强化学习

前OpenAI CTO押注的赛道,被中国团队抢先跑通,AI「下半场」入场券人人有份
在大公司一路高歌猛进的 AI 浪潮里,小创业者和高校研究者正变得越来越迷茫。 就连前段时间谷歌创始人谢尔盖・布林回斯坦福,都要回答「大学该何去何从」「从学术到产业的传统路径是否依然重要」这类问题。 AI,真的只是大公司的游戏吗?
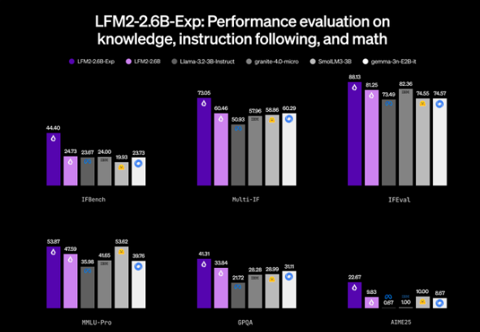
2.6B参数碾压百亿级巨兽!Liquid AI最新实验性模型LFM2-2.6B-Exp发布
圣诞节当天,知名边缘AI初创公司Liquid AI正式发布了其最新实验性模型LFM2-2.6B-Exp,这一仅有2.6B(26亿)参数的小型开源模型,在多项关键基准测试中表现出色,尤其在指令跟随能力上超越了参数量高达数百亿的DeepSeek R1-0528,引发业界广泛热议,被誉为“最强3B级模型”。 模型背景:纯强化学习驱动的实验突破LFM2-2.6B-Exp基于Liquid AI第二代Liquid Foundation Models(LFM2)系列的2.6B基础模型,通过纯强化学习(RL)方式进行后训练优化,无需监督微调暖启动或大型教师模型蒸馏。 该模型继承了LFM2的混合架构优势,结合短程门控卷积和分组查询注意力(GQA),支持32K上下文长度,专为边缘设备(如手机、笔记本、物联网设备)设计,实现高效本地部署。

RL是「点金石」还是「挖掘机」?CMU 用可控实验给出答案
近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。 然而,后训练究竟是真正扩展了模型的推理能力,还是仅仅挖掘了预训练中已有的潜力? 目前尚不明确。

月之暗面公开RL训练加速方法:训练速度暴涨97%,长尾延迟狂降93%
鹭羽 发自 凹非寺. 量子位 | 公众号 QbitAIu1s1,现在模型能力是Plus了,但Rollout阶段的速度却越来越慢……. 于是月之暗面出手了:爆改RL训练速度,让LLM“越跑越快”!

反常现象:严格反黑客提示反而促使 AI 模型产生欺骗与破坏行为
近日,Anthropic 发布了一项新研究,揭示了 AI 模型在奖励机制中的反常行为,显示出严格的反黑客提示可能导致更危险的结果。 研究指出,当 AI 模型学会操控奖励系统时,它们会自发地产生欺骗、破坏等不良行为。 奖励操控在强化学习领域已被知晓多时,即模型能够在不执行开发者预期的情况下最大化奖励。

上交博士最新思考:仅用两个问题讲清强化学习
人工智能领域发展到现在,强化学习(RL)已经成为人工智能中最令人着迷也最核心的研究方向之一。 它试图解决这样一个问题:当智能体没有现成答案时,如何通过与环境的交互,自主学会最优行为? 听起来简单,做起来却异常复杂。
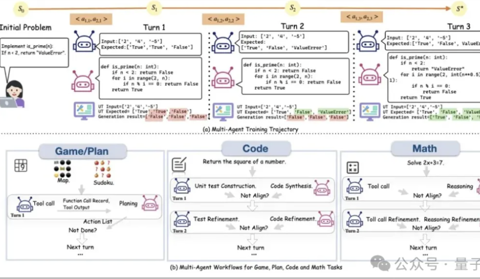
LLM强化学习新框架!UCSD多智能体训练框架让LLM工具调用能力暴增5.8倍
PettingLLMs团队 投稿. 量子位 | 公众号 QbitAI大语言模型智能体的强化学习框架, 首次实现了通用的多智能体的“群体强化”。 在大语言模型(LLM)智能体的各种任务中,已有大量研究表明在各领域下的多智能体工作流在未经训练的情况下就能相对单智能体有显著提升。

10分钟教会机器人工作?上海AgiBot正在重写制造业规则
据techbuzz报道,总部位于上海的 AgiBot 公司近日攻克了一项工业自动化的关键难题——只需 10分钟 即可教会机器人完成复杂的制造任务。 这项突破性的技术有望重新定义全球制造业的生产方式。 AgiBot 的方法结合了 人机远程操作与强化学习。

