
大家好,我是肆〇柒,大型语言模型(LLM)通过链式思考(CoT)进行深度推理,并借助大规模强化学习(RL)在复杂任务(如竞赛级数学问题解决)上取得了显著进展。OpenAI 的 o1、o3 等模型在数学推理任务上表现卓越,这些模型通常采用多层神经网络架构,通过大规模数据训练捕捉语言的复杂模式,从而实现高效的文本生成和推理。而 DeepSeek-R1-Zero 等模型在基础语言模型上直接应用大规模 RL 也展现了有趣的推理行为。然而,不同基础语言模型家族(如 Qwen 和 Llama)在 RL 后表现差异显著。这引发了研究者对如何提升 Llama 模型 RL 可扩展性的深入探索。
例如,Qwen 系列模型在 RL 训练后表现出色,而 Llama 等通用基础模型在复制 R1-Zero 风格训练成功方面却面临困难。这种现象引发了研究者对预训练与推理能力提升内在联系的深入思考。深入分析 Qwen 和 Llama 模型在架构、预训练目标等方面的差异,对于理解这些差异如何影响 RL 训练效果具有重要意义。这些差异可能导致模型在处理数学推理任务时的内在机制不同,进而影响 RL 训练中的表现。
由上海交大提出的这份研究《OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling》,目的就是为了深入探究预训练与推理能力提升的内在联系,为下一代 RL 友好型基础模型的设计提供关键指导。通过系统研究中期训练策略对 Llama 模型 RL 可扩展性的影响,研究者希望为大型语言模型在推理任务上的进一步发展提供理论支持和实践指导。这一研究不仅有助于缩小不同模型家族在 RL 训练后的性能差距,还可能推动整个领域对 RL 训练机制的理解,为未来模型的设计和优化提供新的思路。文末参考资料有OctoThinker模型家族的开源权重,以及 Github 开源代码仓库。

中期训练激励了Llama的强化学习扩展,使其性能与Qwen2.5相当
研究背景与动机
在数学推理任务上,OpenAI 的 o1、o3 等模型取得显著成功,这背后隐藏着哪些关键因素?
这些模型通常采用多层神经网络架构,通过大规模数据训练捕捉语言的复杂模式,从而实现高效的文本生成和推理。与 Qwen 和 Llama 模型相比,它们在预训练目标和优化策略上存在显著差异。Qwen 模型可能更注重特定领域的推理优化,而 Llama 模型则倾向于通用语言理解。这些差异可能导致模型在 RL 训练中对数据的适应性和泛化能力不同。
