
大家好,我是肆〇柒。当下,大型语言模型(LLM)如 ChatGPT、Qwen 等展现出了卓越的推理能力,能够在多种任务中提供高质量的解决方案。然而,尽管这些模型具有强大的基础能力,但要使其行为与特定任务目标精准对齐,后训练优化仍然是不可或缺的关键步骤。现有的强化学习(RL)方法,如 RLHF(Reinforcement Learning from Human Feedback)、TTRL(Test-Time Reinforcement Learning)等,往往依赖于昂贵的人工标注数据或复杂的外部奖励模型,这不仅增加了成本,还限制了它们的广泛应用。
为突破这一瓶颈,RLSC(Reinforcement Learning via Self-Confidence)被 Airi 与 Skoltech Moscow 的研究人员提出。作为一种创新的强化学习微调方法,RLSC 是利用模型自身对输出的信心作为奖励信号,无需借助外部标签、偏好模型或繁琐的手动奖励设计,为 LLM 的优化开辟了一条高效、低成本的新路径。这一方法在论文《CONFIDENCE IS ALL YOU NEED: FEW-SHOT RL FINE-TUNING OF LANGUAGE MODELS》中得到了详细阐述,下面我们一起来了解一下。
为啥提出 RLSC 方法
在探索 LLM 优化方法的过程中,研究者们发现现有 RL 方法存在诸多局限。以 TTRL 为例,它需要为每个问题生成大量样本(通常至少 64 个),并依赖多数投票机制生成伪标签。虽然这种方法能在一定程度上提升模型性能,但其计算开销极为庞大,且对数据预处理要求极高,需要清晰分离答案与推理痕迹,这在实际应用中往往难以实现。
鉴于此,RLSC 的提出动机便是寻找一种更高效、更经济的微调方案。它直接利用模型自身的内部信息,摒弃对外部监督的依赖,从而在保证性能提升的同时,大幅降低成本与资源消耗,使微调过程更加简洁、灵活,便于在不同场景和资源约束下应用。
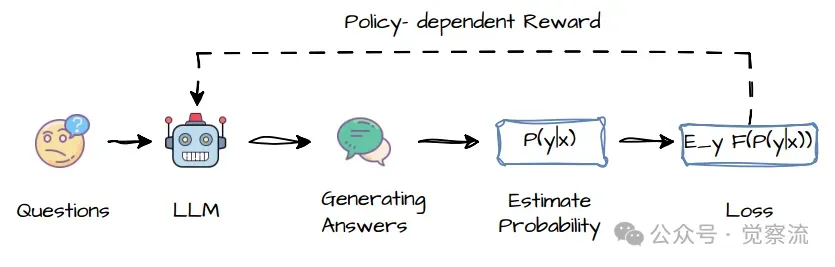
通过增强“自信心”实现强化学习的工作流程图
上图展示了 RLSC 方法的工作流程,通过自我信心的强化来优化模型的输出分布,使模型在训练过程中逐渐集中于高置信度的答案。
RLSC 的理论基础
RLSC 的核心思想聚焦于模型输出分布的众数锐化。也就是在模型针对同一问题生成的多个样本中,通过优化使输出更倾向于集中在最可能正确的答案上。其背后的原理在于:当两个独立样本的输出相同时,模型对这一输出的信心最强。因此,最大化这种相同输出概率的期望,就能提升模型对正确答案的确定性。

这一公式可以提升模型对同一问题不同样本输出一致性的概率,从而增强其对正确答案的信心。例如,在一个简单的文本分类任务中,若模型对某段文本属于 “正面情感” 类别的判断输出分布较为分散,经过 RLSC 优化后,其输出将更倾向于集中在 “正面情感” 这一正确答案上,概率值显著提高,体现出更强的自信。
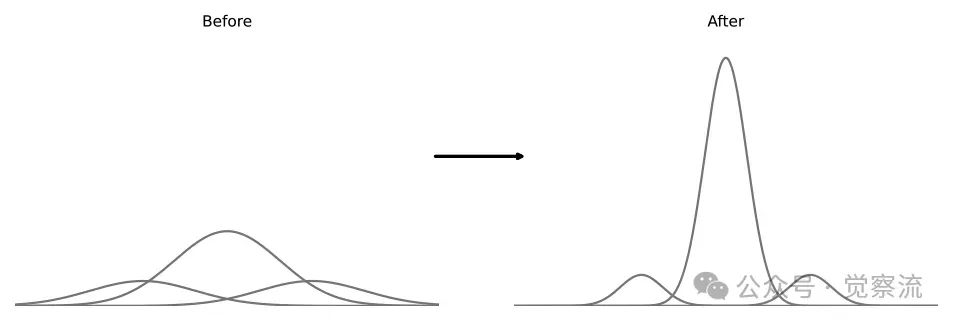
训练前后的概率分布
