自OpenAI发布o1以来,如何复现并改进o1就成为了LLM研究的焦点。
尽管以OpenAI-o1、Qwen-QwQ和DeepSeek-R1为代表的推理模型,其推理能力已然震惊四座,但由于在长链推理过程中仍然面临着「知识不足」的问题,导致这些模型在推理过程还包含着一些不确定性和潜在错误。
类似于OpenAI-o1在处理复杂问题时,每次推理过程中平均会遇到超过30个不确定术语实例,如「或许」和「可能」。这不仅增加了推理的复杂性,还使得手动验证推理过程更具挑战性。
因此,自动化补充推理过程中所需知识对于提升大型推理模型的可信度变得至关重要。
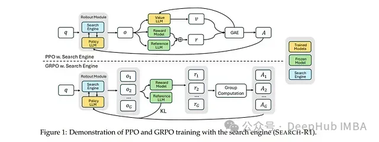
为了解决这一问题,人大高瓴携手清华团队提出了Search-o1框架。该框架通过集成自主检索增强生成(Agentic Retrieval-Augmented Generation)机制和文档内推理(Reason-in-Documents)模块,解决了大型推理模型(LRMs)固有的知识不足问题。
同时也使得LRMs能够在推理过程中自主检索并无缝整合外部知识,从而提升其长步骤推理能力的准确性和连贯性。在科学、数学、编程等多样复杂推理任务以及多个开放域问答基准上的全面实验表明,Search-o1 始终优于现有的检索增强和直接推理方法。
值得注意的是,Search-o1 不仅在处理复杂推理挑战上超越了基线模型,还在特定领域达到了与人类专家相当甚至超越的表现水平。
 图片
图片
论文链接:https://arxiv.org/abs/2501.05366
如下图所示,在对比推理过程中出现的不确定性词语的平均次数时,Search-o1明显比直接进行推理的模型要低,尤其是「alternatively」出现的次数甚至还不到后者的一半。
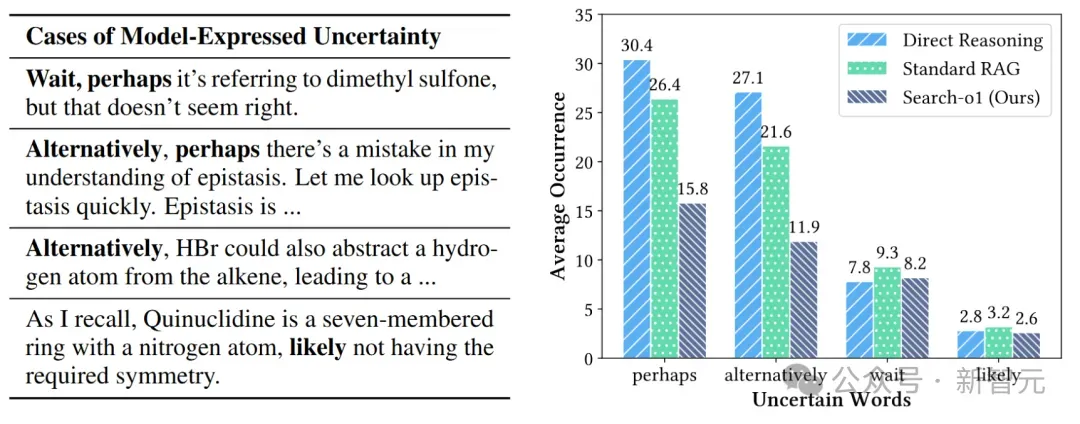 高频不确定词出现次数对比
高频不确定词出现次数对比
同时Search-o1也明显低于标准RAG。因为标准RAG仅以问题导向的方式检索一次相关知识,而在复杂推理场景中,每一步所需的知识往往是多样且多变的。
与它们不同,Search-o1采用了一种代理式RAG技术,指导模型在面对知识短缺时主动解码去搜索查询,从而触发检索机制以获取相关外部知识。得益于这一设计的优势,Search-o1的检索机制可以在一次推理会话中多次触发和迭代,以满足各种推理步骤的知识需求。
框架介绍
研究者将以下三种推理范式做了一个流程概述的对比:
- 原始推理模式:考虑下图(a)中的例子,其任务为确定三步化学反应最终产物中的碳原子数量。然而当遇到知识空白时,例如「反式肉桂醛的结构」,原始推理方法就会失效。因为在无法获取准确信息的情况下,模型必须依赖假设,这就可能导致后续推理步骤中产生连环错误。
- 代理式RAG:为了在推理过程中弥合知识差距,图(b)代理式RAG机制能够使模型在需要时自主检索外部知识。当出现不确定性时,例如关于化合物结构的问题,模型则会生成有针对性的搜索查询。然而,直接处理检索到的文档(这些文档通常包含冗长且不相关的信息)可能会打断推理流程并影响连贯性。
- Search-o1:Search-o1框架(图(c))通过整合一个「文档内推理」模块扩展了代理式RAG机制。该模块将检索到的文档内容浓缩为聚焦的推理步骤,这些步骤在保持推理链逻辑流畅的同时,融入了外部知识。它考虑当前搜索查询、检索到的文档以及现有的推理链,以生成连贯的步骤。这一迭代过程持续进行,直至得出最终答案。
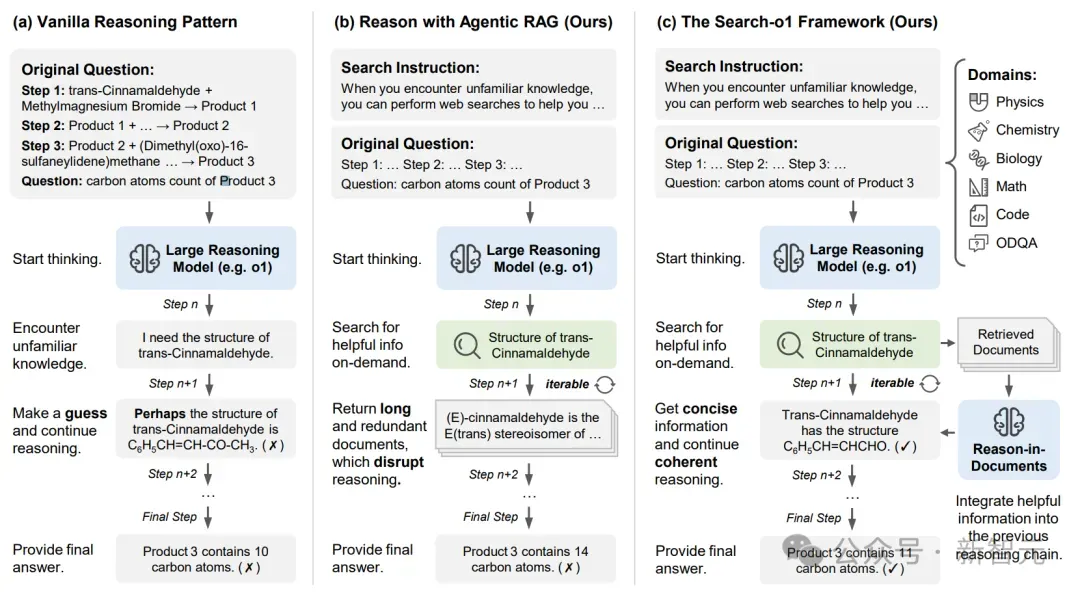 三种框架的概述对比
三种框架的概述对比
简要来讲,Search-o1推理首先将任务指令与具体问题相结合。当推理模型生成推理链时,可能会创建带有特殊符号标记的搜索查询。
检测到搜索查询后,接着会触发对相关外部文档的检索。这些文档随后由文档内推理模块处理,提取并精炼必要信息。
精炼后的知识被重新整合到推理链中,确保模型在保持连贯和逻辑流程的同时,融入关键的外部信息,最终实现全面的推理过程并得出最终答案。
研究者将推理模型的目标定义为生成每个问题q的全面解决方案,包括逻辑推理链ℛ和最终答案a,并使推理模型能够在推理过程中利用外部知识源。
 图片
图片
如上述算法流程图所示:对于每个问题,Search-o1推理首先通过将任务指令I与特定问题q连接来初始化推理序列。随着推理模型ℳ生成推理链ℛ,它可能会产生封装在特殊符号<|begin_search_query|>和<|end_search_query|>之间的搜索查询。
一旦检测到符号,相应的搜索查询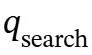 会被提取出来,触发检索函数Search以获取相关的外部文档𝒟。
会被提取出来,触发检索函数Search以获取相关的外部文档𝒟。
这些检索到的文档,连同文档内推理指令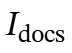 和当前的推理序列ℛ,随后由文档内推理模块处理。该模块将原始文档提炼为简洁、相关的信息