目前,在 Llama 等通用基础模型上复制 R1-Zero 风格训练成功面临诸多困难。现有研究在这一问题上的局限性主要体现在对预训练数据质量、模型架构适配性以及 RL 训练动态的深入理解不足。解决这一问题对于拓展大型语言模型的应用场景和提升其推理能力具有重要价值。通过优化中期训练策略,研究者希望能够显著提升 Llama 模型的 RL 可扩展性,使其在数学推理等复杂任务上表现出色。
Qwen 与 Llama 模型家族的 RL 动态差异
在 RL 训练中,Llama-3.2-3B-Base 和 Qwen2.5-3B-Base 展现出了截然不同的表现。
在训练中期可能影响训练后期阶段的潜在因素
从模型架构来看,Qwen 模型采用了更适应推理任务的神经网络结构,例如更深层次的注意力机制和更高效的参数优化策略,这使得它在处理数学推理任务时,能够更有效地捕捉问题的逻辑结构,并逐步构建解决方案。而 Llama 模型则更侧重于通用语言任务,这可能导致其在处理复杂推理链条时出现困难,从而影响输出内容的连贯性和合理性。
以数学问题求解为例,Qwen 模型在处理涉及多步逻辑推理的问题时,能够逐步推导出正确的解决方案,而 Llama 模型可能会在中间步骤中丢失关键信息,导致最终答案错误。这种差异可能源于 Qwen 模型在预训练阶段对数学推理任务的特殊优化,使其在 RL 训练中能够更好地适应和利用相关数据。
从下图可以直观地看到 Llama-3.2-3B 和 Qwen2.5-3B 在 RL 训练过程中的表现差异。Llama 模型的平均回答长度异常增加,而 Qwen 模型的长度则合理增长。这表明 Qwen 模型在推理过程中能够更好地控制输出长度,保持答案的连贯性和合理性。
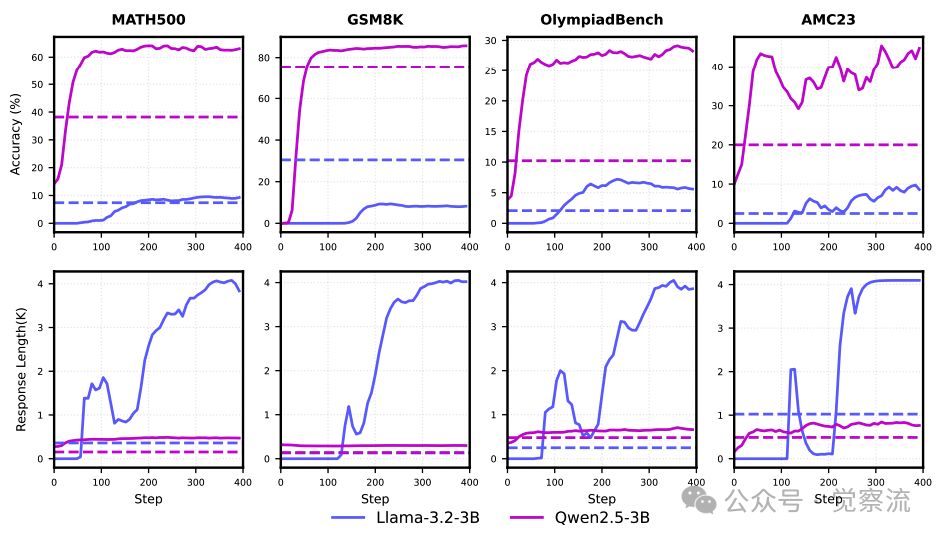
Llama-3.2-3B 和 Qwen2.5-3B 的训练动态对比,包括下游任务性能和正确回答的平均长度
中期训练的关键因素深度探索
💡 什么是中期训练?
中期训练是一种介于预训练和微调之间的训练阶段,其计算和数据(token)需求介于两者之间。它旨在通过显著改变数据质量和分布(和/或修改模型架构以提高推理效率)来实现特定目标,例如领域和语言扩展、长文本上下文扩展、提升数据质量、利用大规模合成数据以及为微调做准备等。
数学语料库的数据质量
