涵盖了科学、编码、数学和谜题等8个以推理为中心的领域,系统地考察两种核心协同路径:
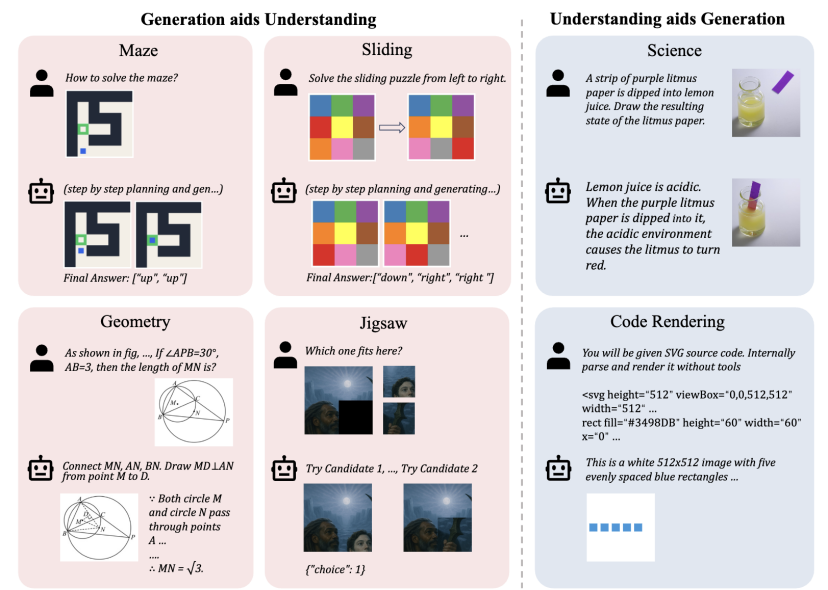
范式一:理解指导生成 (Und aids Gen)
在这类任务中,模型必须先“想明白”,才能“画得对”。
科学(物理/化学/生物): 模型需根据给定的初始状态和科学原理(如“柠檬汁是酸性的”),推理出最终的物理或化学变化,并生成描绘该结果的图像(如“紫色石蕊试纸浸入后变红”)。
代码渲染: 模型被给予原始的图形渲染源代码(SVG) ,它必须在不依赖外部工具的情况下,“读懂”代码逻辑(如形状、颜色、位置),先用自然语言描述出场景,然后再精确地将代码“渲染”成图像 。
范式二:生成辅助理解 (Gen aids Und)
在这类任务中,模型必须“边画边想”,利用生成的图像来辅助自己找到答案。
几何题: 这是对人类解题思路的直接模拟。模型需要先根据指令“画出”正确的辅助线,生成一张新图 ,然后再利用这张自己生成的图来进行逻辑推理,最终解出答案 。
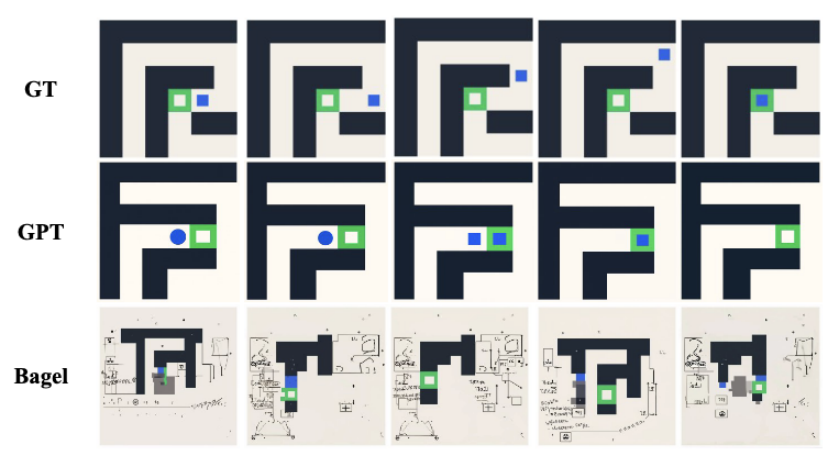
迷宫导航: 模型需要一步一步地走出迷宫 。每一步,它都必须交替生成(1)下一步的移动方向(文本)和(2)移动后迷宫的新状态(图像)。
滑块Puzzle: 类似于迷宫,模型需要规划出到达目标状态的最短路径,并交替输出文本的移动指令和对应的拼图视觉状态 。
Jigsaw拼图: 模型需要面对一块缺失的拼图和两个候选补丁 。它必须先分别生成“用候选A补全”和“用候选B补全”的两张完整图像 ,然后再“看着”自己生成的这两张图,做出判断和推理,选出正确答案 。
评价体系同样讲究:
