4B模型的数学推理能力和顶尖商业大模型差在哪里?
香港大学NLP团队联合字节跳动Seed、复旦大学发布名为Polaris的强化学习训练配方:
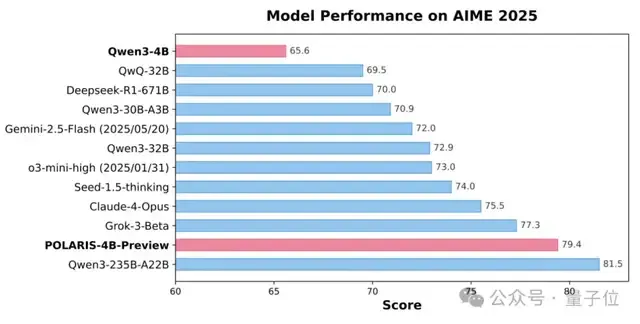
通过Scaling RL,Polaris让4B模型的数学推理能力(AIME25上取得79.4,AIME24上取得81.2)超越了一众商业大模型,如Seed-1.5-thinking、Claude-4-Opus和o3-mini-high(25/01/31)。
并且,Polaris-4B的轻量化允许在消费级显卡上部署。
详细的blog、训练数据、模型和代码都已全部开源,链接可见文末。
之前的RL训练配方,如DeepScaleR,已经展示了Scaling RL在较弱基模型上强大的效果。
但对于目前最前沿的开源模型(如Qwen3),Scaling RL是否也能复现如此显著的提升呢?
Polaris的研究团队给出了明确回答:可以!
具体来说,Polaris通过仅仅700步的RL训练,成功地让Qwen3-4B在数学推理任务上接近了其235B版本的表现。
只要方法得当,RL还存在着巨大的开发潜力。
Polaris的成功的秘籍就是:训练数据及超参数设置都要围绕待训练的模型来进行设置。
Polaris团队发现,对于同一份数据,不同能力的基模型展现出的难度分布呈现出镜像化的特征。
对于DeepScaleR-40K训练集中的每个样本,研究人员使用R1-Distill-Qwen-1.5B/7B两个模型回答分别推理了8次,再统计其中正确次数,以此衡量每个样本的难度水平。
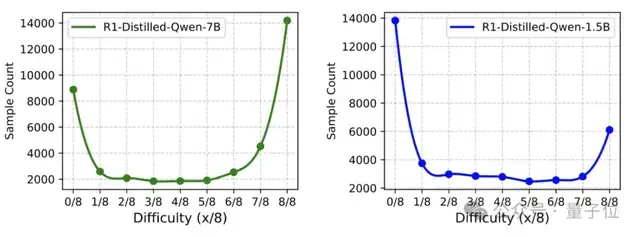
实验结果显示,大多数样本位于两端(8/8正确解答或0/8正确解答),意味着该数据集虽然对1.5B模型具有挑战性,却不足以有效训练7B模型。
Polaris提出,构建轻微偏向难题的数据分布,形状就像镜像J,过度偏向简单题或难题的分布都会使得无法产生优势的样本在每个batch中占有过大的比例。