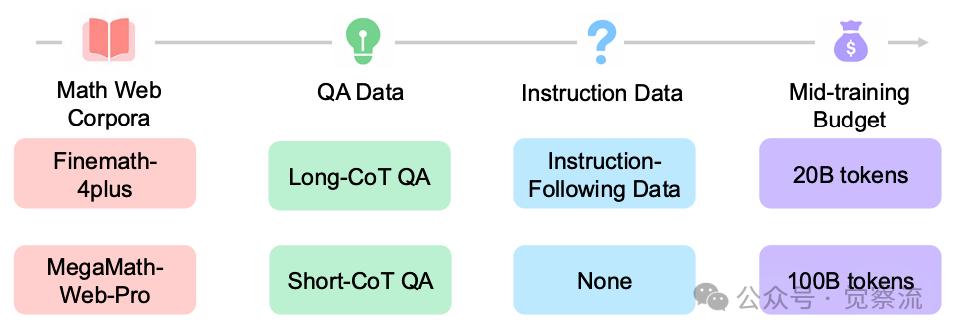
在中期训练中,使用高质量的数学语料库是提升模型性能的关键。MegaMath-Web-Pro 等优质语料库在数据分布和内容深度上明显优于 FineMath-4plus。
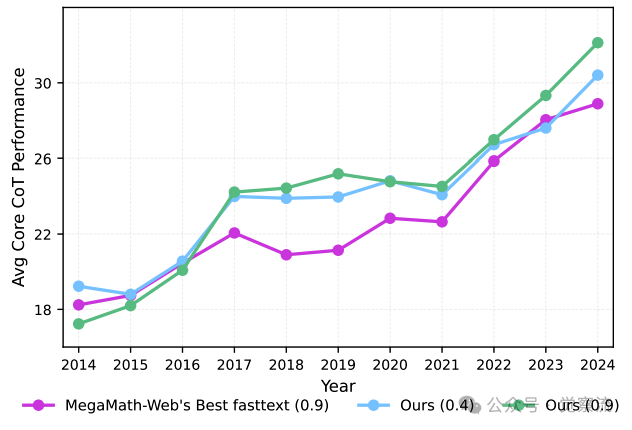
在50亿token的预训练预算下,按照其年度数据更新对比设置,对快速文本召回语料库(未经过大语言模型优化)与MegaMath-Web进行了对比,并展示了相应的召回阈值
为了确保数据质量,研究者对语料库进行了严格的筛选,包括数据的相关性、准确性和逻辑性评估。预处理步骤涉及数据清洗、格式统一等操作,以确保数据的一致性和可用性。
例如,在对 MegaMath-Web-Pro 进行预处理时,研究者首先对数据进行了清洗,去除了重复和低质量的内容。然后对文本进行了格式化处理,确保每条数据都包含清晰的问题描述和解答过程。这种严格的数据预处理流程为模型训练提供了坚实的基础。具体来说,MegaMath-Web-Pro 语料库中的问题描述详细且准确,解答过程逻辑清晰,有助于模型学习到有效的推理模式。而 FineMath-4plus 语料库中的内容可能存在较多噪声和不完整的推理步骤,导致模型在学习过程中难以形成有效的推理能力。
下图展示了不同数学网络语料库在中期训练中的效果。可以看出,MegaMath-Web-Pro 和 MegaMath-Web-Pro-Max 在提升模型性能方面表现优于 FineMath-4plus,这进一步证明了高质量语料库的重要性。
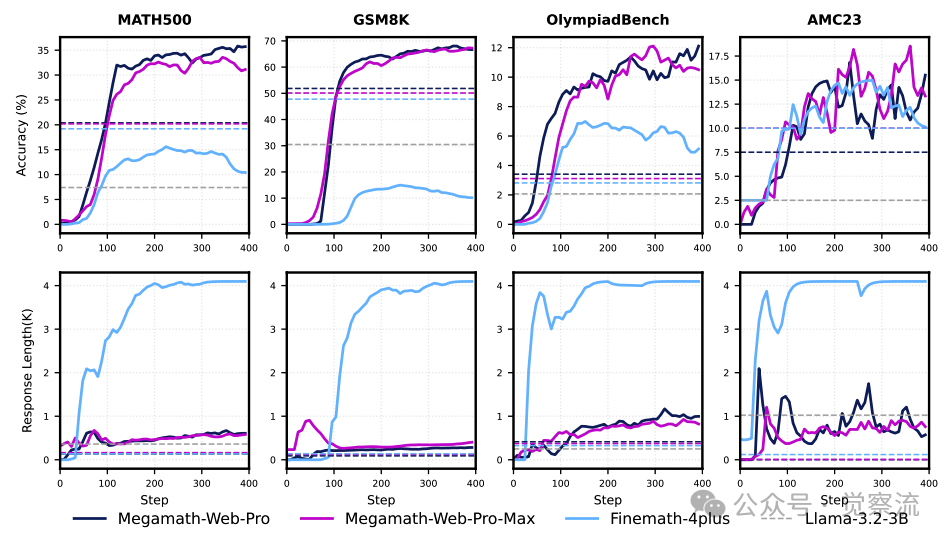
不同数学网络语料库在中期训练中的效果
QA 格式数据的引入与优化
在中期训练中引入不同类型的 QA 数据(如长链式思考、短链式思考示例)能够有效提升模型的推理能力。长 CoT 数据虽然能够增强模型的推理深度,但可能导致模型输出过于冗长,影响 RL 训练的稳定性。短 CoT 数据则有助于提升模型的简洁性和连贯性。通过合理混配长 CoT 和短 CoT 数据,并结合指令数据,可以平衡模型的回答质量和 RL 训练的稳定性。