和当前的推理序列ℛ,随后由文档内推理模块处理。该模块将原始文档提炼为简洁、相关的信息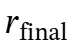 ,并无缝地将其整合回推理链ℛ中的符号和内。这一迭代过程确保了推理模型在保持连贯性和逻辑一致性的同时,融入必要的外部知识,从而生成全面的推理链 ℛ 和最终答案a。
,并无缝地将其整合回推理链ℛ中的符号和内。这一迭代过程确保了推理模型在保持连贯性和逻辑一致性的同时,融入必要的外部知识,从而生成全面的推理链 ℛ 和最终答案a。
具体而言,研究者在问题解决过程中考虑三个主要输入:任务指令I 、问题q和外部检索的文档𝒟。其中,I提供了推理任务的总体描述,q是要回答的具体复杂问题,𝒟包括从相关知识库动态检索的背景知识。
目标是设计一种推理机制,有效整合I、q和𝒟,以生成连贯的推理链ℛ和最终答案a。这可以形式化为映射(I,q,𝒟)→(ℛ,a)。推理序列和最终答案的生成可表示为:
 图片
图片
其中Tr是推理序列ℛ中的标记数量。位置t处的标记是ℛt,而ℛ<t表示在位置t之前生成的所有标记。𝒟≤t表示在推理链中直到标记t为止检索到的所有文档。同样地,Ta是答案序列a的长度,at是位置t处的标记,a<t表示在位置t之前生成的所有答案标记。
代理检索增强生成机制
代理式RAG机制是Search-o1框架的关键组成部分,它赋予推理模型在推理过程中自主决定何时检索外部知识的能力。该机制使得模型能够自行决定是继续生成推理步骤还是启动检索步骤。
在生成推理链ℛ的过程中,模型可能会在特殊符号<|begin_search_query|>与<|end_search_query|>之间,间歇性地生成搜索查询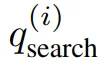 ,其中i索引第i个搜索步骤。每个搜索查询都是基于当前推理过程的状态和先前检索到的知识生成的。每个搜索查询的生成表示为:
,其中i索引第i个搜索步骤。每个搜索查询都是基于当前推理过程的状态和先前检索到的知识生成的。每个搜索查询的生成表示为:
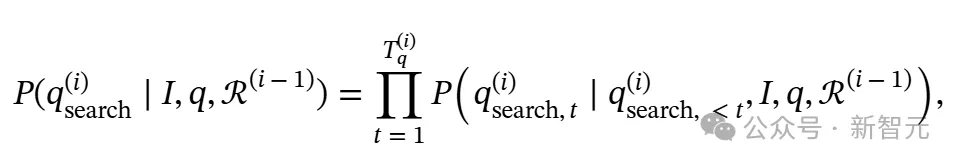
其中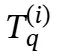 是第i个搜索查询的长度,
是第i个搜索查询的长度,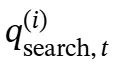 表示在第i个搜索查询的第t步生成的令牌,ℛ(i−1)表示在第i个搜索步骤之前的所有推理步骤,包括搜索查询和搜索结果。