Polaris对开源数据DeepScale-40K和AReaL-boba-106k进行了筛选,剔除所有8/8正确的样本,最终形成了53K的初始化数据集。
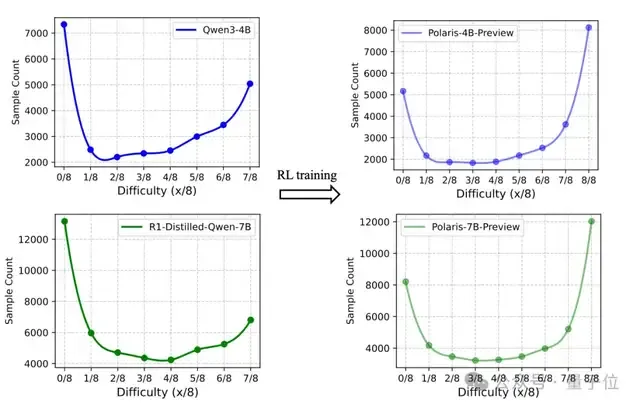
尽管已经得到了一个好的初始化数据,但它并不是训练数据的“最终版本”。
在强化学习训练过程中,随着模型对训练样本的“掌握率”提高,难题也会变成简单题。
为此,研究团队在训练中引入了数据动态更新策略。训练过程中,每个样本的通过率会随着reward计算而实时更新。在每个训练阶段结束时,准确率过高的样本将被删除。
在RL训练中,多样性被视为提升模型表现的重要因素。好的多样性使模型能探索更广泛的推理路径,避免在训练早期陷入过于确定的策略中。
Rollout阶段的多样性主要通过topp、topk与温度t来调控。当前大多数工作都采用topp=1.0和topk=-1,这已经达到了最大的多样性,但采样温度t还没有统一的设置。
目前主流的t的设置方法有两种:1、采用建议的解码温度,如Qwen3 demo中设置的0.6;2、直接设置为一个整数1.0。
但这两种做法在Polaris的实验中都不是最优解。
温度、性能与多样性的平衡之道
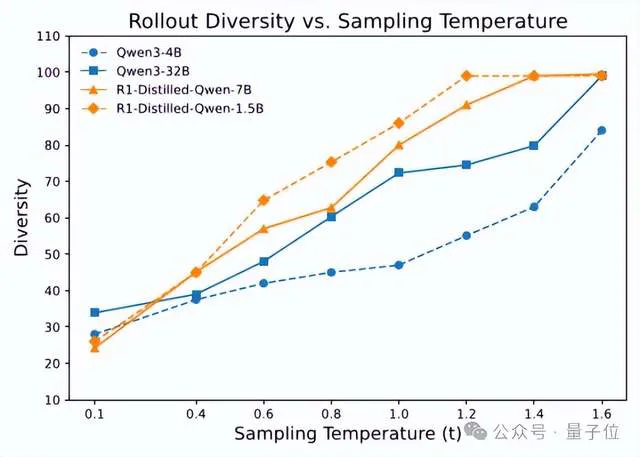
Polaris团队通过一系列试验,分析了采样温度与模型准确率及路径多样性之间的关系。
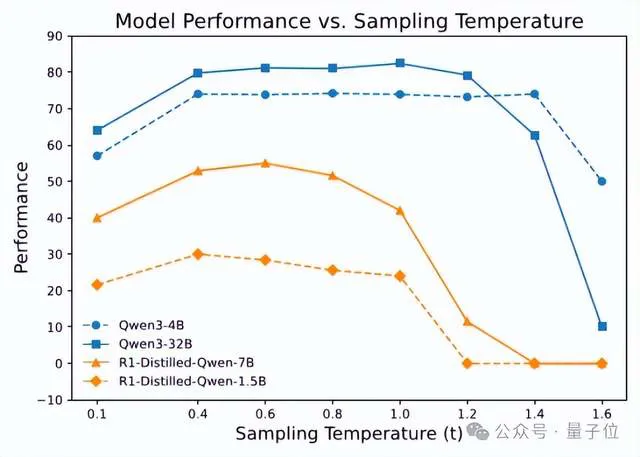
为了量化采样轨迹的多样性,他们采用Distinct N-gram指标(n=4)用于衡量生成文本中独特连续词组的比例:分数越接近1.0,说明生成内容越多样;反之则重复率较高。
结果显示,较高的温度能显著提升多样性,但不同模型在相同温度下的表现也存在较大差异。从上图来看,对于这两个模型来说,以0.6作为采样温度明显多样性是不足的。
但也并非是把温度设的越大就越好,也需要考虑性能的变化。
Polaris团队发现模型性能随温度升高呈现“低-高-低”的趋势。例如,把采样温度设置成1.0,对于Deepseek-R1-distill系列模型过高了,而对于Qwen3系列来说又有点低。