在实际操作中,研究者选择了多种 QA 数据集,如 MegaMath-QA 和 Open-R1-Math-220K,并根据数据的特点和任务需求进行了合理的比例分配。例如,在处理长 CoT 数据时,通过设置最大响应长度和优化 RL 提示模板,有效避免了模型输出的冗长问题。具体来说,长 CoT 数据中包含多步推理过程,模型在学习这些数据时能够掌握更复杂的推理逻辑。但为了防止模型在生成答案时过于冗长,研究者设置了最大响应长度限制,并优化了 RL 提示模板,引导模型在保持推理深度的同时,生成简洁明了的答案。
下图展示了引入不同特性的 CoT 数据对中期训练基础模型性能的影响。可以看出,长 CoT 数据在提升推理深度方面表现出色,但也可能导致模型输出冗长。而短 CoT 数据则有助于提升模型的简洁性和连贯性。
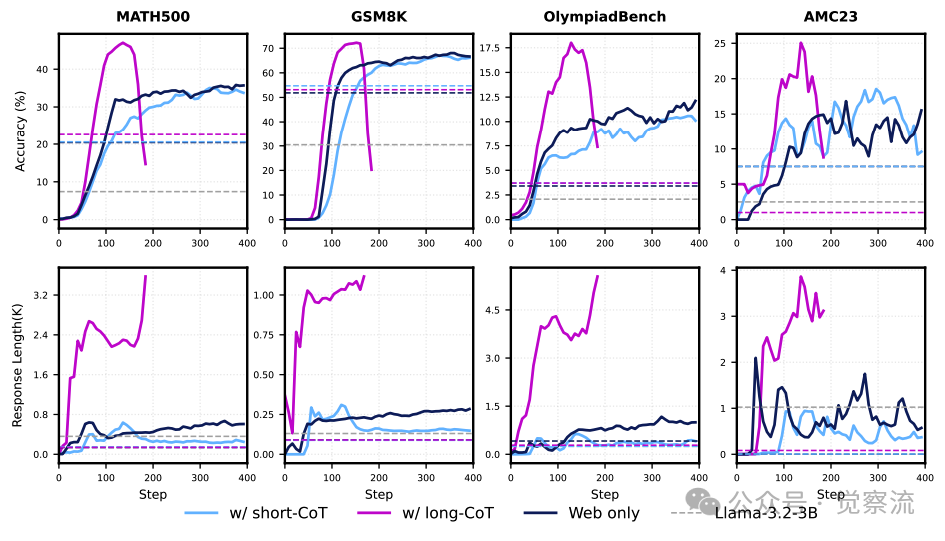
引入不同特性的 CoT 数据对中期训练基础模型性能的影响
指令跟随数据的深度挖掘
指令跟随数据的筛选和处理对于提升模型的指令遵循能力至关重要。研究者从多个高质量数据集中选取指令跟随数据,包括 TULU3-sft-personas-instruction-following、WildChat 和 UltraChat-200K 等。通过对数据来源和质量评估标准的严格把控,确保指令数据的可靠性和有效性。在不同训练阶段和模型尺寸下,指令跟随数据的效果差异显著。通过合理混配不同类型数据,可以优化模型性能,使其在处理复杂指令时表现出色。
在数据筛选过程中,研究者采用了多层次的评估标准,确保选取的数据不仅内容优质,且与数学推理任务高度相关。例如,通过人工标注和自动化评估相结合的方式,对数据的准确性和适用性进行了全面评估。具体而言,指令跟随数据中的指令需要清晰、明确,且与数学推理任务紧密相关。通过这种方式筛选出的数据能够帮助模型更好地理解用户指令,并在生成答案时遵循这些指令,从而提高模型在数学推理任务中的表现。
以下两图分别展示了在中期训练中引入指令跟随数据对短 CoT 和长 CoT 混合数据效果的影响。可以看出,指令跟随数据能够显著提升模型的性能,尤其是在处理复杂指令时表现出色。
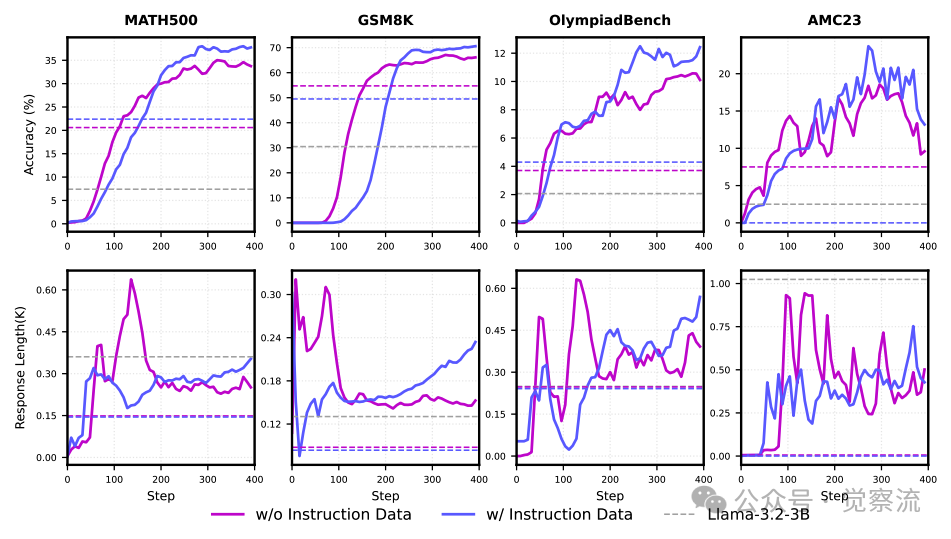
引入指令跟随数据对短 CoT 混合数据效果的影响
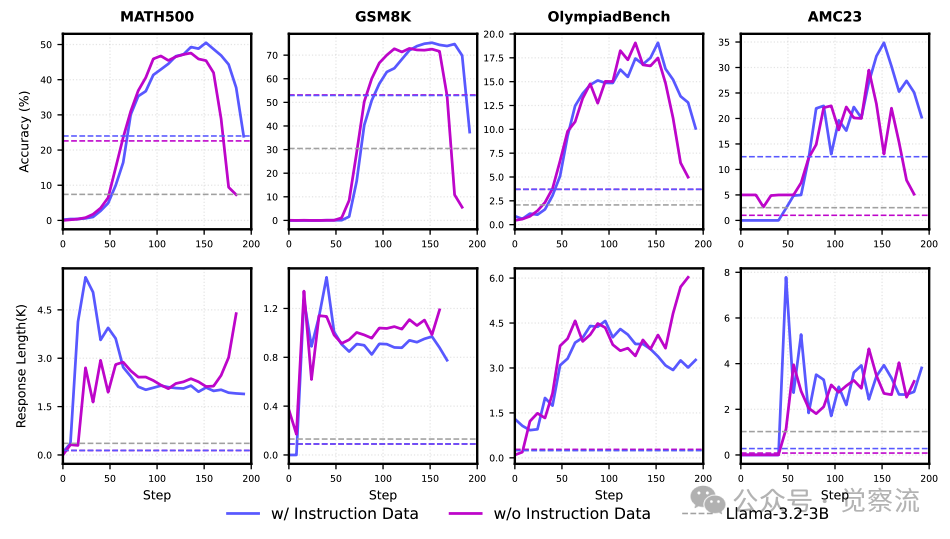
引入指令跟随数据对长 CoT 混合数据效果的影响
中期训练预算的扩展与优化
