大家好,我是肆〇柒。推理能力在当下 AI 领域,尤其自然语言处理、智能决策系统、科学研究辅助等众多关键领域,已然成为推动技术革新的关键要素。然而,目前大型语言模型虽已取得瞩目成果,但在处理复杂逻辑时,常受困于逻辑连贯性把控,长链推理面临信息丢失、逻辑断裂问题,长序列输出任务下推理耗时久、资源消耗大,这些痛点严重制约模型应用场景拓展与性能深化。
现有强化学习(RL)系统在提升模型推理能力方面也遇到发展瓶颈。同步强化学习系统在训练过程中,GPU 利用率低、可扩展性差等问题凸显。以同步 RL 系统处理长序列输出为例,系统需等待批次中最长序列完成才开启训练,因序列长度差异大,GPU 等待时间漫长,运算资源闲置浪费严重。不仅如此,随着模型规模扩大、序列长度增加,同步系统扩展性不足,训练效率直线下滑。这些难题倒逼业界寻求创新解决方案,由清华大学与蚂蚁研究院联合研发的 AREAL 系统被提出并开源。AREAL 作为全新完全异步大型强化学习系统,凭借独特架构与创新算法,实现训练效率和模型性能的跨越式提升。
以 AIME24 基准测试为例,1.5B 模型和 7B 模型训练中,推理设备因等待时间过长,训练效率备受打击。同步系统执行时,长序列输出需全部完成才进入下一步,设备空转、运算停滞,极大拖延训练进程。AREAL 在此做了优化,直击同步系统要害,以创新异步架构重塑强化学习训练流程。其核心在于完全解耦生成与训练环节,生成过程不受训练等待限制,训练流程即时响应生成数据,高效利用每一秒运算时间,打破同步系统枷锁,为模型推理训练铺就高速通道。本文将介绍 AREAL 的优势、架构、算法革新及实验成果。一起了解一下吧。
AREAL 的系统架构
AREAL 的系统架构是其高效运行的核心基础,通过精心设计的四大核心组件——可中断的 Rollout Worker、奖励服务、Trainer Worker 和 rollout 控制器,实现了完全异步的强化学习训练流程。下图展示了同步 RL 系统和单步重叠 RL 系统的执行时间线,突出同步系统中推理设备的低效利用问题。
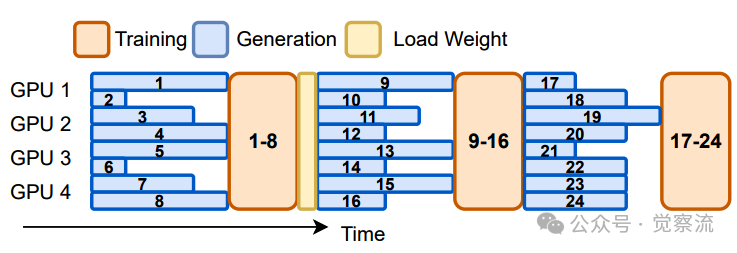
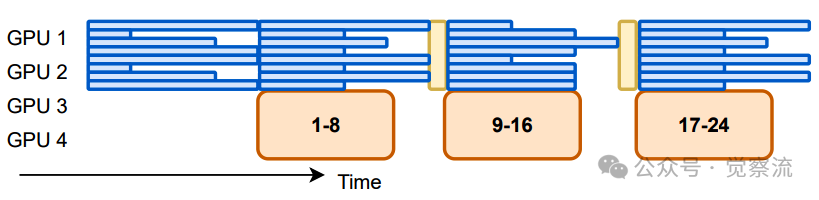
同步(上)和单步重叠(下)强化学习系统的执行时间线,展示了未充分利用的推理设备
1. 可中断的 Rollout Worker
Rollout Worker是 AREAL 系统中负责生成数据的关键组件。它主要处理两类请求:生成请求和更新权重请求。在生成请求中,Rollout Worker根据当前模型的参数,为给定的提示(prompt)生成响应。这一过程是连续的,每个Rollout Worker独立运行,无需等待其他组件完成任务,从而最大化 GPU 的利用率。
当系统需要更新模型参数时,Rollout Worker会收到更新权重请求。此时,Rollout Worker会立即中断当前正在进行的生成任务,丢弃旧参数计算的 KV 缓存,并重新加载新的模型参数。加载完成后,Rollout Worker会继续从上次中断的地方开始生成剩余的序列。这一过程不仅确保了生成数据的实时性,还通过缓冲机制保持了训练批次的大小一致,从而维持了 PPO 算法的稳定性。