说明理想温度的设计需要针对待模型进行精细校准,没有一个超参数是适配所有模型的。
温度区间的定义
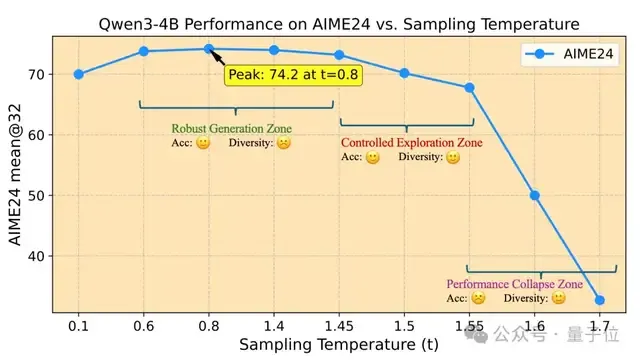
Polaris团队基于实验趋势归纳出模型采样温度的三个区域:
- 1.鲁棒生成区(Robust Generation Zone)
- 在该区域内,性能波动较小。测试阶段解码温度通常就选自鲁棒生成区。
- 2.控制探索区(Controlled Exploration Zone)
- 此区域的温度虽然会导致模型性能较鲁棒生成区略有下降,但降幅在可接受范围内,同时能显著提升多样性,适合作为训练温度使用。
- 3.性能崩塌区(Performance Collapse Zone)
- 当采样温度超出一定范围时,性能急剧下降。
根据上图规律,Polaris团队提出以控制探索区的温度作为初始化温度。
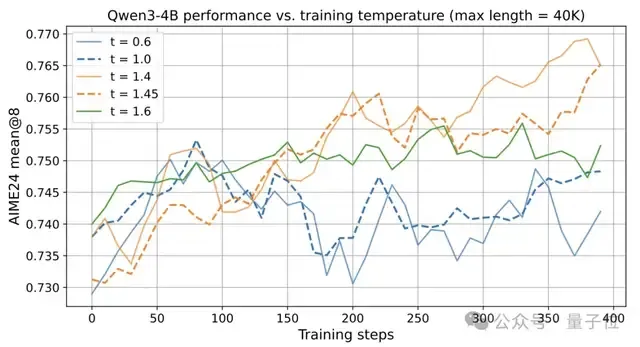
实验显示,常用的t=0.6或t=1.0的设置温度过低,限制了模型的探索空间,导致难以挖掘RL潜力。
因此,Polaris把Qwen3-4B的初始训练温度设置为1.4。
动态温度调整
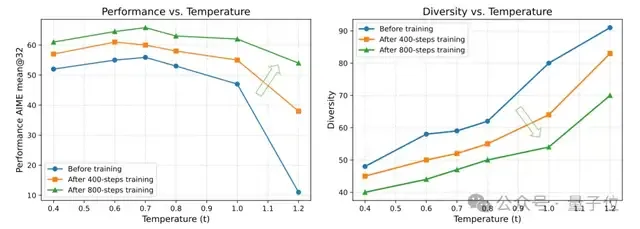
在性能增长的同时,多样性同样也会发生偏移。随着训练收敛,各路径间共享的N-gram比例增加,探索空间也随之缩小。
在整个训练过程中始终使用最开始的温度,会导致训练后期多样性不足。
因此,Polaris团队提出在RL训练过程中动态更新采样温度的策略:在每个阶段开始前都进行和温度初始化时类似的搜索方法,使得后续阶段起始的多样性分数和第一阶段的相似。
举个例子,假如第一阶段开始的多样性分数是60,那此后的每个阶段,Polaris团队都会选择一个能把多样性分数拉到60的温度来进行训练。
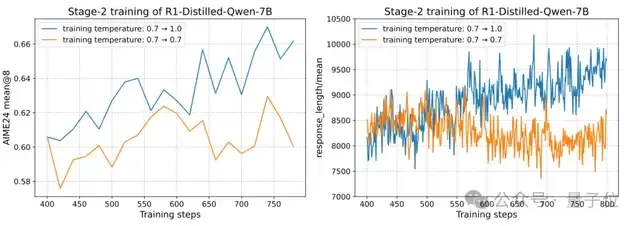