扩大中期训练token预算(如从 20B 到 70B、100B tokens)能够显著提升模型性能。在实验中,研究者详细描述了训练步骤,包括数据的加载方式、训练批次的划分和模型的更新频率等。硬件资源配置方面,采用了高性能计算设备,确保训练过程的高效性和稳定性。通过优化训练流程,合理分配训练预算,能够在有限的资源条件下实现最佳的训练效果,显著提升模型的推理能力和 RL 训练效果。
下图展示了扩大中期训练预算对 RL 性能的影响。可以看出,随着训练预算的增加,模型性能持续提升,证明了扩展训练预算的重要性。
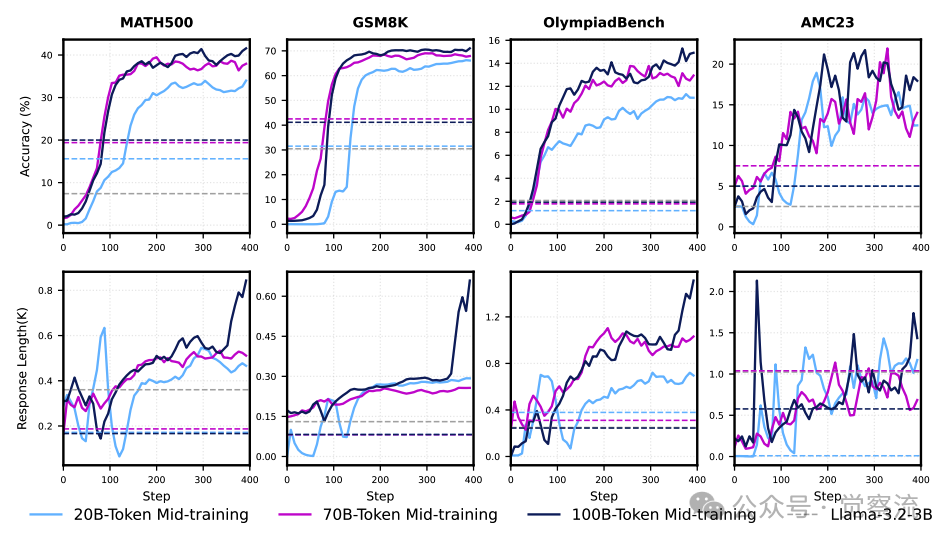
扩大中期训练预算对 RL 性能的影响
OctoThinker 模型家族的提出与构建
两阶段中期训练策略(Stable-then-Decay)的深度解读
OctoThinker 模型家族基于两阶段中期训练策略(Stable-then-Decay)构建。稳定阶段的目标是通过高质量的预训练语料库(如 MegaMath-Web-Pro-Max)提升模型的基础推理能力。采用恒定学习率训练 200B tokens,确保模型在大规模数据上逐步提升性能。衰减阶段则通过调整学习率和引入不同的数据分支(如短 CoT、长 CoT 和混合分支),使模型在特定推理模式上表现出色。这种策略的优势在于既能提升模型的通用推理能力,又能通过数据分支优化实现模型行为的多样化。
在稳定阶段,初始学习率的确定基于对模型参数规模和数据复杂度的综合评估。例如,对于 3B 模型,初始学习率设置为 2e-5,并根据训练过程中的损失变化进行微调。在衰减阶段,学习率按照余弦衰减公式逐渐降低,确保模型在训练后期能够精细调整参数,避免过拟合。
下图展示了 Llama-3.2-3B-Base、OctoThinker 系列和 Qwen2.5-Base 在 RL 训练中的对比。可以看出,OctoThinker 模型通过两阶段中期训练策略,显著提升了性能,与 Qwen2.5 模型的性能差距大幅缩小。
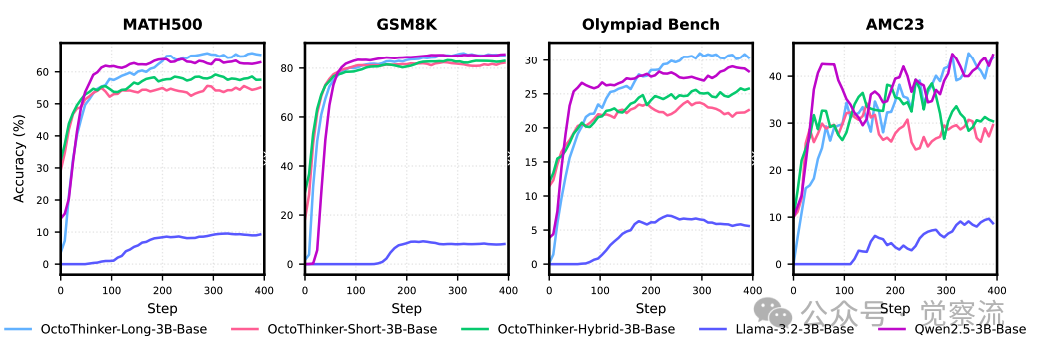
Llama-3.2-3B-Base、OctoThinker 系列和 Qwen2.5-Base 在 RL 训练中的对比
OctoThinker 模型的具体构建与优化
OctoThinker 模型家族的构建过程涉及多个关键步骤。模型架构的选择基于对不同架构在推理任务上的性能评估,最终确定了适合数学推理的神经网络结构。训练超参数的优化通过大量的实验验证,确保模型在不同训练阶段都能达到最佳性能。数据集的详细构成和权重分配根据数据的质量和相关性进行调整,以最大化模型的训练效果。