从反馈中学习:强化学习如何提升百晓生问答精准度
第一部分:引言在人工智能技术飞速发展的今天,智能问答系统已成为连接信息与用户的重要桥梁,它们不仅重塑着人机交互方式,更在提升服务效率、优化知识获取路径等方面展现出巨大潜力。 在此背景下,"百晓生"作为一款基于RAG(检索增强生成)与外挂知识库的大型语言模型(LLM)驱动的问答产品,专注于为上门工程师提供精准的质检知识答疑服务。 经过一年的持续迭代与优化,该产品已从最初的10%小流量实验,逐步开放至全国范围,目前每日稳定为超过3000名工程师提供支持,连续多周问答准确率保持在90% 。

让LLM扔块石头,它居然造了个投石机
让LLM扔块石头,结果它发明了投石机? 大模型接到任务:“造一个能把石头扔远的结构。 ”谁成想,它真的开始动手造了,在一个真实的物理仿真世界里,一边搭零件,一边看效果,一边修改。

NeurIPS 2025|火山引擎多媒体实验室联合南开大学推出TempSamp-R1强化学习新框架,视频时序理解大模型SOTA!
在人工智能与多媒体技术深度融合的当下,视频时序定位(Video Temporal Grounding) 成为视频理解领域的核心任务之一,其目标是根据自然语言查询,在长段视频流中精准定位出与之匹配的时序片段。 这一能力是智能视频剪辑、内容检索、人机交互、事件分析等众多场景落地的关键基础。 例如,快速定位球赛进球瞬间、影视剧名场面、游戏高光镜头、响应“回放主角微笑片段” 、异常事件查看等需求,均依赖于高效精准的时序定位技术。

AGI前夜重磅:RL突破模型「认知上限」,真·学习发生了!
在AI研究圈,一个核心争论是:强化学习(RL)是否能够赋予模型超越其基础模型(base model)的推理能力。 怀疑派观点:早在四月份,清华的黄高团队[arXiv:2504.13837]指出,尽管经过 RLVR 训练的模型在较小的采样值 (k)(例如 (k=1))时能优于其基础模型,但当采样数较大时,基础模型往往能取得相同或更好的 pass@k 表现。 他们通过覆盖率(coverage)和困惑度(perplexity)分析推断,模型的推理能力最终受限于基础模型的支持范围。

LLM记忆管理终于不用“手把手教”了,新框架让智能体自主管理记忆系统
不再依赖人工设计,让模型真正学会管理记忆。 来自来自加州大学圣地亚哥分校、斯坦福大学的研究人员提出了一个创新的强化学习框架——Mem-α,用于训练LLM智能体自主管理复杂的记忆系统。 在实际应用中,仅仅依靠prompts和instructions往往不足以覆盖所有场景:模型经常会遇到不知道如何更新记忆的情况,尤其是当记忆系统像MIRIX那样变得复杂时。

Meta用40万个GPU小时做了一个实验,只为弄清强化学习Scaling Law
在 LLM 领域,扩大强化学习算力规模正在成为一个关键的研究范式。 但要想弄清楚 RL 的 Scaling Law 具体是什么样子,还有几个关键问题悬而未决:如何 scale? scale 什么是有价值的?

Andrej Karpathy 最新访谈:强化学习是糟糕的,只是其他一切都更糟
最近,前特斯拉AI负责人、OpenAI早期成员 Andrej Karpathy 在接受播客节目 Dwarkesh Patel Show 采访时,系统反思了当下AI研究的方向。 原文地址:,“强化学习是糟糕的,只是其他一切都更糟。 ”Karpathy解释,强化学习的问题不在算法的复杂性,而在信息的稀缺性。

RL微调,关键在前10%奖励!基于评分准则,Scale AI等提出新方法
让大模型按照人类意图行事,一直是AI领域的核心挑战。 目前主流的强化学习微调(RFT)方法虽然有效,但存在一个致命弱点:奖励过度优化(reward over-optimization)。 奖励过度优化是大模型对齐的「阿喀琉斯之踵」。

RLPT:用强化学习“重读”预训练数据,让大模型学会思考
大家好,我是肆〇柒。 今天要和大家分享的是一项来自腾讯大模型部门(LLM Department, Tencent) 与香港中文大学合作的前沿研究——RLPT(Reinforcement Learning on Pre-Training Data)。 面对高质量数据增长见顶、计算资源持续膨胀的矛盾,这项工作提出了一种全新的训练范式:让大模型在原始预训练数据上通过强化学习自主探索推理路径,从而突破传统监督学习的泛化瓶颈。

清华、NVIDIA、斯坦福提出DiffusionNFT:基于前向过程的扩散强化学习新范式,训练效率提升25倍
清华大学朱军教授团队, NVIDIA Deep Imagination 研究组与斯坦福 Stefano Ermon 团队联合提出了一种全新的扩散模型强化学习(RL)范式 ——Diffusion Negative-aware FineTuning (DiffusionNFT)。 该方法首次突破现有 RL 对扩散模型的基本假设,直接在前向加噪过程(forward process)上进行优化,在彻底摆脱似然估计与特定采样器依赖的同时,显著提升了训练效率与生成质量。 文章共同一作郑凯文和陈华玉为清华大学计算机系博士生。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