2. 奖励服务
奖励服务是 AREAL 系统中负责评估生成数据质量的组件。它接收 Rollout Worker生成的响应,并根据预定义的奖励函数计算每个响应的奖励值。例如,在代码生成任务中,奖励服务会提取生成的代码片段,运行单元测试,并根据代码的执行结果和规范性给出奖励分数。在数学推理任务中,奖励服务会验证生成的答案是否正确,并据此给出奖励。
奖励服务的高效性对于整个系统的性能至关重要。AREAL 通过将奖励计算与 GPU 计算分离,并利用多线程和异步编程技术,确保奖励计算不会成为系统的瓶颈。这种设计使得奖励服务能够快速响应,及时将奖励信息反馈给Trainer Worker ,从而加速整个训练流程。
3. Trainer Worker
Trainer Worker 是 AREAL 系统中负责模型更新的核心组件。它们从回放缓冲区(replay buffer)中采样数据,当数据量达到配置的批次大小时,Trainer Worker 会执行 PPO 更新,并将更新后的模型参数存储到分布式存储中。Trainer Worker 的高效运行依赖于多个关键设计:
- 动态批处理策略:Trainer Worker 采用动态批处理策略来处理可变长度的输出序列。该策略根据序列长度对数据进行排序,并将长度相近的序列分配到同一个微批次中,从而最大化 GPU 内存的利用率。通过减少不必要的填充操作,Trainer Worker 能够显著提高训练吞吐量。
- 并行更新:Trainer Worker 可以并行运行多个更新任务,充分利用多 GPU 的计算能力。这种并行化设计进一步提升了系统的整体性能。
4. Rollout 控制器
Rollout 控制器是 AREAL 系统中负责协调各组件的关键组件。它在数据集、Rollout Worker、奖励服务和Trainer Worker 之间起到桥梁的作用。在训练过程中,rollout 控制器从数据集中读取数据,并向 Rollout Worker 发送生成请求。Rollout Worker生成的响应会被发送到奖励服务进行评估,评估结果(即奖励值)和生成的轨迹一起存储在回放缓冲区中。当Trainer Worker 完成模型更新后,rollout 控制器会通知 Rollout Worker 更新权重。
Rollout 控制器的高效协调能力是实现异步训练的关键。它通过精确控制数据的流动和任务的调度,确保生成和训练过程能够无缝衔接。此外,rollout 控制器还负责监控系统的整体状态,及时调整任务分配策略,以应对不同任务和模型规模的需求。下图展示了 AREAL 的架构,包括异步生成和训练组件。
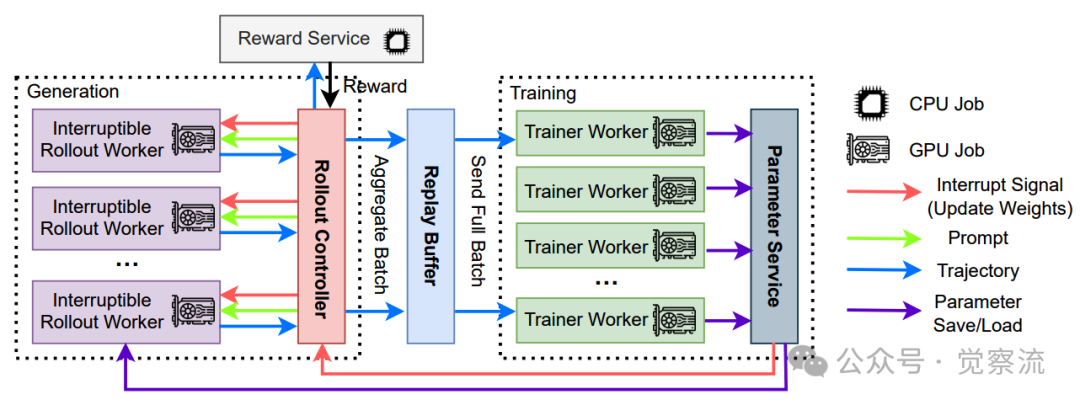
具有异步生成和训练组件的AREAL架构
异步训练流程
AREAL 的异步训练流程是其区别于传统同步 RL 系统的核心特征。在同步 RL 系统中,生成和训练是严格交替进行的,生成步骤必须等待批次中最长的序列完成才能开始训练,这导致了 GPU 的大量闲置时间。而 AREAL 完全解耦了生成和训练过程,Rollout Worker 和 Trainer Worker 可以独立运行,互不等待。