对比实验的结果显示,采用同一温度训练到结束,其效果不及多阶段温度调整。
多阶段温度调整不仅带来了更优的RL训练效果,还使得回答长度的提升更加稳定。
在训练Qwen3-4B的过程中,一个显著难题在于长上下文训练,因为模型本身的回答长度就已经非常长了,要继续训练的更长需要更高昂的计算代价。
Qwen3-4B的模型预训练上下文长度仅有32K,而RL阶段Polaris将最大训练长设定为52K。但实际达到最大序列长度的训练样本比例不足10%,意味着真正使用长文本进行训练的样本非常有限。
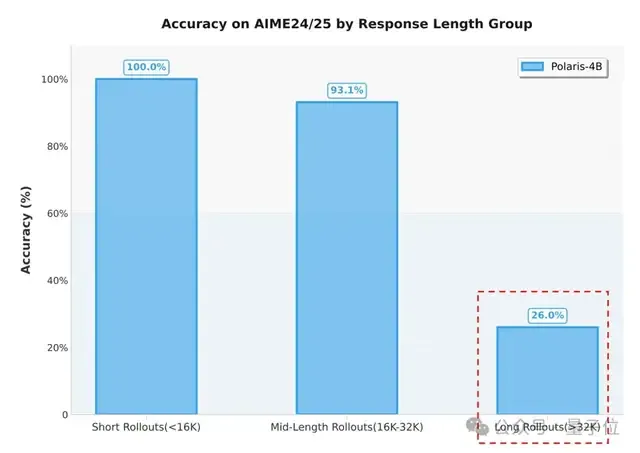
为评估Polaris-4B-Preview的长文生成能力,Polaris究团队选取了AIME2024/25中的60题,每题进行32次推理,总计1920个样本,并按照回答长度将其分为三组:
- 短文本组:回答长度小于16K;
- 中等文本组:回答长度介于16K到32K;
- 长文本组:回答长度超过预训练长度32K。
统计结果表明,长文本组的准确率仅为26%,证明模型在生成超过预训练长度的长CoT时,性能明显受限。
既然RL在长上下文长度的时候具备劣势,那么长CoT性能不佳可能是由于长文本训练不充分导致。
针对长文本训练样本不足的问题,团队引入了长度外推技术。通过位置编码RoPE的调整,模型能够在推理时处理超出训练时所见的更长序列,进而补偿长文本训练中的不足。
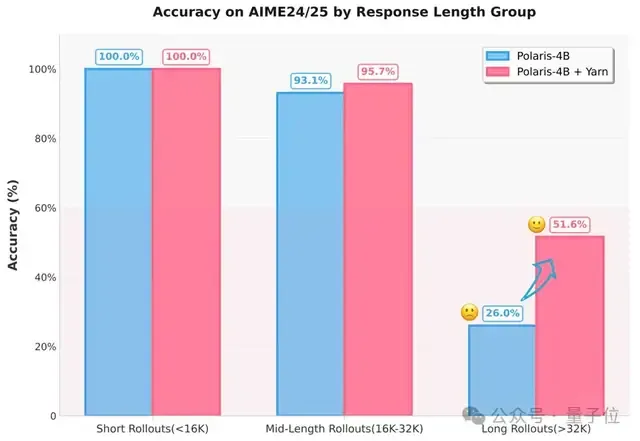
具体实现上,研究团队采用了YaRN作为外推方法,并设置扩展因子为1.5,如下配置所示:

实验结果显示,通过应用该策略,超过32K长度回答的准确率由26%提升至超过50%
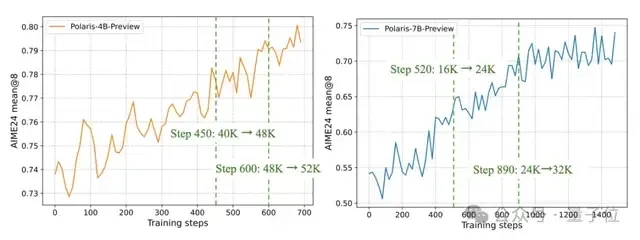
Polaris采用多阶段的训练方式,在早期阶段,模型使用较短的上下文窗口;待模型表现收敛后,再逐渐增加上下文窗口的长度以拓宽模型的推理能力。
尽管这一策略在某些模型下有效,但在多阶段训练中,初始阶段选择合适的最大长度至关重要,不同基础模型token利用效率存在差异。
