人工智能领域发展到现在,强化学习(RL)已经成为人工智能中最令人着迷也最核心的研究方向之一。它试图解决这样一个问题:当智能体没有现成答案时,如何通过与环境的交互,自主学会最优行为?
听起来简单,做起来却异常复杂。几十年来,研究者提出了成百上千种算法,从最早的 Q-learning 到后来基于深度学习的 DDPG、SAC、PPO、IQL……每种方法都有自己的原理、参数与假设,看起来彼此独立,仿佛一座庞大而混乱的迷宫。
对于刚接触强化学习的人来说,这种复杂性常常令人挫败:我们似乎在学习无数名字,却始终难以看清它们之间的联系。
然而,最近有一篇由上海交通大学与上海期智研究院的博士生 Kun Lei 发布的博客提出了一个令人眼前一亮的框架:所有强化学习算法,其实都可以通过两个问题来理解,第一,数据从哪里来?第二,策略更新有多频繁?
就是这两个看似朴素的问题,像两根主线一样,把强化学习的世界重新梳理清楚。从它们出发,我们可以发现:复杂的 RL 算法不过是在这两根轴上移动的不同点位。
而当这一结构被揭示出来,整个算法逻辑突然变得直观、有序,也更容易被理解。

博客地址:https://lei-kun.github.io/blogs/rl.html
数据从哪里来
强化学习的过程,本质上是智能体不断收集经验、并用这些经验改进策略的循环。不同算法的差异,很大程度上取决于它们依赖什么样的数据。
最直接的方式是“在策略学习”。在这种模式下,智能体一边与环境交互,一边学习。每一个动作都带来新的数据,立刻被用于更新模型。这类方法像是不断在现场实践的学生,代表算法包括 PPO、SAC 等。
在线学习的优点是灵活、适应性强,但也意味着代价高昂,每次试错都可能耗费时间、能量,甚至造成损失。
相对保守的是“离策略学习”。它允许智能体反复使用过去的经验,而不必每次都重新与环境交互。算法会把这些经验保存下来,在需要时反复采样学习。DQN、TD3、DDPG 都属于这一类。
离策略学习提高了样本利用率,也让学习过程更稳定,是许多实际应用中的主流方案。
还有一种方式更极端,叫做“离线学习”。这里,智能体完全依赖一个固定的数据集进行训练,不能再与环境交互。这种方法看似受限,但在高风险场景中却尤为重要,比如医疗、自动驾驶或机器人控制。
算法必须在不试错的情况下,从既有数据中学会尽可能好的决策,CQL、IQL 就是这类方法的代表。
从在线到离线,数据的获取方式逐渐从主动探索转向被动利用。算法的选择往往反映了任务的现实约束:能否安全地试错?能否持续获得新数据?试错的代价是否可承受?这便是强化学习的第一个维度:数据从哪里来。
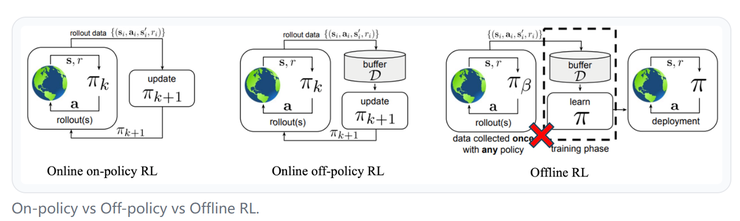
学习更新的节奏
而强化学习的第二个维度,是学习更新的节奏。简单来说,就是智能体多久评估一次策略,又多久调整一次行为。
最简单的方式是一种“一步式学习”。智能体在一个固定的数据集上训练一次,学到一个策略后就不再改进。模仿学习就是典型例子。它速度快、风险低,适合那些对安全性要求高或数据有限的任务。
另一种方式是“多步式学习”。算法在一批数据上多次更新,直到性能收敛,再重新收集新的数据。这是一种折中策略,既避免了频繁交互的高成本,又能比一次性训练获得更好的表现。
最具代表性的是“迭代式学习”。这类算法不断在“收集数据—更新模型—再收集数据”的循环中进化,每一次交互都推动性能提升。它们像一个永不停歇的学习者,不断探索未知、修正自身。PPO 和 SAC 就是这种方式的代表。
从一步到多步,再到迭代,算法的更新节奏越来越密集,也意味着从静态到动态的转变。不同节奏之间,其实反映的是对稳定性和适应性的权衡。
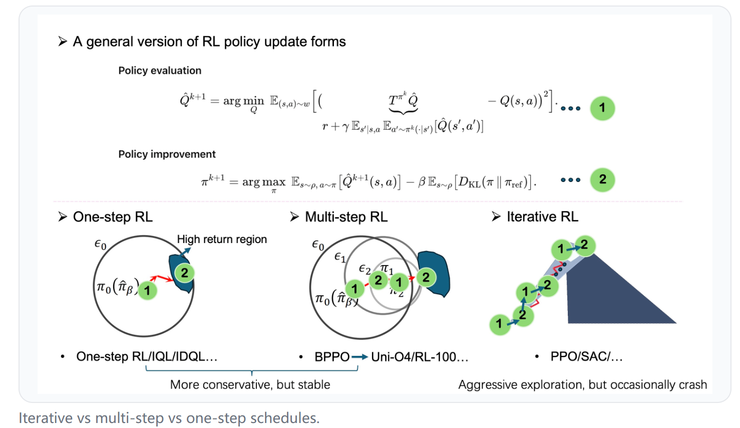
一个更底层的统一框架
在讲清楚“数据从哪来”和“学习更新的节奏”这两条主线之后,博客提出了一个更底层的统一视角:无论算法形式如何变化,所有强化学习方法其实都在做两件事:评估当前策略、然后改进它。
简单来说,强化学习就像一个反复自我练习的过程:
先评估,看看自己目前的策略表现得怎样,哪些动作好、哪些不好;