- 生成过程:Rollout Worker以流式的方式持续生成新的输出,无需等待其他工作者完成任务。这种设计使得 GPU 能够始终保持高利用率,显著提高了系统的整体效率。
- 训练过程:Trainer Worker 在获得一批数据后立即开始更新模型,无需等待生成过程完成。更新完成后,模型参数会同步到所有 Rollout Worker,确保生成数据始终基于最新的模型版本。
通过这种异步设计,AREAL 不仅解决了同步系统中 GPU 利用率低的问题,还实现了高效的分布式训练,能够轻松扩展到数千个 GPU。这种架构为大规模强化学习训练提供了强大的支持,使得 AREAL 能够在复杂的推理任务中展现出卓越的性能。下图演示了 AREAL 的生成管理,包括训练就绪时间和新参数到达时的中断请求。
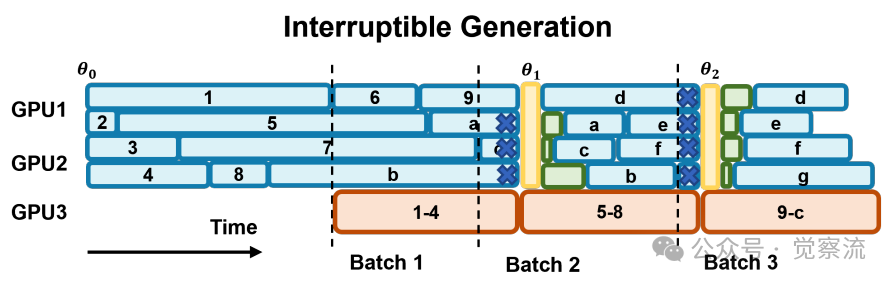
在 AREAL 中的生成管理示意图。垂直线表示下一步训练的准备就绪时间。蓝色叉号表示在新参数到达时被中断的请求
AREAL 的系统优化
AREAL 通过一系列系统级优化措施,显著提升了异步强化学习训练的效率和稳定性。这些优化策略涵盖了从硬件资源管理到数据处理的各个环节,为高效的模型训练提供了坚实基础。
1. GPU 与 CPU 资源分离
AREAL 将 GPU 计算与 CPU 操作分离,避免了两者之间的相互干扰,提升了整体运算效率。系统将规则化奖励计算及基于 TCP 的数据传输等操作分配给 CPU 执行,而将复杂的神经网络计算任务留给 GPU。通过在不同线程中独立运行这些任务,并利用流水线技术将它们有机结合起来,AREAL 实现了奖励计算和数据传输与后续生成请求的并行处理,充分利用了多核 CPU 和 GPU 的并行计算能力,从而显著提高了系统的吞吐量。
2. 可中断的 Rollout Worker
可中断的 Rollout Worker是 AREAL 系统中实现高效训练的关键机制之一。在传统的同步 RL 系统中,生成任务必须等待当前批次中最长的序列完成才能进行下一步操作,这导致了 GPU 的大量闲置时间。而 AREAL 的 Rollout Worker 能够在接收到更新权重的信号时,立即中断当前正在进行的生成任务,丢弃旧参数计算的 KV 缓存,并重新加载新的模型参数。加载完成后,Rollout Worker 会从上次中断的地方继续生成剩余的序列。这一过程不仅确保了生成数据的实时性,还通过缓冲机制保持了训练批次的大小一致,从而维持了 PPO 算法的稳定性。这种可中断的机制使得 Rollout Worker 能够快速响应模型参数的更新,避免了因等待长序列完成而导致的资源浪费,显著提高了 GPU 的利用率和训练效率。通过以下图表可以更直观地了解可中断生成对系统性能的影响:
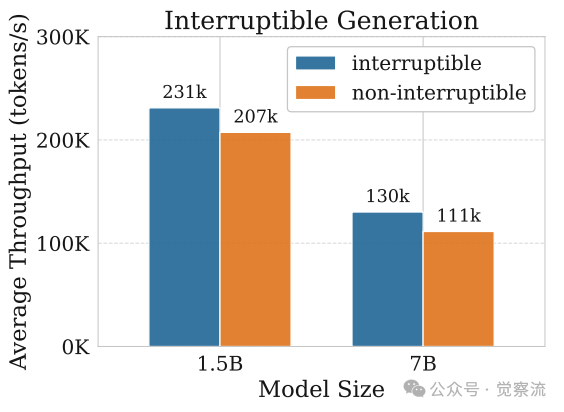
可中断的 Rollout 消融研究
3. 动态批处理策略