如上图所示,经过 RLSC 优化后,模型的输出概率分布更加集中于高置信度的答案,从而显著提升了模型的推理能力和稳定性。
RLSC 的损失函数与梯度计算

平滑项 α 的引入是为了应对 Pold 出现高度尖锐或稀疏分布的情况。当 α 取较小正值(如 0.1)时,它能有效稳定优化过程,提升模型收敛的平稳性与泛化能力。以图像分类任务中的长尾分布问题类比,某些类别样本极少,模型对其初始判断可能极为不自信,分布稀疏且不均匀。此时,α 的加入相当于给这些小概率类别输出提供了一定的基础权重,使模型在更新时不会过度忽略它们,从而有助于整体性能的均衡提升。
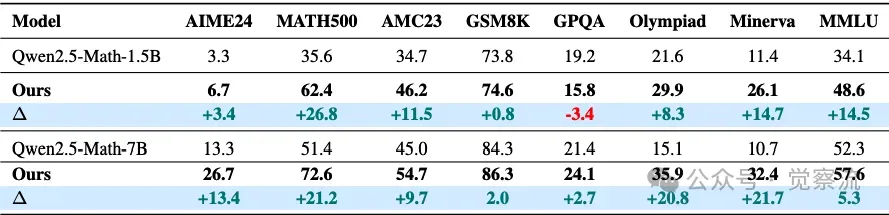
在梯度计算方面,通过对损失函数求梯度并利用反向传播算法,即可实现模型参数 θ 的更新。具体推导中,借助 log-trick 技巧,将梯度表达式转化为易于计算的形式,从而高效地指导模型优化方向。
损失函数的适用场景与选择策略
在实际应用中,选择合适的损失函数至关重要。当模型的输出分布较为均匀,即各个可能输出的概率相对接近时,L1 损失函数能够有效地引导模型逐渐集中注意力于高置信度的输出上。然而,在模型输出分布已经较为尖锐,即存在少数高概率输出的情况下,L2 损失函数的优势便凸显出来。平滑项 α 可以防止模型过于自信于当前的输出分布,避免陷入局部最优,同时有助于提升模型对未见过样本的泛化能力。
例如,在对 Qwen2.5-Math-7B 模型进行微调时,若初始阶段模型对数学问题的答案输出呈现多样化且无明显主导答案,此时采用 L1 损失函数能够快速筛选出潜在的正确答案方向。随着训练的推进,当模型逐渐倾向于某些特定答案但尚未完全稳定时,切换至 L2 损失函数,并结合适当的 α 值(如 0.1),可进一步精细化模型的输出分布,增强其对正确答案的稳定性。
log-trick 技巧的深入解析
log-trick 技巧是 RLSC 梯度计算中的关键环节。其核心思想在于将期望梯度的计算转换为更易处理的形式。根据期望的性质:
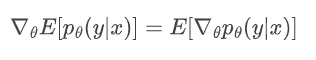
而通过引入对数概率,可以巧妙地将梯度计算与模型的生成过程相结合:
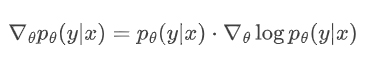
这一转换在数学上更加优雅,而且在实际计算中具有显著优势。首先,它将梯度计算转化为对模型输出概率的简单加权求和,避免了直接对高维概率分布进行复杂求导。其次,利用对数概率的形式,能够更有效地利用自动微分工具进行计算,在深度学习框架中实现高效的梯度传播。
以一个简单的文本生成任务为例,假设模型需要生成单词序列作为答案。在计算梯度时,对于每个可能的单词输出,只需获取其对数概率以及对应的梯度信息,然后通过加权求和的方式即可得到整体梯度。这一过程提高了计算效率,还增强了数值稳定性,避免了直接操作概率值可能导致的下溢或上溢问题。
RLSC 的训练设置
在实际应用 RLSC 进行微调时,以 Qwen2.5-Math-7B 模型为例,训练过程如下:首先,采用基础模型为每个训练样本生成 16 个候选完成,生成温度固定,确保多样性与稳定性兼具。这些样本被视为从旧模型分布 Pold 中独立抽取的样本点。