表示在第i个搜索查询的第t步生成的令牌,ℛ(i−1)表示在第i个搜索步骤之前的所有推理步骤,包括搜索查询和搜索结果。
一旦在推理序列中检测到用于搜索查询的一对新特殊符号,就需要暂停推理过程,并提取搜索查询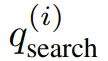 。调用检索函数 Search 以获取相关文档:
。调用检索函数 Search 以获取相关文档:
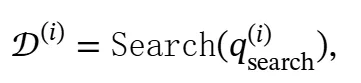
其中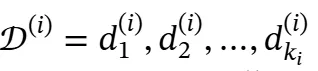 表示针对第i个搜索查询检索到的前ki个相关文档的集合。检索到的文档𝒟(i)随后被注入到特殊符号之间的推理链 ℛ(i−1) 中,使推理模型能够利用外部知识继续推理过程。
表示针对第i个搜索查询检索到的前ki个相关文档的集合。检索到的文档𝒟(i)随后被注入到特殊符号之间的推理链 ℛ(i−1) 中,使推理模型能够利用外部知识继续推理过程。
文档内推理实现知识精炼
尽管代理RAG机制解决了推理中的知识缺口,但直接插入完整文档可能会因其长度和冗余而破坏连贯性。
为此Search-o1框架包含了知识精炼模块,该模块通过使用原始推理模型的独立生成过程,选择性地将相关且简洁的信息整合到推理链中。
此模块处理检索到的文档,使其与模型的特定推理需求对齐,将原始信息精炼为仅相关的简洁知识,同时保持主推理链的连贯性和逻辑一致性。
对于每个搜索步骤i,令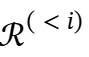 表示在第i次搜索查询之前积累的推理链。给定
表示在第i次搜索查询之前积累的推理链。给定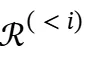 、当前搜索查询
、当前搜索查询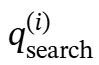 和检索到的文档
和检索到的文档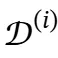 ,知识精炼过程分为两个阶段:首先生成中间推理序列
,知识精炼过程分为两个阶段:首先生成中间推理序列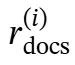 以分析检索到的文档,然后基于此分析生成精炼后的知识
以分析检索到的文档,然后基于此分析生成精炼后的知识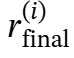 。中间推理序列