再改进,根据评估结果,调整策略,让下一次决策更聪明一点。
在博客中,作者用一组公式,把这两步统一地写了出来:
评估阶段(Policy Evaluation) 就是去衡量“这套策略到底值不值”。算法会让模型预测某个状态下采取某个动作能得到多大的回报,然后和实际反馈进行比较。如果误差太大,就调整模型,让它的预期更接近现实。在线算法直接用新数据计算,离线或离策略算法则要通过重要性采样、加权平均等方式修正旧数据的偏差。
改进阶段(Policy Improvement) 是在得到新的评估结果后,优化策略本身。模型会倾向于选择那些带来更高期望回报的动作。但为了避免一下子“改过头”,很多算法会加上约束或正则项,比如让新策略不能偏离旧策略太多(这就是 PPO 的思想),或者在策略里保留一定的探索性(这就是 SAC 中熵正则的作用)。

从这个角度看,所谓不同的强化学习算法,其实只是这两个过程的不同实现。有的算法更注重评估的准确性,有的更强调改进的稳定性,有的频繁更新、快速迭代,有的则保守谨慎、慢慢优化。
当我们用“评估 + 改进”去看强化学习时,整个算法体系就像被抽丝剥茧地展现在眼前,所有方法都不再是孤立的技巧,而是这两个动作的不同组合。
在讲清这两条主线后,博客还进一步将视角延伸到了现实世界的智能系统,尤其是当下正在快速发展的机器人基础模型。
在这样的机制下,多步式更新成为一种自然选择。每一次训练循环都带来小幅、受控的改进,既保守到能避免分布坍塌的风险,又留下足够的探索空间,使模型能够在不断扩展的数据语料中稳步成长。
并且当模型逐渐接近能力瓶颈,无论是为了超越人类在特定任务上的上限,还是为了更精准地对齐人类表现,研究者通常会转向迭代式的在线强化学习,针对特定目标进行更高频、更精细的评估与改进。
这种从多步更新向在线迭代过渡的训练策略,已在实践中被多次验证有效,例如在 rl-100 等典型设定中,多步更新已经能够在有限数据下取得稳定进步,而适量的在线 RL 则能在保持安全与稳定的前提下,将模型性能进一步推高。
走在 RL 前沿的年轻研究者
作者主页:https://lei-kun.github.io/?utm
这篇博客的作者 Kun Lei 目前是上海交通大学与上海期智研究院的博士生,师从清华大学许华哲教授。
Kun Lei 毕业于西南交通大学,在本科阶段就开始从事人工智能与优化相关的研究,并曾与西南交通大学的郭鹏教授以及美国奥本大学的王毅教授合作开展科研工作。
在读博之前,他曾在上海期智研究院担任研究助理,与许华哲教授共同进行强化学习和机器人智能方向的研究,后来又在西湖大学进行了为期四个月的科研实习,主要探索具身智能与强化学习算法在真实环境中的应用。
Kun Lei 的研究方向涵盖深度强化学习、具身智能与机器人学习。相比单纯追求算法指标,他更关心这些算法如何真正落地,怎样让强化学习不仅在仿真环境中有效,也能在真实的机器人系统中稳定工作,怎样让智能体在有限的数据下快速学习、灵活适应。
同时从他的博客也能看出,Kun Lei 的研究风格兼具工程实践与直觉思考,他追求的不是更复杂的模型,而是更清晰的理解。这篇关于强化学习的文章正体现了这种思路,他没有堆叠晦涩的公式,而是用两个最本质的问题,理出强化学习背后的逻辑主线。
而强化学习之所以让人望而却步,是因为它的理论体系庞大、公式繁复。初学者常常被各种贝尔曼方程、策略梯度、折扣回报等概念包围,每一个术语都能展开成几页推导,但却难以抓住核心。
这篇博客的价值就在于,它把这一切重新拉回了原点。作者没有从复杂的数学出发,而是提出两个最简单的问题:数据从哪里来?策略更新有多频繁?
这看似朴素的提问,其实触及了强化学习的根。它帮助读者重新看见算法的结构,不同方法之间不再是孤立的技巧,而是围绕这两个维度的不同取舍。通过这样的视角,强化学习那片看似混乱的森林,突然变得有路可循。
更重要的是,这种思路不仅仅是一种讲解方式,更是一种思考问题的习惯。它提醒我们,复杂系统的背后往往隐藏着最简单的规律,只是被层层公式和术语掩盖。当我们回到原理本身,用结构化的方式去理解问题,复杂性就不再是障碍。