AREAL 采用了动态批处理策略来处理可变长度的输出序列,这一策略在固定内存约束下实现了对 token 分布的优化平衡。系统会根据序列长度对数据进行排序,然后将长度相近的序列分配到同一个微批次中,从而最大化 GPU 内存的利用率。通过减少不必要的填充操作,AREAL 能够显著提高训练吞吐量。此外,动态批处理策略还能够根据当前可用的 GPU 内存动态调整微批次的大小,确保在不同模型规模和序列长度下都能充分利用 GPU 资源。这种灵活的批处理方式不仅提高了内存利用率,还减少了前向 - 后向传递的次数,进一步提升了训练效率。动态微批分配策略对系统吞吐量的提升效果显著,下图展示了相关的消融研究结果:
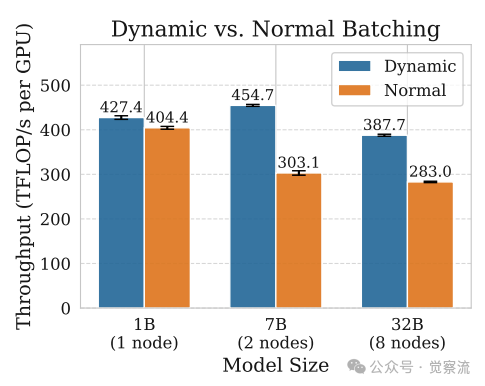
动态微批次分配的消融研究
4. 并行奖励服务
为了进一步提升系统的效率,AREAL 引入了并行奖励服务。在传统的 RL 系统中,奖励计算通常是串行进行的,这成为了系统的性能瓶颈之一。AREAL 通过将奖励计算任务分配给多个并行的奖励服务进程,实现了对奖励计算的并行化处理。每个奖励服务进程独立地对生成的响应进行评估,并计算相应的奖励值。这种并行化的奖励服务不仅提高了奖励计算的速度,还能够更好地利用多核 CPU 的计算能力,从而进一步加快了整个训练流程。
5. 异步通信机制
AREAL 采用了高效的异步通信机制,确保了系统各组件之间的快速数据传输和同步。在异步训练过程中,生成的数据需要及时传递给Trainer Worker 进行模型更新,而更新后的模型参数也需要迅速同步到 Rollout Worker,以便生成新的数据。AREAL 通过使用消息队列和异步通信协议,实现了数据的快速传递和组件之间的无缝衔接。这种异步通信机制不仅减少了数据传输的延迟,还提高了系统的整体吞吐量,使得 AREAL 能够在大规模分布式训练环境中高效运行。
6. 资源调度与负载均衡
AREAL 还在资源调度和负载均衡方面进行了优化。系统能够根据当前的任务需求和资源使用情况,动态调整各组件的资源分配。例如,在生成任务较重时,系统会优先分配更多的 GPU 资源给 Rollout Worker;而在训练任务较重时,则会将更多的资源分配给Trainer Worker 。此外,AREAL 还通过负载均衡算法,确保了各个 GPU 和 CPU 核心之间的负载均衡,避免了部分资源过载而其他资源闲置的情况。这种动态的资源调度和负载均衡策略,使得 AREAL 能够在不同的训练阶段和任务场景下,始终保持高效的资源利用率和稳定的训练性能。
通过以上一系列系统级优化措施,AREAL 在硬件资源利用、数据处理效率和训练稳定性等方面都取得了显著的提升。这些优化策略不仅为 AREAL 的高效异步训练提供了有力支持,也为其他大规模强化学习系统的开发提供了宝贵的参考。
AREAL 的算法创新
AREAL 的算法创新是其高效异步训练的核心驱动力,主要体现在对数据陈旧性问题的应对策略以及解耦的 PPO 目标函数的提出。下图演示了 PPO 的解耦目标和陈旧性控制的消融研究,展示了算法选择对训练结果的影响。