。中间推理序列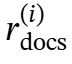 的生成表达为:
的生成表达为:
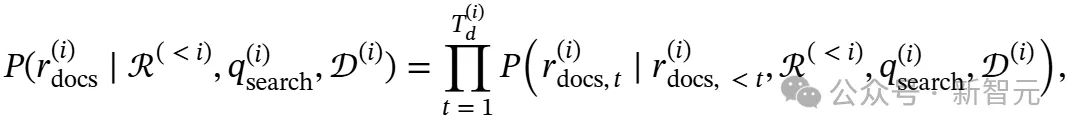
然后基于此分析生成精炼知识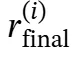 :
:
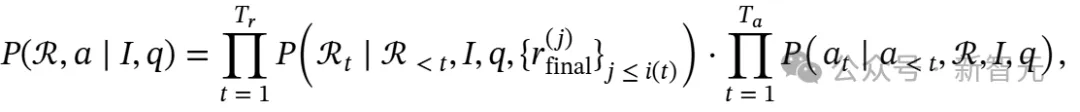
随后,精炼知识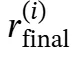 被整合到推理链ℛ(i)中,使模型能够继续生成连贯的推理步骤,并访问外部知识。
被整合到推理链ℛ(i)中,使模型能够继续生成连贯的推理步骤,并访问外部知识。
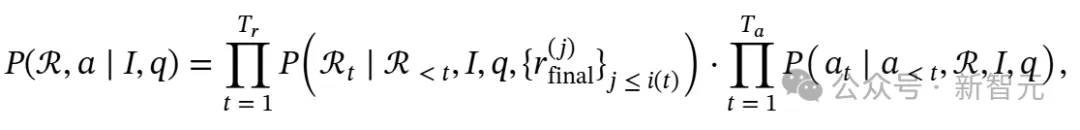
其中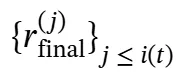 表示截至第i(t)搜索步骤之前所有已提炼的知识。这种精炼的知识整合确保了每个推理步骤都能访问相关的外部信息,同时保持推理过程的简洁性和专注性。
表示截至第i(t)搜索步骤之前所有已提炼的知识。这种精炼的知识整合确保了每个推理步骤都能访问相关的外部信息,同时保持推理过程的简洁性和专注性。
实验评估
Search-o1采用QwQ-32B-Preview作为backbone,进行基线实验。本实验的评估涵盖两类任务与数据集:高难度推理任务和开放领域问答任务。
高难度推理任务涉及以下三个数据集:
1. GPQA:这是一个博士级别的科学问答数据集,其中的问题均由领域专家编写,主要用于评估模型在复杂科学推理方面的表现。
2. 数学基准测试:旨在考察模型在不同难度数学推理任务中的能力表现。
3. LiveCodeBench:该数据集用于评估LLM的编码能力。
开放领域问答任务可分为单跳问答和多跳问答两类。单跳问答主要考查模型对单一信息源的理解能力。多跳问答目的是评估模型在跨段落、多信息源进行推理时的综合能力。
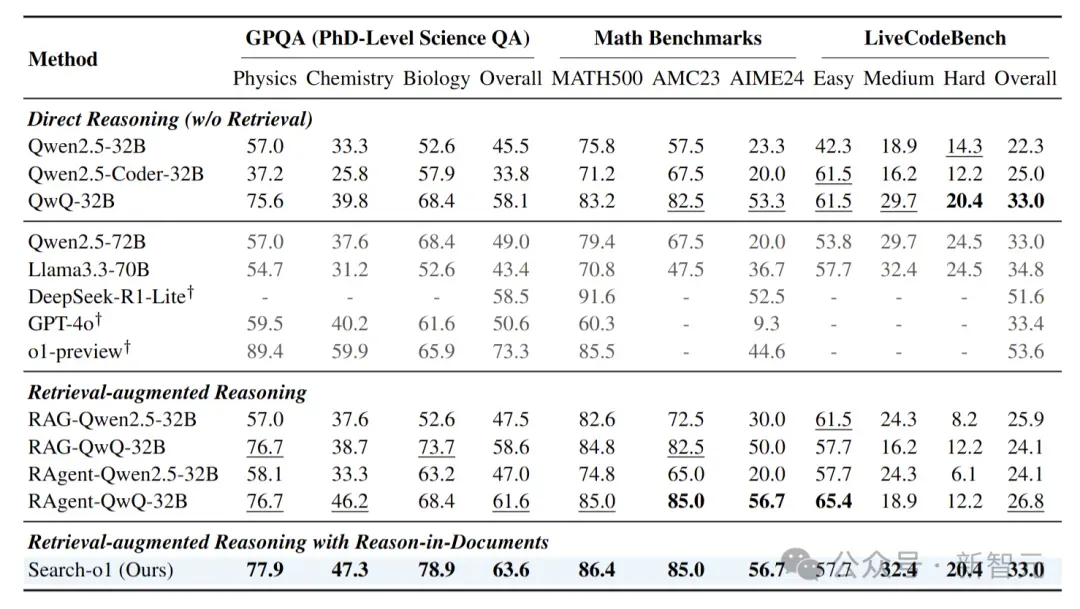 Search-o1在复杂推理任务的表现
Search-o1在复杂推理任务的表现
在上述表格中我们可以发现:
QwQ-32B-Preview优势显著,无论有无检索,它都强于传统指令微调的大语言模型。在直接推理时,32B的QwQ模型比Qwen2.5-72B、Llama3.3-70B等更大模型表现还好,表明o1类长CoT方法在复杂推理的有效性。
