【研究颠覆】
清华大学与上海交通大学联合发表的最新论文,对业界普遍认为"纯强化学习(RL)能提升大模型推理能力"的观点提出了挑战性反驳。研究发现,引入强化学习的模型在某些任务中的表现,反而逊色于未使用强化学习的原始模型。
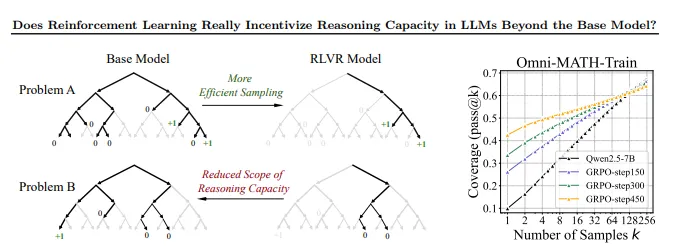
【实验验证】
研究团队在数学、编码和视觉推理三大领域进行了系统性实验:
- 数学任务:在GSM8K、MATH500等基准测试中,RL模型在低采样次数(k值)下准确率提升,但在高k值时问题覆盖率显著下降
- 编码任务:RLVR训练模型在HumanEval+等测试中单样本pass@1分数提高,但在高采样数(k=128)时覆盖率下降
- 视觉推理:Qwen-2.5-VL-7B模型在多模态任务中表现一致,RL未改变其基本问题解决策略
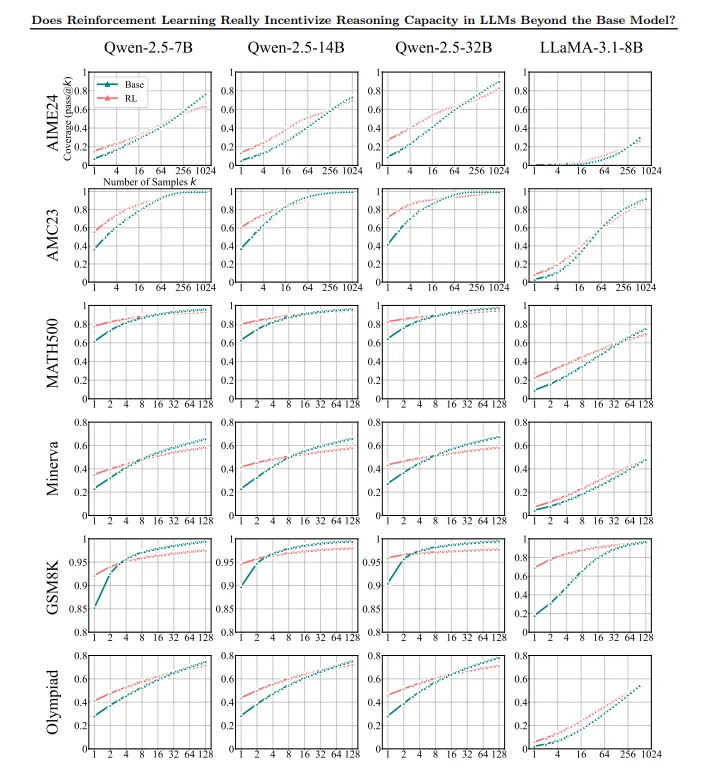
【学界争议】
研究结果引发学界激烈讨论:
- 支持方认为RL提高了采样效率但限制了推理能力开发
- 反对方指出可能是奖励结构缺陷而非RL本身问题
- 中立观点建议结合蒸馏等其他方法增强推理
【本质思考】
研究团队提出关键区分:
- 能力:模型解决问题的潜质与逻辑链条
- 效率:在给定能力范围内得出答案的速度与稳定性
强化学习更像是"能力调控器"而非"能力创造器",它能让模型更擅长做已知的事,但难以开发新的推理路径。
【行业启示】
这项研究为过热的大模型RL训练热潮敲响警钟,提示行业应:
- 更关注基础模型的表示能力与知识组织
- 明确区分能力提升与效率优化的目标
- 建立更科学的推理能力评估体系