在不同模型尺寸(如 1B、3B)上实现该训练方案时,研究者根据模型的性能表现和训练需求进行动态调整。例如,对于较小的模型,可能需要更精细的超参数调整和更严格的数据筛选。训练过程中的监控指标(如准确率、损失值)和评估方法(如在验证集上的性能测试)确保了模型训练的稳定性和有效性。通过这些措施,OctoThinker 模型在数学推理任务上表现出色,显著提升了 Llama 模型的 RL 可扩展性。
以下三张表分别展示了第一阶段的数据构成和权重分配、稳定阶段的超参数设置以及衰减阶段的超参数设置。这些表格详细描述了模型训练过程中的关键参数和数据配置,为读者提供了清晰的训练方案。

第一阶段的数据构成和权重分配
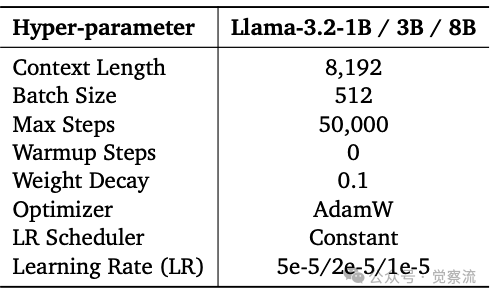
稳定阶段的超参数设置
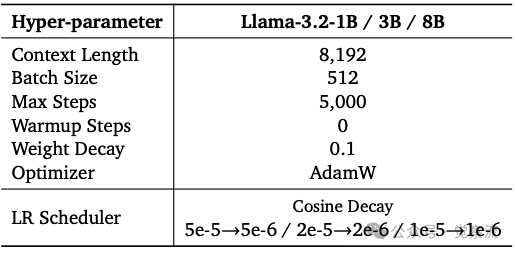
衰减阶段的超参数设置
OctoThinker 模型的评估与分析
不同分支模型在数学推理基准测试上的精细表现
OctoThinker-Base 系列(包括 Stable、Long、Hybrid、Short 分支)在 13 个数学推理基准测试(如 GSM8K、MATH500、Olympiad Bench、AMC23 等)上的评估结果显示,各分支模型在不同任务上的性能差异显著。例如,Long 分支在处理复杂数学问题时表现出更强的推理能力,而 Short 分支则在简单问题上具有更高的效率。与原始 Llama 基础模型相比,OctoThinker 模型在所有基准测试中均表现出显著的性能提升。稳定阶段中期训练后的模型进一步优化了性能,证明了两阶段中期训练策略的有效性。
以下两图分别展示了 OctoThinker-1B 系列和 OctoThinker-3B 系列不同分支在 RL 训练中的动态表现。可以看出,各分支模型在不同任务上的优势和不足。Long 分支在处理需要多步骤推理的问题时具有明显优势,而 Short 分支则更适合单步或少步推理任务。Hybrid 分支结合了长 CoT 和短 CoT 数据的优点,在多种任务上表现出平衡的性能。
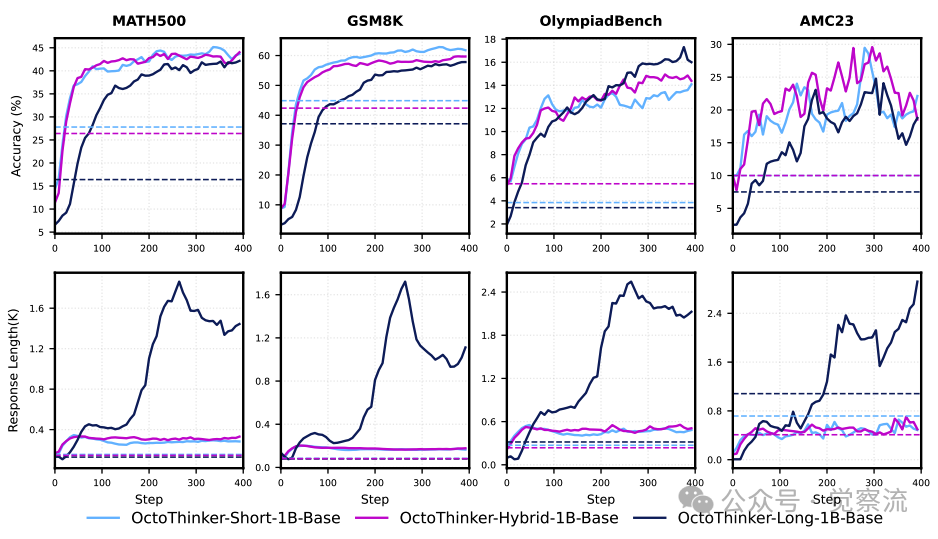
OctoThinker-1B 系列不同分支在 RL 训练中的动态表现