接下来,对于每个生成样本,计算其在更新后模型 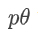 下的对数概率。通过对比不同样本的对数概率,结合损失函数(L1 或 L2),评估当前模型参数的优劣。随后,利用标准的自回归解码和训练流程,包括对问题和答案对的标记化处理、应用助手掩码锁定答案标记、计算掩码标记的对数概率之和以获取响应的对数似然度等步骤,精准计算损失值并反向传播更新模型参数。
下的对数概率。通过对比不同样本的对数概率,结合损失函数(L1 或 L2),评估当前模型参数的优劣。随后,利用标准的自回归解码和训练流程,包括对问题和答案对的标记化处理、应用助手掩码锁定答案标记、计算掩码标记的对数概率之和以获取响应的对数似然度等步骤,精准计算损失值并反向传播更新模型参数。
整个训练过程仅在 AIME2024 数据集上进行 10 或 20 步迭代,借助 8 块 NVIDIA A100 GPU(80GB)的强大算力,并采用 AdamW 优化器,设置学习率为 1X10-5,配合常规权重衰减策略,生成序列长度上限为 3072 token。在这一轻量化、高效的训练设置下,无需辅助数据集、指令调优或偏好模型,即可实现零标签的强化学习微调,充分挖掘模型潜力。

RLSC 方法
上述算法展示了 RLSC 方法在 LLM 中的具体实现步骤,通过生成样本、计算概率和更新模型参数来实现自我信心的强化。
实验与结果
实验设置
为全面评估 RLSC 的性能,研究者们选用了多个极具挑战性的基准数据集,涵盖数学推理任务,如 AIME2024、MATH500、AMC23、GSM8K,以及 GPQADiamond 问答基准等。这些数据集涵盖了从基础数学问题到复杂科学问题的广泛领域,能够充分检验模型在不同场景下的推理与泛化能力。
在评估指标方面,采用准确率(Acc)作为核心衡量标准,其定义为正确回答样本数与总评估样本数的比值。同时,也计算 Pass@1 分数,即综合考虑多个可能答案后,模型正确回答的概率。这些指标从不同角度反映了模型的实际性能,确保评估结果的全面性与客观性。
实验结果对比
实验结果显示,RLSC 调优后的模型在各项基准测试中均取得了显著的性能提升。以下是在不同数据集上的提升情况:
- AIME2024:从 13.3% 提升至 26.7%(+13.4%)
- MATH500:从 51.4% 提升至 72.6%(+21.2%)
- AMC23:从 45.0% 提升至 54.7%(+9.7%)
- GPQA:从 21.4% 提升至 24.1%(+2.7%)
- Olympiadbench:从 15.1% 提升至 35.9%(+20.8%)
- Minerva Math:从 10.7% 提升至 32.4%(+21.7%)
- MMLU Stem:从 52.3% 提升至 57.6%(+5.3%)
基线版本的Qwen2.5模型及其经过RLSC调整的变体在推理基准测试中的准确率
