
在“理解 RAG”系列的前几篇文章中,我们重点探讨了检索增强生成的各个方面。文章中,我们重点介绍了与大型语言模型 (LLM) 集成的检索器组件,该组件用于检索有意义且真实的上下文知识,从而提升 LLM 输入的质量,并最终提升其生成的输出响应。具体来说,我们学习了如何管理传递给 LLM 的上下文长度、如何优化检索,以及如何利用向量数据库和索引策略来有效地检索知识。
这一次,我们将把注意力转移到生成器组件,即 LLM,通过研究如何以及何时在 RAG 系统内微调 LLM,以确保其响应保持一致、事实准确并与特定领域的知识保持一致。
在继续了解作为 RAG 系统一部分的 LLM 微调的细微差别之前,让我们先回顾一下“传统”或独立 LLM 中微调的概念和过程。
什么是 LLM Fine-Tuning?
就像新购买的手机可以通过个性化设置、应用程序和装饰外壳进行调整以适应其主人的喜好和个性一样,对现有以及之前训练过的LLM 进行微调包括使用额外的专门训练数据调整其模型参数,以增强其在特定用例或应用领域的性能。
微调是 LLM 开发、维护和重用的重要组成部分,原因有二:
它使模型能够适应更特定领域(通常规模更小)的数据集,从而提高其在法律、医疗或技术等专业领域中的准确性和相关性。请参见下图中的示例。
它确保大语言模型(LLM) 及时了解不断发展的知识和语言模式,避免出现过时的信息、幻觉或与当前事实和最佳实践不一致等问题。
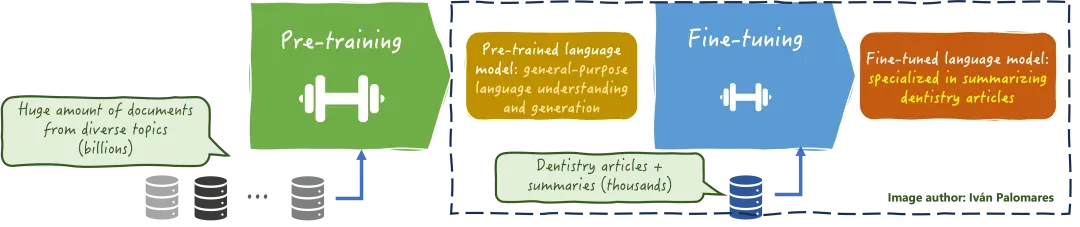
通过定期微调所有或部分参数来保持 LLM 更新的缺点,正如您可能猜到的那样,是成本问题,包括获取新的训练数据和所需的计算资源。RAG 有助于减少 LLM 持续微调的需求。然而,在某些情况下,将底层 LLM 微调到 RAG 系统仍然是有益的。
RAG 系统中的 LLM 微调:为何以及如何进行
虽然在某些应用场景中,检索器提取相关的、最新的信息来构建准确的上下文的工作已经足够,不需要定期进行 LLM 再训练,但在更具体的情况下,这还不够。
我们来看一个例子,当你的 RAG 应用需要对专业术语或特定领域推理有非常深入和全面的理解,而这些是 LLM 的原始训练数据无法捕捉到的。这可能是一个医学领域的 RAG 系统,它在检索相关文档方面可能表现出色,但 LLM 系统在基于包含有用信息的特定数据集进行微调以吸收此类特定领域推理和语言解释机制之前,可能难以正确解释输入中的知识片段。
RAG 系统 LLM 上的平衡微调频率也有助于提高系统效率,例如通过减少过多的令牌消耗,从而避免不必要的检索。
从 RAG 的角度来看,LLM 微调是如何进行的?虽然大多数经典的 LLM 微调方法也可以应用于 RAG 系统,但有些方法在这些系统中尤其流行且有效。
领域自适应预训练(DAP)
尽管名称如此,DAP 可以用作 RAG 内部通用模型预训练和特定任务微调之间的中间策略。它利用特定领域的语料库,使模型更好地理解特定领域,包括专业术语、写作风格等。与传统的微调不同,它仍然可能使用相对较大的数据集,并且通常在将 LLM 与 RAG 系统的其余部分集成之前完成,之后,将针对较小的数据集进行更有针对性、特定任务的微调。
检索增强微调
这是一种更有趣且更针对 RAG 的微调策略,通过该策略,LLM 会针对包含检索到的上下文(增强的 LLM 输入)和所需响应的示例进行重新训练。这使得 LLM 能够更熟练地利用并优化检索到的知识,从而生成能够更好地整合这些知识的响应。换句话说,通过这种策略,LLM 能够更熟练地正确使用其所依赖的 RAG 架构。
混合 RAG 微调
这种方法也称为混合指令-检索微调,它将传统的指令微调(通过将LLM暴露于指令-输出对的示例来训练其遵循指令)与检索方法相结合。在用于此混合策略的数据集中,两种类型的示例共存:一些示例包含检索到的信息,而另一些示例包含指令遵循信息。结果就会有一个更灵活的模型,可以更好地利用检索到的信息,并正确地遵循指令。
小结
本文讨论了 RAG 系统中 LLM 的微调过程。在回顾了独立 LLM 中的微调过程并概述了其必要性之后,我们将讨论转向 RAG 系统中 LLM 微调的必要性,并描述了一些在 RAG 应用中常用于微调生成器模型的常用策略。希望这些信息能够帮助您在构建自己的 RAG 系统时有所用。