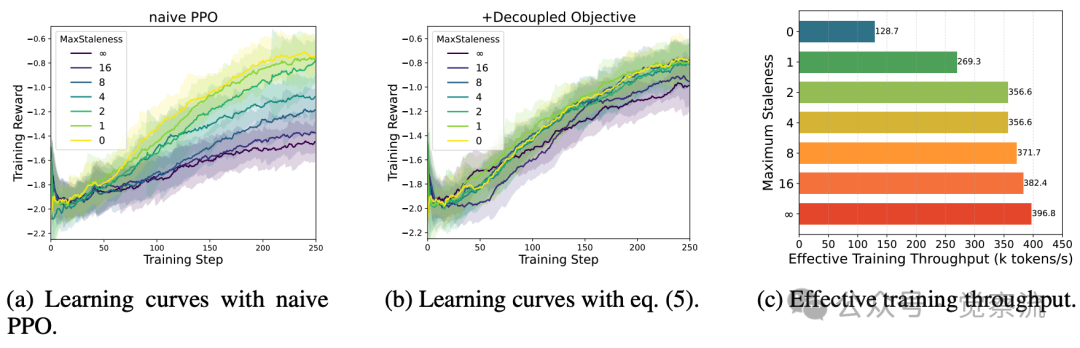
对分离的PPO目标和陈旧性控制进行了消融研究。这两种算法选择都至关重要。在采用适中的陈旧性值和分离目标的情况下,训练进度可以加快2倍以上,同时保持最终评估性能不变
数据陈旧性问题与解决方案
在异步强化学习系统中,数据陈旧性是一个关键挑战。由于生成和训练过程完全解耦,训练批次中可能包含由不同版本策略生成的数据。这种陈旧性可能导致训练数据的策略分布与当前最新策略产生偏差,从而影响学习性能。AREAL 通过引入最大允许陈旧度 η 这一超参数,对策略版本差异进行严格限制。具体而言,假设当前最新参数版本为 i,系统共生成了 Nr 条轨迹,训练批次大小为 B,则要求 ⌊Nr/B⌋ ≤ i + η。系统实时追踪 Nr 和参数版本 i,一旦发现请求违反陈旧度约束,即刻予以拒绝。这种机制确保了训练数据的新鲜度,避免了因数据过时而导致的性能下降。
解耦的 PPO 目标函数
为适应异步 RL 训练环境,AREAL 对传统的 PPO 算法进行了创新性的改进,提出了解耦的 PPO 目标函数。在标准 PPO 中,所有采样数据必须来源于单一的行为策略 πold,模型更新围绕此单一策略展开。而 AREAL 大胆地将行为策略 πbehav 和近端策略 πprox 分离。行为策略负责生成训练数据,而近端策略则作为模型更新的参照标杆。通过重要性采样,解耦后的 PPO 目标函数能够有效地利用不同策略版本生成的数据,使模型更新始终在近端策略构筑的信赖区域内稳步迈进。
解耦的 PPO 目标函数通过引入近端策略 πprox,将原始 PPO 的优化目标分解为两个部分:一部分是基于行为策略 πbehav 的重要性采样,另一部分是基于近端策略 πprox 的信任区域约束。这种分解不仅提高了模型更新的稳定性,还允许在异步环境中有效地利用陈旧数据。数学上,解耦后的 PPO 目标函数可以表示为:

其中,πprox 表示近端策略,用于计算重要性采样比率;πbehav 是行为策略,用于生成训练数据。这种设计使得 AREAL 能够在异步环境中,即使数据存在一定陈旧性,也能保持训练的稳定性和有效性。
算法优势与实验验证
解耦的 PPO 目标函数在处理异步数据时展现出了显著的优势。实验对比表明,在不同陈旧度情况下,解耦 PPO 能够维持训练的稳定性,并显著提升模型的最终性能。例如,在数学推理任务中,当数据陈旧度 η 设置为 4 时,模型的最终准确率仅比零陈旧度 oracle 模型低 1%,但训练速度却提升了 2 倍以上。这表明解耦 PPO 目标函数能够在保证模型性能的同时,大幅提高训练效率。此外,通过消融实验进一步验证了解耦 PPO 目标函数和陈旧度控制的有效性。开启解耦 PPO 后,训练曲线更加平稳,最终性能显著提升;适当设置最大允许陈旧度 η 值,在 η=4 时,模型在多个数学推理基准测试中性能近乎与零陈旧度 oracle 相当,却换来成倍训练加速。这些实验结果有力地支持了解耦 PPO 与陈旧度控制对于异步训练的关键价值。
下表对比了不同数据陈旧度下的评估分数,展示了有无解耦目标函数的影响。
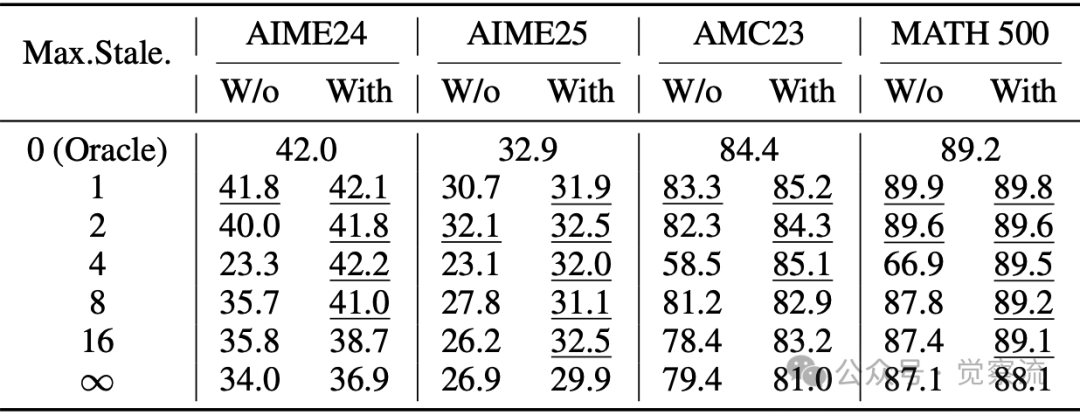