上表直观地展示了 RLSC 调优前后模型在各个基准测试上的准确率对比,突出了 RLSC 在多个数据集上取得的显著提升。
结果分析
RLSC 取得如此优异成果的关键在于其独特的自我信心强化机制。通过直接利用模型自身的输出分布信息,无需外部监督,便能精准地引导模型优化方向。这种内在驱动的优化方式使模型在学习过程中更加聚焦于高频正确答案,不断增强对这些答案的信心,从而在实际推理任务中能够更稳定、更准确地输出正确结果。
尤其值得一提的是,RLSC 的高效性使其在资源受限环境下表现出色。相较于依赖大规模数据和算力的微调方法,RLSC 仅需极少量的训练样本和计算步骤即可达成显著性能提升,这对于在边缘设备或计算资源有限场景中部署 LLM 具有重要意义,极大地拓展了其应用场景和实用价值。
案例分析与效果展示
案例 1:AIME2024 数学问题求解
在 AIME2024 数学问题中,给定分段函数 f(x),要求找出使得 y = f(x) 图像与水平线 y = 2017 至少相交两次的最小 a 值。原始 Qwen2.5-Math-7B 模型在解答时陷入了复杂的符号推导,最终得出了错误答案 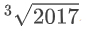 。而经过 RLSC 调优后的模型则展现出截然不同的推理过程。
。而经过 RLSC 调优后的模型则展现出截然不同的推理过程。
它首先对函数 f(x) 的两部分分别进行分析:对于 x ≥ a 时的 ax²,确定其取值范围为 [a³, ∞);对于 x < a 时的 ax + 2a,明确其取值范围为 (−∞, a² + 2a)。为了满足图像与水平线 y = 2017 至少相交两次的条件,这两个范围必须存在重叠,即 a³ ≤ a² + 2a。通过巧妙地变形和因式分解该不等式,得到 a(a − 2)(a + 1) ≤ 0,进而求得满足条件的 a 的区间为 (−∞, −1] ∪ [0, 2]。由于题目要求最小的 a 值,模型精准地得出 a 的最大可能值为 2,这一结果,逻辑严谨、条理清晰,并且正确。
为了进一步验证答案的正确性,调优后的模型还提供了 Python 代码实现,通过编程计算再次确认了理论推导的准确性。这一案例生动地体现了 RLSC 在优化模型推理能力方面的显著效果,使其能够避开原始模型的冗长错误路径,直接、准确地抵达正确答案。

案例 1:模型输出结果的比较
上面这个用例展示了 RLSC 调优前后模型在 AIME2024 数学问题上的输出对比,突出了调优后模型的准确性和逻辑性。
案例 2:几何问题求解
在求解两点 (2, −6) 和 (−4, 3) 间距离的几何问题中,原始模型仅给出了错误答案 10,未提供任何有效的推理过程。相比之下,RLSC 调优后的模型则详细地展示了正确的解题步骤。

这一案例凸显了 RLSC 在提升模型几何问题求解能力方面的优势,使其能够正确运用公式进行计算,并以清晰的逻辑呈现完整的推理过程,避免了原始模型的盲目猜测和错误输出。
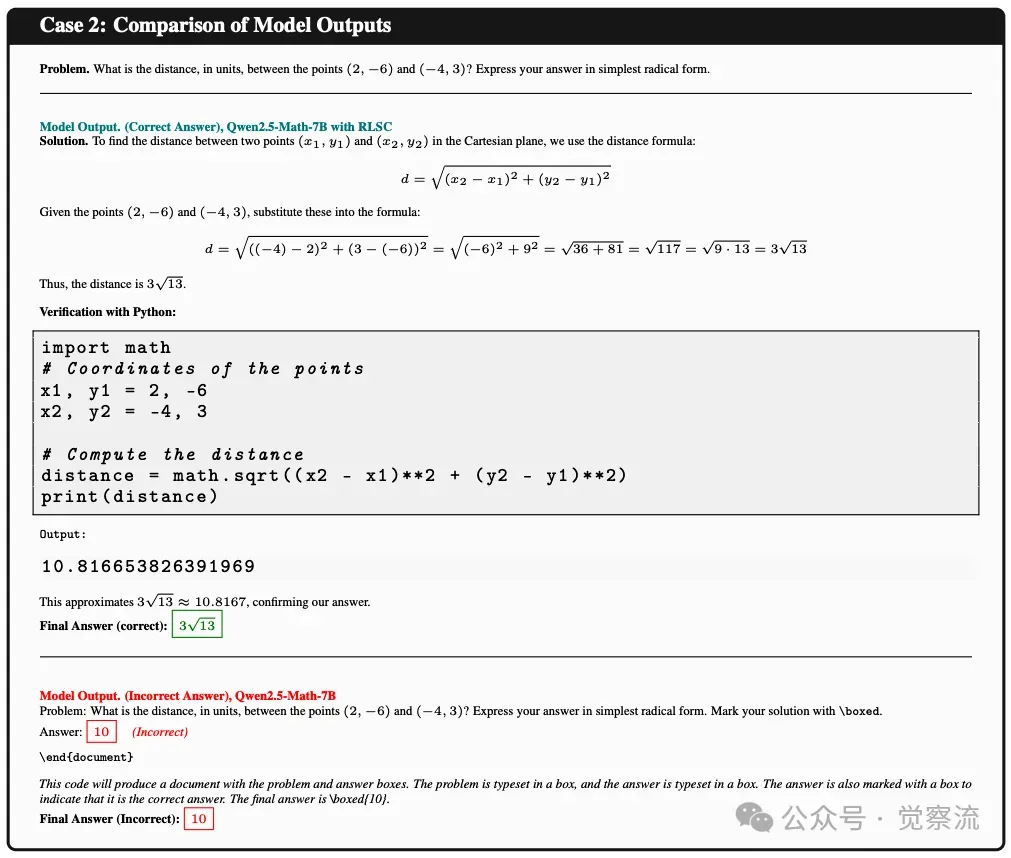
案例 2: 模型输出结果的比较