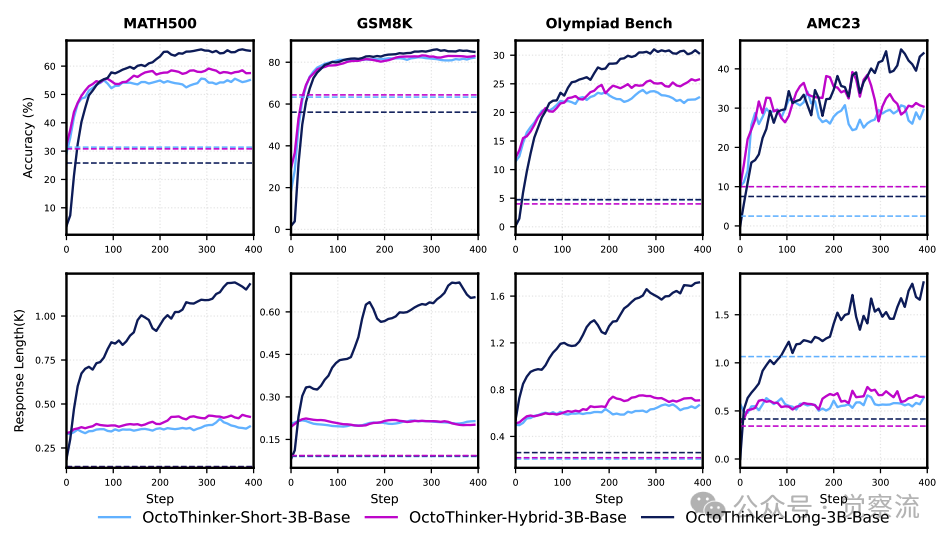
OctoThinker-3B 系列不同分支在 RL 训练中的动态表现
RL 训练后的 OctoThinker-Zero 模型家族的深入剖析
对 OctoThinker 基础模型进行强化学习训练后得到的 OctoThinker-Zero 模型家族在数学推理任务上表现出卓越性能。不同分支模型(如 OctoThinker-Short-Zero、OctoThinker-Long-Zero、OctoThinker-Hybrid-Zero)在 RL 训练过程中的动态变化显著。Long 分支在训练后期逐渐展现出更强的推理能力,而 Short 分支则在早期阶段表现出较高的效率。各分支模型在不同应用场景下的适用性和优势不同,例如 Long 分支适合处理复杂的数学竞赛问题,而 Short 分支则更适合快速解答简单问题。
结合模型的架构和训练数据特点,可以深入理解各分支模型的表现模式。Long 分支通过长 CoT 数据训练,能够处理复杂的推理链条, suitable for tasks requiring multi-step reasoning。Short 分支则通过短 CoT 数据优化,提升了单步推理的效率和准确性。Hybrid 分支通过结合长 CoT 和短 CoT 数据,实现了在多种任务上的平衡性能。这些特点使 OctoThinker-Zero 模型家族能够适应不同的数学推理需求。
与 Qwen2.5 模型的深度对比分析
对比 OctoThinker 模型(特别是 Long 分支)与 Qwen2.5 模型在 RL 训练过程中的性能表现,可以发现两者在模型架构、预训练目标和训练数据等方面存在显著差异。Qwen2.5 模型在数学推理任务上表现出色,得益于其专门针对数学推理优化的预训练目标和数据选择。OctoThinker 模型通过两阶段中期训练策略,在稳定阶段提升基础推理能力,在衰减阶段通过数据分支优化实现模型行为的多样化。通过具体数据和图表展示,OctoThinker 模型成功缩小了与 Qwen2.5 模型的性能差距,在某些任务上甚至表现出相近的性能水平。这验证了中期训练策略的有效性,证明了 OctoThinker 模型在提升 Llama 模型 RL 可扩展性方面的潜力。