•所有任务的理解和生成部分均提供GT,同时评估中间模态和最终答案。
•迷宫/滑块设计代码解析器将图像解析为离散状态,既算步级准确率也算整题准确率;
•拼图用 DreamSim 量化生成图与GT的感知相似度;
•几何/科学/代码引入LVLM 多维度打分,并报告Cohen’s κ与人类专家评估的一致度,强调可靠性。
🔬评估与发现研究团队使用 Uni-MMMU 对一系列开源闭源SOTA的统一模型(如 Bagel、nano-banana、GPT-4.1+GPT-image 等)和专用模型进行了全面评估 。
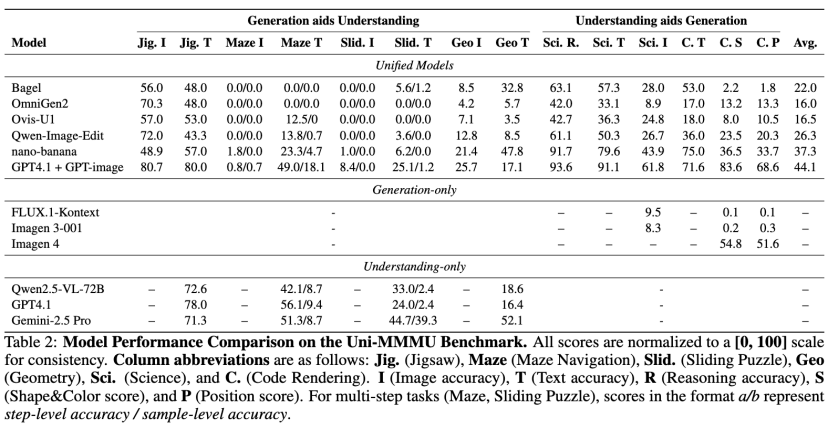
表中数据体现了开源与闭源模型之间的显著差距,此外结果也揭示了当前领域的重要见解:
发现一:生成理解协同作用真实有效
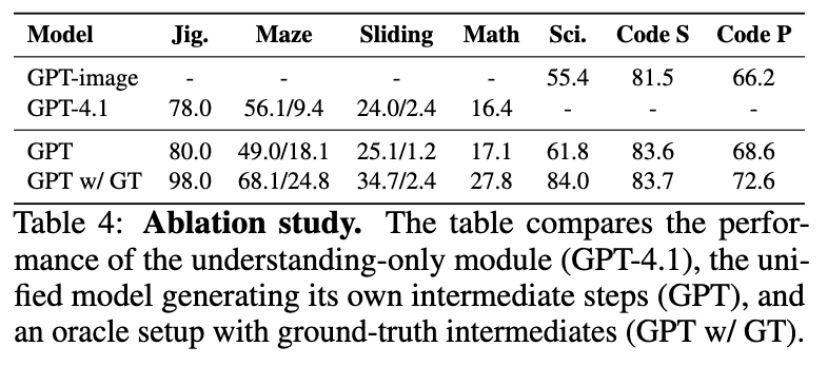
实验证明,这种「生成」与「理解」的协同是解决复杂问题的关键。分析显示,即使模型生成的中间步骤并不完美,也比完全不生成(即端到端)的方案准确率更高 。而当提供完美的中间步骤(Oracle)时,模型性能会得到巨幅提升 ,如表4所示。
发现二:当前统一模型普遍「偏科」,生成是最大瓶颈
评估暴露出一个清晰的趋势:当前统一模型严重偏向于「理解」能力,而「生成」能力是主要的瓶颈 。
模型的失败点高度集中在:
1.编辑一致性漂移
2.指令遵循不严
3.位置/拓扑偏差
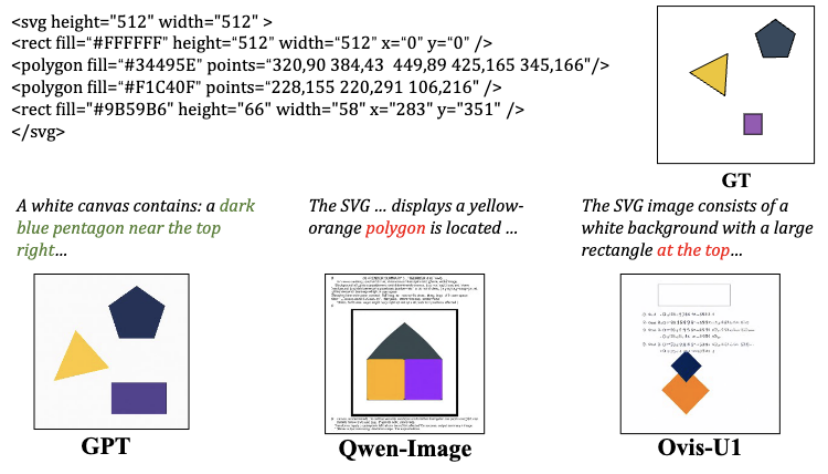
例如,在代码渲染任务中,Qwen-Image-Edit 会错误地将本应是文本描述的 SVG 代码也“渲染”到图像上 。在迷宫任务中,Bagel 则倾向于生成无法解析的“无意义符号” 。