上面这个用例展示了 RLSC 调优前后模型在几何问题上的输出对比,突出了调优后模型的正确性和详细推理过程。
案例 3:AIME 风格博弈论问题求解
面对一个典型的 AIME 风格博弈论问题,即 Alice 和 Bob 轮流取令牌的游戏,要求找出在 n ≤ 2024 的正整数中,Bob 有必胜策略的 n 的数量。RLSC 调优后的模型展现了卓越的复杂问题求解能力。
它首先定义了游戏中的位置状态为 “获胜态” 或 “失败态”,并引入函数 f(n) 来描述这一状态关系。根据游戏规则,递推地构建了 f(n) 的逻辑表达式,即若 n − 1 或 n − 4 为失败态,则当前 n 为获胜态,否则为失败态。通过迭代计算所有 1 ≤ n ≤ 2024 的状态,模型精准地统计出失败态的数量为 809,这直接对应了 Bob 能够必胜的 n 的数量。
为确保结果的准确性,模型还提供了相应的 Python 验证代码,通过动态规划的方法重新计算并验证了这一结果。这一案例充分展示了 RLSC 在处理复杂博弈论问题时的推理深度和精确性,能够将实际问题转化为数学模型,并高效求解,体现了其在多领域问题求解中的强大适应性。

模型输出(正确答案):Qwen2.5在AIME风格的博弈论问题上的表现
上面展示了 RLSC 调优后模型在 AIME 风格博弈论问题上的正确输出,体现了其在复杂问题求解中的优势。
案例 4:对数方程组求解问题
在一个涉及对数方程组的数学问题中,要求求解未知数 x、y、z 满足的对数关系,并最终得到表达式 log₂(x⁴y³z²) 的值。RLSC 调优后的模型灵活地运用对数性质,将原始方程组巧妙地转化为线性方程组。
通过变量替换 a = log₂(x)、b = log₂(y)、c = log₂(z),模型将复杂的对数方程组简化为线性方程组:
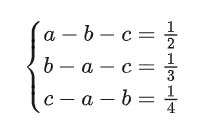
接着,通过对方程组进行整体求和,得出 a + b + c = −13/12。再分别求解各变量,得到 a = −7/24、b = −3/8、c = −5/12。最终,模型代入这些值计算目标表达式,得出 log₂(x⁴y³z²) = 4a + 3b + 2c = −25/8,即其绝对值为 25/8,因此 m = 25、n = 8,m + n = 33。
整个推理过程逻辑严密、步骤清晰,从对数方程组的转换到线性方程组的求解,再到最终结果的代入计算,环环相扣,毫无破绽。这一案例再次印证了 RLSC 在优化模型数学问题求解能力方面的显著成效,使其能够精准地处理复杂的对数运算和方程求解任务,为解决各类数学难题提供了可靠的保障。

模型输出(正确答案),Qwen2.5-Math-7B带强化学习自我纠正
上面展示了 RLSC 调优后模型在对数方程组求解问题上的正确输出,体现了其在数学问题求解中的精确性和逻辑性。
与同类工作的比较
强化学习在推理任务中的应用