RAgent-QwQ-32B表现突出,其智能体检索机制可自主补充推理知识,多数任务中优于标准RAG模型和直接推理的QwQ-32B。但非推理模型Qwen2.5-32B 用智能体RAG时,在GPQA与标准RAG持平,数学和代码任务却下降,说明普通LLM难以用检索解决复杂推理。
Search-o1性能卓越,在多数任务中超越RAgent-QwQ-32B。平均来看,它比RAgent-QwQ-32B和QwQ-32B分别高4.7%和3.1%,比非推理模型Qwen2.5-32B和Llama3.3-70B分别高出44.7%和39.3%。
检索文档数量的扩展分析
在本次实验里,我们探究了性能如何随着检索文档数量的改变而变化,相关结果呈现在下图中。
实验结果显示,Search-o1能高效利用逐步增多的检索文档。随着文档数量增加,它在处理复杂推理任务时,性能得到显著提升。
值得关注的是,即便Search-o1仅检索一个文档,其整体性能也优于直接推理(Direct Reasoning),以及使用十个检索文档的标准RAG模型。
这一结果进一步证实了代理型搜索(Agentic Search)与文档内推理(Reason-in-Documents)策略行之有效。
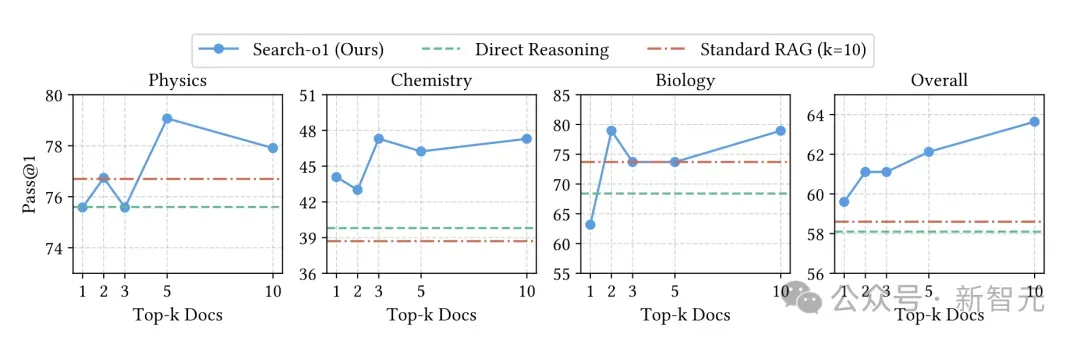 推理中使用的top-k检索文档的扩展分析
推理中使用的top-k检索文档的扩展分析
与人类专家的比较
作者在GPQA扩展集中将 Search-o1 的性能与各领域的人类专家进行了比较。下表展示了来自物理学、化学和生物学等多个学科的人类专家评估结果。
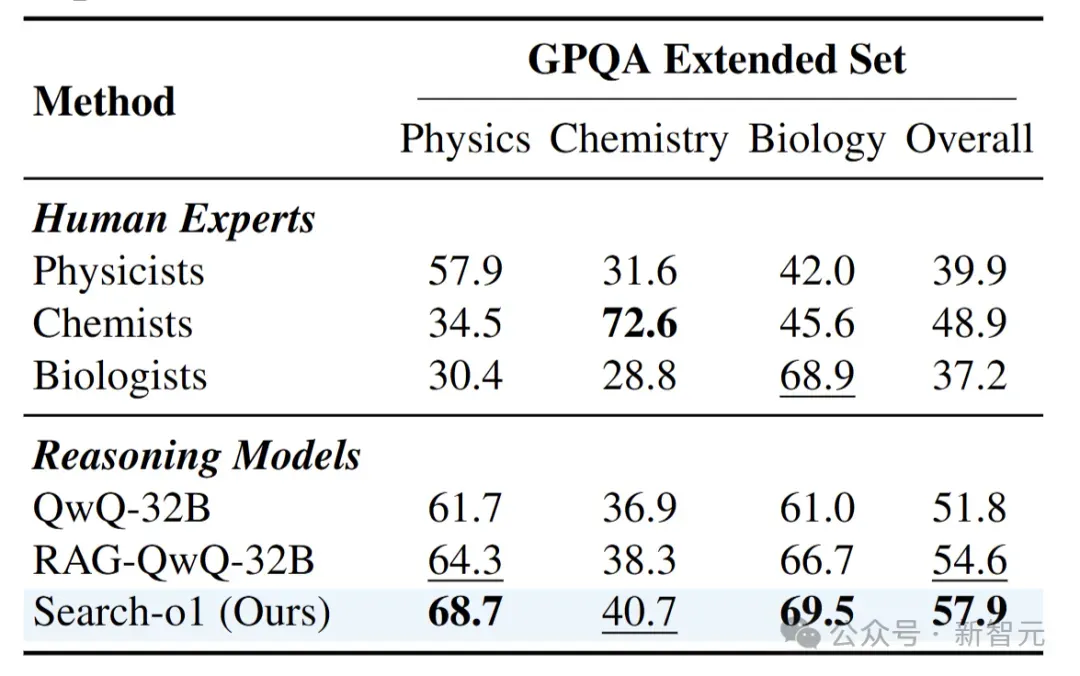
Search-o1模型在整体性能(57.9)以及物理学(68.7)和生物学(69.5)方面均优于人类专家,展示了其在处理复杂推理任务上的卓越能力。尽管Search-o1在化学子领域(40.7vs.72.6)逊于化学家,但总体上仍具有竞争优势,特别是在跨多个领域的通用性能方面。
这凸显了Search-o1在利用文档检索和推理实现跨领域性能方面的有效性,其表现可与专家级能力相媲美甚至超越。
这些发现也揭示了Search-o1在显著提高LRMs的可靠性和多功能性方面的潜力,为复杂问题解决场景中更可信、更有效的智能系统实现铺平了道路。
参考资料:
https://search-o1.github.io/
https://arxiv.org/abs/2501.05366