在数据陈旧性变化时的评估分数,比较了有无解耦目标时的性能表现。与最佳分数相差在±1以内的数值已用下划线标出
AREAL 与其他现有异步 RL 系统的对比
系统架构维度,AREAL 的完全解耦生成与训练架构,赋予其硬件资源利用与扩展性的卓越基因。对比之下,其他系统模块间紧密耦合,难以解锁硬件性能全部潜能。
算法原理上,解耦的 PPO 目标函数是 AREAL 的杀手锏。它在异步数据处理及陈旧性应对方面技高一筹,相较于其他系统算法,AREAL 的模型更新更精准、高效,如同在复杂路况中仍能保持稳定高速的赛车,轻松跨越数据陈旧性障碍,持续输出优异性能。
数据处理方式对比,AREAL 的高效性与灵活性让人印象深刻。它创新的数据管理策略,面对异步训练挑战,总能游刃有余。而其他系统在数据收集、筛选等环节,要么动作迟缓,要么僵化死板,难以适配瞬息万变的训练需求。
性能表现层面,实验数据显示训练速度、准确率、可扩展性指标上,AREAL 凭借线性扩展趋势、卓越长序列生成训练表现,遥遥领先同步系统与竞品异步系统。当其他系统在 GPU 数量增加时遇到瓶颈,而 AREAL 的训练吞吐量节节攀升,尤其在长序列生成训练场景中,线性扩展优势尤为明显。
下图展示了 AREAL 与其他系统的强扩展趋势对比,凸显 AREAL 的线性扩展优势。
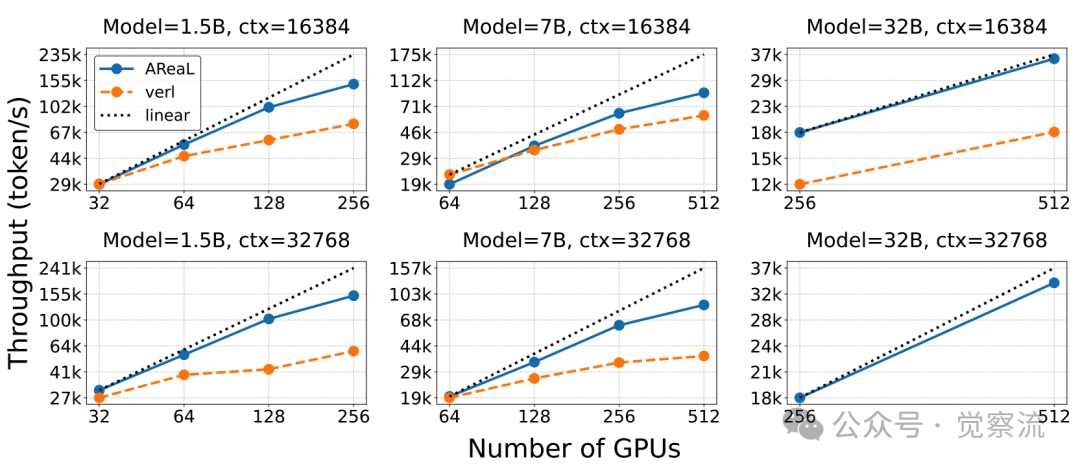
虚线表示理想的线性扩展。Verl在32k上下文长度和32B模型下持续遇到内存不足(OOM)问题,因此缺少数据点
AREAL 的实验评估
AREAL 的实验评估较为全面且深入,目的是全方位验证系统的性能和优势。实验设置严谨,选用的模型涵盖从 1.5B 到 32B 参数规模,任务类型包括数学推理与代码生成,基准测试选取 AIME24、LiveCodeBench 等权威标准,训练步骤和评估协议规范且详细,计算资源为 64 节点、每节点 8 GPU 的 H800 GPU 集群,为实验提供了坚实的硬件基础。实验所采用的训练配置和超参数如下表所示:
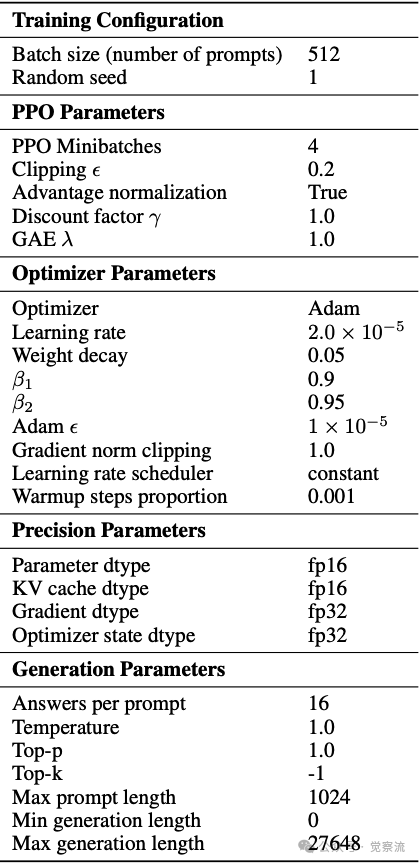
训练配置和超参数
端到端比较
端到端比较环节,AREAL 的表现令人瞩目。在数学推理任务中,以 1.5B 模型为例,与同步系统相比,AREAL 的训练吞吐量提升高达 2.57 倍。模型在 AIME24 基准测试中的准确率从同步系统的 42.0% 提升至 42.2%,训练时长从 41.0 小时大幅缩短至 14.8 小时。对于 7B 模型,准确率从 63.0% 略升至 63.1%,训练时长则从 57.7 小时缩减至 25.4 小时。在代码生成任务中,14B 模型在 LiveCodeBench 基准测试中的准确率从同步系统的 56.7% 提升至 58.1%,训练时长从 48.8 小时降至 21.9 小时。32B 模型同样展现出显著的性能提升。这些详实的数据充分展示了 AREAL 在提高训练效率和模型性能方面的卓越能力。
下表展示了端到端性能比较,包括数学和代码任务的准确率和训练时间。