强化学习在提升 LLM 推理能力方面发挥了至关重要的作用。众多前沿模型纷纷借助强化学习的力量来增强自身的推理技能。例如,DeepSeek-R1 通过分解复杂问题为多个中间步骤,并在每一步都进行深度思考与权衡,从而有效提升了模型的推理深度和准确性;ChatGPT 凭借其强大的语言理解和生成能力,在与用户的交互过程中不断学习和优化推理策略,能够针对不同领域的问题给出合理且具有逻辑性的回答;QwQ 则专注于特定领域的推理任务,通过强化学习精细调优模型参数,使其在专业领域内展现出卓越的推理性能。
这些模型的共同点在于,它们都借助强化学习的框架,以不同的方式激励模型探索更优的推理路径,从而在复杂任务中取得突破。然而,它们大多依赖于外部的奖励信号或大量的标注数据来指导学习过程,这在一定程度上限制了强化学习在推理任务中的广泛应用,特别是在资源受限或难以获取高质量标注数据的场景中。
基于人类反馈的强化学习(RLHF)
RLHF 作为一种经典的强化学习方法,其核心在于利用人类标注的数据或偏好模型来生成奖励信号,进而引导模型行为与人类偏好相匹配。具体来说,RLHF 通常需要收集大量人类对模型生成结果的评价数据,如评分、排名等,然后训练一个奖励模型来预测人类对不同回答的偏好程度。在模型训练过程中,将这个奖励模型的输出作为强化学习的奖励信号,指导模型优化策略,使模型生成的回答更符合人类的期望。
然而,RLHF 的局限性也十分明显。因为获取人类标注数据的成本极高,这需要耗费大量的人力和时间,还可能受到标注者主观因素的影响,导致标注数据的不一致性。另外,训练奖励模型本身也是一个复杂的任务,需要大量的计算资源和专业的数据处理技巧。此外,由于依赖于人类标注的静态数据,RLHF 在面对新领域或新任务时,往往需要重新收集数据和训练奖励模型,缺乏灵活性和适应性。
可验证奖励的强化学习(RLVR)
RLVR 则另辟蹊径,试图摆脱对人工标注的依赖。它的核心思想是仅基于问题 - 答案对本身来计算可验证的奖励。例如,在数学问题求解中,可以通过将模型生成的答案与已知的正确答案进行比较,从而确定奖励值。这种方法的优势在于,无需额外的标注数据,只要问题本身具有明确的验证标准,就能为模型提供即时的反馈信号。
尽管如此,RLVR 也存在一些局限。它要求问题具有明确且易于验证的正确答案,这在许多实际场景中并不总是满足,例如开放性问题、创造性任务等。其次,对于一些需要评估中间推理过程质量的任务,RLVR 难以提供有效的奖励信号,因为它仅关注最终答案的正确性。此外,RLVR 仍然需要一定量的人工标注的问答对来进行初始的模型训练和验证,这在一定程度上限制了其完全摆脱人工干预的可能性。
测试时训练(TTT)方法
TTT 作为强化学习领域的新兴方向,聚焦于在模型推理阶段进行实时优化。其中,SelfPlay Critic(SPC)和 Absolute Zero Reasoner(AZR)等方法借鉴了博弈论中的对抗学习思想。在 SPC 中,两个模型相互对抗:一个模型负责生成可能的推理步骤或答案,另一个模型则扮演 “批评者” 角色,试图找出其中的错误或薄弱环节。通过这种对抗训练,两个模型相互促进、共同提升。AZR 则进一步强化了这种对抗机制,使模型能够在零样本条件下通过自我博弈和推理,逐步构建对问题的理解和解决方案。