下图进一步展示了 OctoThinker 模型与 Qwen2.5 模型在 RL 训练中的对比。可以看出,OctoThinker-Long 分支在多个基准测试中的性能接近 Qwen2.5 模型,证明了中期训练策略的有效性。
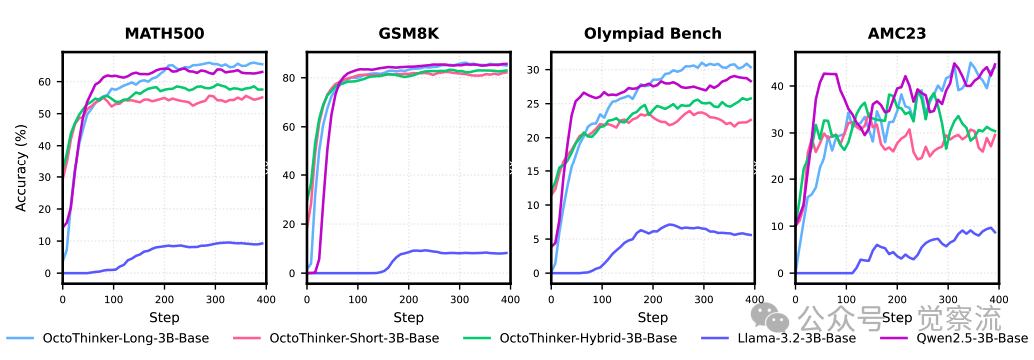
OctoThinker 模型与 Qwen2.5 模型在 RL 训练中的对比
总结
通过系统探索中期训练策略,OctoThinker 成功提升了 Llama 模型的强化学习(RL)可扩展性,揭示了高质量、推理密集型语料库(如 MegaMath-Web-Pro)对模型性能提升的关键作用。两阶段中期训练策略(Stable-then-Decay)有效增强了 Llama 模型的推理能力,使其在数学推理任务上表现出色。OctoThinker 模型家族在多个数学推理基准测试中展现了卓越的性能,显著缩小了与 Qwen2.5 等 RL 友好型模型家族的性能差距。
从模型性能、训练效率和可扩展性等多个维度综合评估,OctoThinker 模型凭借高质量数据、合理训练策略和精心模型优化的深度融合,展现了显著的优势和价值。这一研究成果不仅为 Llama 模型的持续发展指明了新的方向,更为大型语言模型在推理任务上的整体进步展示了坚实的理论与实践基础。
基于当前的成果与局限性,有几个关键探索方向值得深入挖掘:
1. 数学语料库的持续优化:改进数据收集、筛选和预处理流程,进一步提升语料库质量与多样性。例如,拓展领域特定的数学数据来源,或开发更高效的自动筛选工具,确保语料库覆盖更广泛的数学知识点和推理模式。
2. RL 友好型基础模型的设计:探索无需从强大长 CoT 推理模型蒸馏的 RL 友好型基础模型设计方法,可能涉及改进模型架构(如引入更高效的注意力机制)或优化训练目标(如设计更适合推理任务的损失函数)。
3. QA 格式与内容的独立贡献研究:通过针对性实验设计,深入剖析 QA 数据格式和内容对模型性能的独立影响,以更精准地优化数据选择和训练策略,进一步提升模型推理能力。
4. OctoThinker 家族功能与应用场景的拓展:探索引入工具集成、多模态推理等功能,使 OctoThinker 模型适应更多应用场景。例如,结合图表理解能力,提升模型在可视化数学问题上的推理表现。
这些探索方向将为大型语言模型在推理任务上的进一步发展注入新的活力,提供创新的思路与方法。至此,如果大家对OctoThinker有兴趣,可以从参考资料处查看它的模型家族权重,以及Github开源仓库。