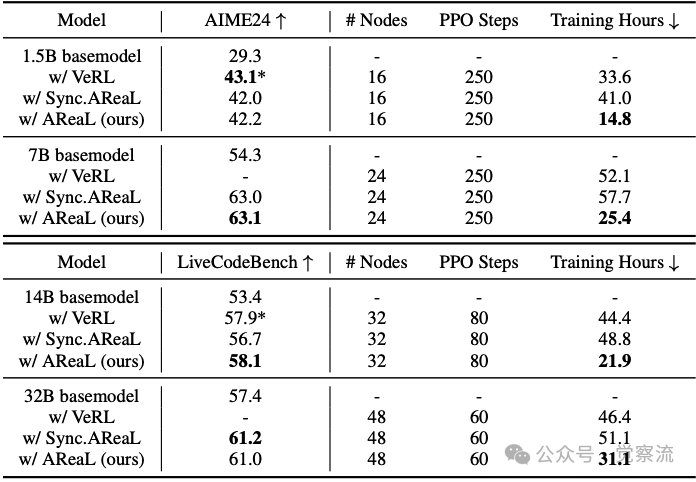
端到端性能对比。在AIME24数学基准测试和LiveCodeBench(2024年8月1日至2025年2月1日)编程基准测试上进行评估。将最大生成长度限制为32K token,并针对每个问题采样32个回答,报告平均通过率@1的准确率。*表示通过强化学习获得的最佳已知可复现结果,分别引用自DeepScaler 和DeepCoder。AReaL在训练时间少2倍的情况下,实现了相当的性能表现
可扩展性测试
可扩展性测试中,AREAL 随着 GPU 数量的增加,训练吞吐量展现出近乎理想的线性增长趋势。以 1.5B 模型、16k 上下文长度为例,对比 verl 系统,AREAL 在 32 GPU 时的吞吐量达到 29k token/s,是 verl 的 1.5 倍;在 64 GPU 时,吞吐量更是高达 41k token/s,远超 verl。而 verl 在 GPU 数量增加时吞吐量增速缓慢,AREAL 的线性扩展优势十分明显。尤其在长序列生成训练场景中,这种优势更为突出,这得益于 AREAL 完全解耦生成和训练过程的设计,使其能够高效地利用更多的 GPU 资源。
算法消融研究
算法消融研究进一步验证了 AREAL 算法创新的有效性。实验对比了开启和关闭解耦 PPO 目标函数以及不同最大允许陈旧度 η 值下的训练结果。结果显示,开启解耦 PPO 目标函数后,训练曲线更加平稳,最终性能显著提升。在适当设置 η 值的情况下,例如 η=4 时,模型在多个数学推理基准测试中的性能近乎与零陈旧度 oracle 相当,但训练速度却提升了 2 倍以上。这有力地证明了解耦 PPO 目标函数和陈旧度控制对于异步训练的关键价值,表明这两种机制能够有效地应对异步环境中的数据陈旧性问题,加速训练过程的同时保持模型性能的稳定。
实验挑战与解决方案
在实验过程中,AREAL 团队也遇到了一些挑战。例如,在数据收集和预处理阶段,如何确保数据的质量和多样性是一个难题。团队通过制定严格的数据清洗、标注和筛选流程,确保了数据集的可靠性和适用性。在模型训练过程中,超参数的调整也是一个关键问题。团队通过大量的实验和经验积累,确定了合适的学习率、折扣因子、批量大小等超参数,以优化模型的训练效果。此外,团队还开发了一系列工具和方法来监控和调试训练过程,以便及时发现和解决问题。
综上所述,AREAL 的实验评估验证了系统的高效性和优越性,同时也展示了其在实际应用中的可靠性和稳定性。通过端到端比较、可扩展性测试和算法消融研究等多个维度的实验,AREAL 证明了其在大规模强化学习训练中的强大能力和广阔应用前景。
AREAL 的开源与应用
AREAL 的开源举措是要点赞的,其开放性体现在多个维度。项目不仅公开训练细节、数据集和基础设施配置,还提供详尽的代码和配置示例,助力研究者与开发者快速上手。新手开发者可直接利用这些资源,从编写训练脚本到调整超参数,再到环境部署与多机多卡训练扩展。
开源仓库介绍
AREAL 的开源仓库(见参考资料)是开发者实践和探索的宝贵资源。仓库精心组织,包含以下核心模块:
- core:系统核心组件的实现代码,包括可中断的 Rollout Worker、奖励服务、Trainer Worker 和 rollout 控制器。
- algorithms:包含解耦的 PPO 算法及其他 RL 算法的实现。
- utils:提供系统运行所需的工具函数,如动态批处理、异步通信等。
- examples:提供多个示例脚本,展示如何使用 AREAL 进行不同任务的训练和评估。
仓库还提供详细的文档和教程,指导开发者快速入门。例如,通过以下命令即可在本地训练 Qwen3 1.7B 模型:
评估模型的命令如下:
这些脚本和命令为开发者提供了便捷的操作指南,使其能够迅速开展实验。
应用场景拓展
AREAL 的应用不仅限于数学推理和代码生成,还可拓展至逻辑谜题、科学问题解决等更多推理任务领域。以逻辑谜题为例,开发者可设计相应的奖励函数,将谜题解决步骤转化为可量化奖励信号,引导模型逐步探索解空间。同时,定制环境设置,模拟谜题操作界面,让模型实时交互试错。尽管任务数据稀缺性和模型结构适配性等挑战接踵而至,但 AREAL 凭借异步训练机制,灵活调整采样策略与模型架构,仍能输出令人满意的推理成果。
在科学问题解决任务中,AREAL 能高效处理复杂科学数据集。多元特征与长序列模型训练难题也被异步架构轻松化解。开发者可利用 AREAL 的异步训练机制,高效处理科学数据,提升模型在科学问题解决任务中的表现。
总结
当我读完 AREAL 相关论文材料,我对这款大型语言模型高效推理的强化学习系统,有了一定理解。AREAL 异步架构和创新算法为模型推理训练提供了全新思路。从架构系统来看,AREAL 通过将生成与训练完全解耦,让 Rollout Worker 和 Trainer Worker 能够独立运行,避免了同步系统中因等待长序列完成而导致的资源浪费。这种设计显著提高了 GPU 的利用率,使得训练过程更加高效。同时,系统各组件的协调工作,如可中断的Rollout Worker能够及时响应模型参数更新,奖励服务高效评估生成数据质量等,都为整个系统的高效运行提供了有力支撑。
在算法层面,AREAL 针对异步强化学习中的数据陈旧性问题提出了有效解决方案。通过限制策略版本差异和采用解耦的 PPO 目标函数,AREAL 使模型更新能够在高质量近端策略的信赖区域内进行,从而稳定训练过程。这一创新不仅巧妙化解了异步系统中数据陈旧性的难题,还体现了研究者对 RL 算法本质的深刻认识。系统优化措施也给我留下了深刻印象。动态批处理策略、可中断的 Rollout Worker等设计,处处体现出对计算资源的极致追求。
AREAL 的开源举措非常棒。它不仅公开了训练细节、数据集和基础设施配置,还提供了详尽的代码和配置示例,为研究者和开发者提供了宝贵的资源。这种开放共享的科研精神有助于加速整个行业的发展,让更多人有机会在这一领域进行探索和创新。
总体而言,AREAL 这个框架大型语言模型强化学习带来了显著进步。其异步训练架构、系统优化措施和算法改进等方面都展现出强大的优势。当然,AREAL 仍有很大的发展空间,如进一步优化推理和训练设备的比例、探索多轮交互和智能体场景的应用等。