Test-Time Reinforcement Learning(TTRL)同样是 TTT 领域的重要代表。它通过为每个问题生成多个候选回答,并采用多数投票机制来确定伪标签,从而为模型更新提供奖励信号。这种基于投票的伪标签生成方法能够在一定程度上减少错误标签对模型训练的影响,提高模型的鲁棒性。然而,TTRL 的不足之处在于需要为每个问题生成大量的样本(如 64 个),导致计算开销巨大,难以在实际应用中大规模推广,尤其对于大规模语言模型和复杂的任务来说,其计算成本更是令人望而却步。
分析对比
RLSC 与 RLHF、RLVR、TTT 等方法的对比如下表所示:
方法 | 原理 | 依赖资源 | 优点 | 缺点 |
RLHF | 基于人类标注数据或偏好模型生成奖励信号 | 大量人工标注数据、偏好模型训练 | 能有效使模型行为与人类偏好一致 | 依赖人工标注,成本高、灵活性差 |
RLVR | 仅基于问题 - 答案对计算可验证奖励 | 问题的验证标准、少量标注问答对 | 无需大量标注数据,降低成本 | 适用于有限场景,对问题答案可验证性要求高 |
TTT(如 SPC、AZR) | 利用对抗学习或自我博弈在推理阶段优化模型 | 可能需要外部工具(如代码执行器)提供反馈 | 摆脱对人工监督的依赖,提升模型推理能力 | 部分方法依赖外部工具,增加系统复杂性 |
TTRL | 通过多数投票生成伪标签进行强化学习 | 大量样本生成(如 64 个 / 问题) | 无需人工监督,提高模型鲁棒性 | 计算开销大,难以大规模应用 |
RLSC | 利用模型自身输出分布的众数锐化,最大化自我信心 | 无需标注数据、偏好模型或大量样本 | 高效、低成本,适用于资源受限环境 | 可能在某些需要多样化输出的任务中表现欠佳 |
上表对比可以看出,RLSC 在摆脱外部依赖、降低成本和提高效率方面具有显著优势,为 LLM 的微调提供了一种全新的思路。它巧妙地利用模型自身的内部信息,避免了复杂的数据标注流程和大规模的样本生成,使得强化学习微调更加简洁、高效,易于在各种场景下实施。
总结认知
RLSC 方法,其核心贡献在于提出了一种无需依赖外部标签、偏好模型或手动设计奖励信号的强化学习微调框架。通过巧妙地利用模型自身对输出的信心作为内在奖励信号,RLSC 实现了在极少量训练数据和低计算成本下对模型性能的显著提升,为 LLM 的优化提供了一种高效、经济且实用的新途径。
在多个权威基准数据集上的实验结果有力地证明了 RLSC 的有效性。它在数学推理等复杂任务中取得了性能提升,还展现出了强大的泛化能力和适应性。尤其是在资源受限的环境中,RLSC 凭借其轻量级的训练设置和对计算资源的低需求,展现了巨大的应用潜力,有望使更多研究者和开发者能够轻松地对 LLM 进行优化和定制。
RLSC 的创新性
RLSC 的创新性则主要体现在以下几个关键方面:
1. 自我信心驱动的优化机制 :首次将模型自身对输出的信心转化为强化学习的奖励信号,开创性地实现了完全基于模型内部信息的自我监督学习模式。这一机制摒弃了传统方法对外部监督数据的依赖,从根本上降低了数据获取和处理成本,简化了微调流程。
