这个研究提出了一种新型强化学习(RL)框架SEARCH-R1,该框架使大型语言模型(LLM)能够实现多轮、交错的搜索与推理能力集成。不同于传统的检索增强生成(RAG)或工具使用方法,SEARCH-R1通过强化学习训练LLM自主生成查询语句,并优化其基于搜索引擎结果的推理过程。
该模型的核心创新在于完全依靠强化学习机制(无需人工标注的交互轨迹)来学习最优的搜索查询策略及基于检索知识的推理方法,从而显著提升问答任务的性能表现。
现有挑战:
大型语言模型在实际应用中面临两个主要技术瓶颈:
- 复杂推理能力受限: 即便采用思维链(Chain-of-Thought)提示技术,LLM在执行多步推理任务时仍存在明显障碍。
- 外部知识获取不足: 仅依赖参数化存储的知识,模型难以获取最新信息或特定领域的专业知识。
现有技术方案:
- 检索增强生成(RAG): 将检索文档与LLM提示结合,但面临检索精度不足及单轮交互限制等问题。
- 工具使用方法论: 引导LLM与搜索引擎等工具进行交互,但这类方法通常需要大量监督数据支持,且跨任务泛化能力较弱。
技术创新与贡献
SEARCH-R1框架核心设计:
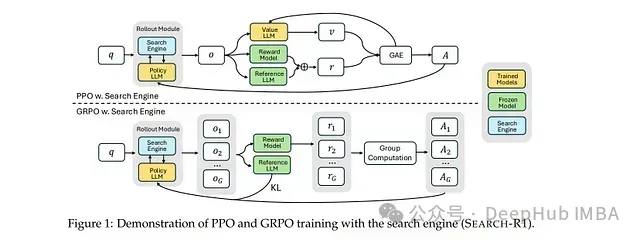
强化学习与搜索的深度融合: 本研究提出的框架将搜索引擎交互机制直接整合至LLM的推理流程中。模型不依赖预定义的监督轨迹,而是通过强化学习自主生成搜索查询并利用检索信息优化输出结果。
交错式多轮推理与检索机制: 该方法实现了自我推理(<think>标记包围的内容)、搜索查询(<search>标记包围的内容)及信息检索(<information>标记分隔的内容)的交错执行。这种迭代过程使模型能够根据累积的上下文信息动态调整推理路径。
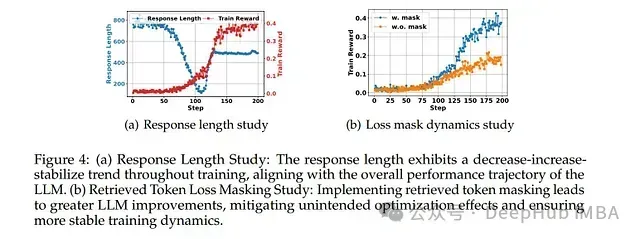
令牌级损失屏蔽技术: 研究中的一项关键技术创新是对从检索段落中直接获取的令牌实施损失屏蔽。这一机制有效防止模型基于非自生成内容进行优化,从而保证强化学习训练过程的稳定性和有效性。
结果导向型奖励函数设计: SEARCH-R1采用简洁的最终结果奖励机制(如答案的精确匹配度),而非复杂的过程性奖励,这不仅简化了训练流程,还降低了潜在的奖励利用(reward exploitation)问题。
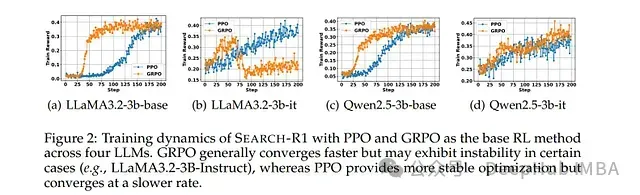
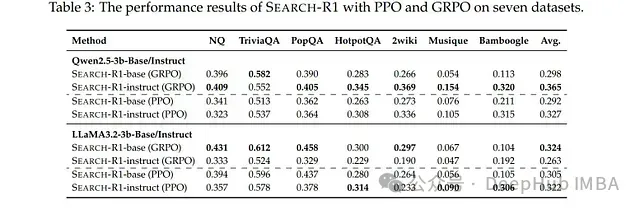
多种强化学习算法兼容性: 该框架通过近端策略优化(PPO)和群体相对策略优化(GRPO)进行了系统评估。实验表明,尽管GRPO在收敛速度方面表现优异,但PPO在不同LLM架构中普遍提供更稳定的性能表现。

方法学与技术实现细节
强化学习框架构建: 训练目标被明确设定为最大化预期结果奖励值,同时通过KL散度正则化项约束模型与参考策略间的偏离程度。该数学公式明确地将搜索检索过程纳入模型决策流程的一部分。
交错式Rollout执行机制: 模型生成文本直至遇到<search>标记触发查询操作。检索到的段落随后被插入回响应文本中,形成一个闭环过程,使模型能够基于外部知识持续精炼其推理结果。