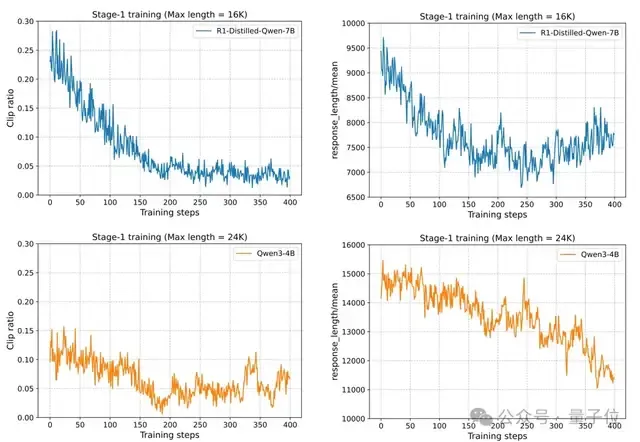
实验发现,对于DeepSeek-R1-Distill-Qwen-1.5B/7B,采用较短的响应长度训练效果都较好;但对Qwen3-4B来说,即使响应长度只有24K且响应截断比例低于15%,其性能也会急剧下降,这种下降即使在后期阶段也难以恢复。
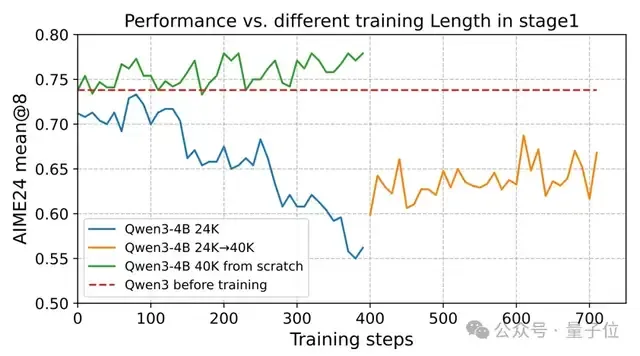
通常来说,从一开始就让模型“思考更长”会更安全:对于Qwen3-4B,实验观察到从零开始使用40K响应长度时性能稳步提升,这与从一开始就采用24K和24K→40K的方案形成了鲜明对比。
要点:当计算资源允许时,直接从官方仓库建议的最大解码长度开始。
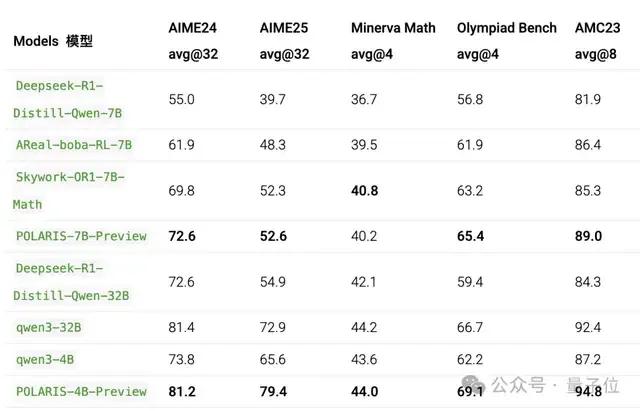
Polaris模型需要使用比Qwen3更高的采样温度和更长的响应长度;所有其他设置保持相同。
对于AIME24和AIME25,上表报告了32次运行的平均性能。
可以看到,Polaris让4B模型的数学推理能力(AIME25上取得79.4,AIME24上取得81.2)超越了一众商业大模型,在大多数评测中表现最佳。
notion地址: https://honorable-payment-890.notion.site/POLARIS-A-POst-training-recipe-for-scaling-reinforcement-Learning-on-Advanced-ReasonIng-modelS-1dfa954ff7c38094923ec7772bf447a1 blog 地址: https://hkunlp.github.io/blog/2025/Polaris/ 代码: https://github.com/ChenxinAn-fdu/POLARIS Huggingface主页: https://huggingface.co/POLARIS-Project