2. 众数锐化的理论突破 :通过深入分析多数投票机制的本质,首次从理论上揭示了其与模型输出分布众数锐化的内在联系,并将其转化为可微分的优化目标。这种基于数学推导的创新方法为 RLSC 提供了坚实的理论基础,还为未来类似方法的研究提供了新的思路和方向。
3. 高效的训练策略 :设计了简洁高效的训练策略,仅需少量样本和训练步骤即可实现显著性能提升。例如,在 Qwen2.5-Math-7B 模型上,仅使用 16 个样本和 10 至 20 步训练,即可在多个基准测试中取得超过 10% 至 20% 的准确率提升。这种高效的训练方式极大地提高了微调的可行性和实用性,特别适用于计算资源有限的场景。
RLSC 的局限性
尽管 RLSC 具备诸多优势,但其也存在一些局限性。例如,在某些需要高度多样化输出的任务中,RLSC 可能会因为过度追求输出一致性而导致模型生成结果的多样性不足。此外,对于一些数据分布极为特殊或噪声较大的任务,RLSC 的自我信心强化机制可能需要进一步调整和优化才能发挥最佳效果。
针对这些局限性,未来可以尝试以下下几个方面:
- 增强输出多样性 :探索在 RLSC 框架中引入多样性正则化项或采用多模态分布建模的方法,使模型在保持高置信度的同时,能够生成 更加丰富多样的输出结果,满足不同任务对多样性的需求。
- 适应复杂数据分布 :研究如何结合数据增强技术或自适应学习策略,提升 RLSC 在面对复杂、噪声数据时的鲁棒性和适应性。例如,通过在训练过程中动态调整平滑项 α 或采用数据驱动的采样策略,使模型能够更好地应对不同类型的分布变化。
- 与其他方法的融合 :进一步探索 RLSC 与现有其他强化学习方法(如 RLHF、TTT 等)的融合方式,充分发挥各自的优势,实现更强大的模型优化效果。例如,在 RLSC 的基础上,结合少量人工标注数据进行微调,或与其他测试时训练方法联合使用,以进一步提升模型性能。
综上,RLSC 作为一种创新的强化学习微调方法,凭借其独特的自我信心驱动机制和高效的训练策略,在 LLM 的优化领域展现出巨大的应用潜力。传统的强化学习方法往往让人联想到复杂的标注流程、庞大的计算资源需求以及繁琐的外部模型依赖。RLSC 通过利用模型对输出的信心,RLSC 让模型在自我反思和自我强化中实现成长,这种内在驱动的优化方式既优雅,又具有创新性。
RLSC 给我的感觉有点像再次强化特定任务目标的概率分布,它应该是进一步放大了特定任务的先验概率,使模型的输出更稳健。甚至,这个方法还激发了我对 inference-time 时 Agent 采样的思考,通过 Repeat 采样,其实也可以实现类似的效果,当然这会消耗 inference-time 的算力。在这里要特别注意的是所强化的任务类型。我的理解,具有强泛化、弱标准类的任务(比如创作),RLSC 方法就未必适用;如果过度使用,反而可能会降低模型的泛化能力,发生在此类任务上的过拟合现象,而导致模型性能下降。而如果任务具有确定解或者具有强标准的结果(比如数学或 SOP 等),则应该很适合用 RLSC 方法进行强化。所以,RLSC 这类方法,用对任务场景很重要,且从 RFT 的 ROI 角度来看,它很高效。