结构化训练模板: 研究设计了专用输出模板,引导LLM首先进行内部推理,然后在必要时执行搜索,最终输出答案。这种结构化模板最大限度地减少了推理过程中的偏差,并确保了训练阶段的格式一致性。
实验评估与关键发现
实验数据集:该框架在七个问答类数据集上进行了全面评估,涵盖通用问答领域(如NQ、TriviaQA)及多跳推理任务(如HotpotQA、2WikiMultiHopQA)。
对比基线:
SEARCH-R1与以下技术方案进行了系统对比:
- 直接推理方法(有无思维链辅助)
- 检索增强技术(RAG、IRCoT、Search-o1)
- 微调策略(监督微调、不包含搜索引擎集成的RL)
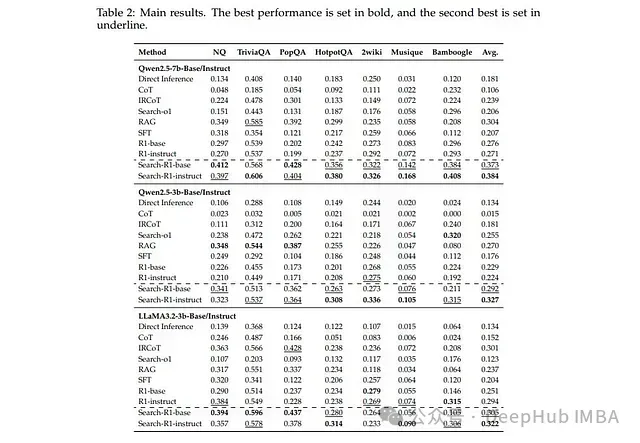
核心实验结果:
性能提升显著: SEARCH-R1实现了显著的相对性能提升——在Qwen2.5-7B上提升26%,Qwen2.5-3B上提升21%,LLaMA3.2-3B上提升10%——全面超越现有最先进基线。
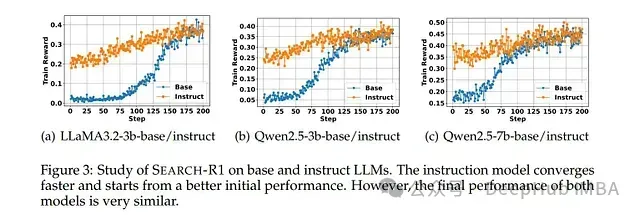
泛化能力突出: 该框架在基础模型和指令调整型模型上均表现出良好的有效性,证明了其广泛的技术适用性。
详细研究表明:交错式推理和搜索策略显著提高了响应质量和稳定性。检索令牌损失屏蔽机制对实现稳定且一致的性能提升至关重要。
研究中包含了多个说明性案例(如验证名人出生地等事实信息),其中SEARCH-R1明显优于不具备搜索能力的RL模型。迭代查询和自我验证过程凸显了实时检索集成的实际价值。
局限性与未来研究方向
奖励函数设计简化: 尽管基于结果的奖励函数证明了其有效性,但在更复杂任务场景中可能难以捕捉细微差异。研究团队指出,探索更精细化的奖励机制设计可能进一步提升系统性能。
搜索引擎黑盒处理: 当前模型将搜索引擎视为环境的固定组件,缺乏对检索质量的精细控制。未来研究可考虑设计更动态或上下文相关的检索策略优化机制。
多模态任务扩展: 虽然研究提出了将该方法扩展至多模态推理任务的潜在路径,但目前的实验仍主要聚焦于文本问答。向其他数据类型的扩展仍是一项开放性挑战。
总结
SEARCH-R1代表了构建能与外部信息源动态交互的大型语言模型的重要进展。通过将强化学习与搜索引擎交互有机结合,该模型不仅提高了事实准确性,还增强了多轮交互中的推理能力。
技术优势:
- 强化学习与基于搜索推理的创新性集成
- 在多样化数据集上验证的明显性能提升
- 对不同模型架构和规模的适应性与灵活性
现存不足:
- 奖励机制虽然设计简洁有效,但对于更复杂应用场景可能需要进一步优化
- 对预定义搜索接口的依赖可能限制了系统对多样化信息源的适应能力
SEARCH-R1通过展示LLM可通过强化学习自主管理外部知识获取,推动了检索增强生成技术的边界。这对需要最新信息支持和复杂推理能力的应用场景(从智能对话系统到专业领域问答)具有重要价值。


SEARCH-R1提供了一种极具潜力的技术路径,通过结合强化学习优势与实时搜索能力来克服大型语言模型的固有局限。其设计理念和实验结果为致力于构建知识更丰富、推理能力更强的人工智能系统的研究人员提供了宝贵的技术洞见。