文本

小红书开源首个 AI 文本大模型:11.2T 精炼语料吊打海量数据,证明“大模型≠大数据”
近日,在中文开源大模型愈发稀缺的背景下,小红书旗下 hi lab 公布了中等规模的 MoE 模型 dots.llm1,以 1420 亿总参数、每次仅激活 140 亿参数的设计,达成与 Qwen2.5-72B 相近的性能,吸引了社区的关注。 图片据悉,dots.llm1 是一个 Mixture of Experts(MoE)结构的语言模型。 尽管总参数规模达 142B,但在每次推理中只激活 14B,有效控制了计算开销。

什么是 AI 智能体?一个例子说清楚
很多人知道,AI 可以用来聊天,帮你生成文本,比如写总结、改文案、润邮件。 但你有没有想过:这些事情,其实都可以交给一个AI 智能体自动完成? 比如这件事:你输入一些工作数据,让 AI 帮你写一篇工作总结,再稍作修改发给主管。

多模态大模型MMaDA:让AI学会「跨次元思考」,文本图像通吃的全能型选手来了!
最近,普林斯顿大学、字节跳动、清华大学和北京大学联手搞了个大事情,推出了一款名为 MMaDA 的多模态大模型! 这可不是普通的 AI,它号称能让 AI 拥有“深度思考”的能力,还能在文本、图像、甚至复杂的推理任务之间“七十二变”,表现力直接超越了你熟悉的 GPT-4、Gemini、甚至 SDXL!你可能觉得,现在的多模态模型已经很厉害了,能看图说话,也能根据文字生成图片。 但 MMaDA 告诉我们:这还远远不够!

阿里MNN神更新!移动端开源多模态AI支持Qwen-2.5,文本图像语音全搞定!
阿里巴巴开源项目MNN(Mobile Neural Network)发布了其移动端多模态大模型应用MnnLlmApp的最新版本,新增对Qwen-2.5-Omni-3B和7B模型的支持。 这款完全开源、运行于移动端本地的大模型应用,支持文本到文本、图像到文本、音频到文本和文本到图像生成等多种模态任务,以其高效性能和低资源占用引发开发者广泛关注。 AIbase观察到,MNN的此次更新进一步推动了多模态AI在移动端的普及。

英语学习永动机?手把手教你用纳米AI调用MCP自动生成带MP3的精美双语网页
一、前言纳米AI的智能体为英语学习者和教育者带来了革命性的工具。 本教程将详细指导您如何利用纳米AI的智能体,调用模型上下文协议(MCP),轻松制作包含中英双语对照、核心词汇解析以及配套MP3音频的精美英语学习素材网页,并直接生成可分享的链接。 这个过程将极大提升您制作个性化学习资料的效率。

告别低质信息图!清华、微软联手打造BizGen,一键生成专业级幻灯片和海报,让你的内容瞬间高大上!
还在为制作信息图和幻灯片绞尽脑汁,对着屏幕抓耳挠腮吗?还在被那些文字模糊、排版混乱的“高科技”生成工具气得想摔电脑吗?别担心,你的救星来了!清华大学、微软研究院等顶尖机构联手推出了一款名为BizGen的秘密武器,它就像一位技艺高超的设计大师,能够根据你提供的文章内容,瞬间变幻出专业水准的信息图和幻灯片,让你的工作效率直接起飞!你可能会疑惑,市面上不是已经有很多文本转图像的工具了吗?没错,但它们大多只能处理一些简单的句子,对于需要承载大量信息的文章级内容,就显得力不从心,生成的图片往往文字不清、布局错乱,简直是“车祸现场”。 你辛辛苦苦写了一篇长文,想用一张精美的信息图来概括重点,结果生成出来的东西连基本的文字都认不全,这难道不是一场噩梦吗?BizGen正是为了解决这个痛点而生的。 它瞄准了信息密度极高的商业内容,比如需要清晰呈现大量数据和复杂逻辑的信息图和幻灯片。
播客平台 Podcastle 推出AI文本转语音模型:提供 450 种语音
在快速发展的播客领域,Podcastle 平台近日宣布推出其全新的 AI 文本转语音模型 Asyncflow v1.0。 这个新模型不仅为用户提供了超过450种不同的 AI 语音,还向开发者开放了 API 接口,以便于他们将这一文本转语音功能直接集成到自己的应用程序中。 Podcastle 的创始人 Arto Yeritsyan 表示,公司一直希望能开发一个文本转语音模型,但由于过去高昂的训练成本和数据需求,这一愿望一直未能实现。

华科字节推出 Liquid:重新定义多模态模型的生成与理解
近年来,大语言模型(LLM)在人工智能领域取得了显著进展,尤其是在多模态融合方面。 华中科技大学、字节跳动与香港大学的联合团队最近提出了一种新型的多模态生成框架 ——Liquid,旨在解决当前主流多模态模型在视觉处理上的局限性。 传统的多模态大模型依赖复杂的外部视觉模块,这不仅增加了系统的复杂性,还限制了其扩展性。
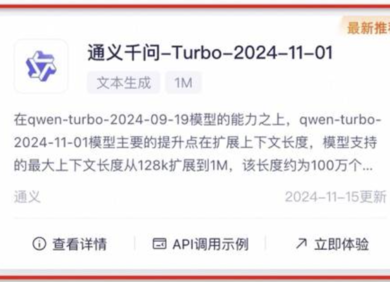
阿里云百炼上线百万长文本模型Qwen2.5 -Turbo,百万tokens仅需0.3元
11月20日消息,最新的Qwen2.5-Turbo已在阿里云百炼上线,该模型支持100万超长上下文,相当于100万个英文单词或150万个汉字,在多个长文本评测集上的性能表现超越GPT-4。 即日起,所有用户可在阿里云百炼调用Qwen2.5-Turbo API,百万tokens仅需0.3元。 全新的Qwen2.5-Turbo在1M长度的超长文本检索(Passkey Retrieval)任务中的准确率可达到100%,在长文本评测集RULER上获得93.1分,超越GPT-4;在LV-Eval、LongBench-Chat等更加接近真实场景的长文本任务中,Qwen2.5-Turbo在多数维度超越了GPT-4o-mini;此外,在MMU、LiveBench等短文本基准上Qwen2.5-Turbo的表现也非常优秀,在大部分任务上的表现显著超越之前上下文长度为1M tokens的开源模型。

超越 OCR,谷歌 AI 技术 InkSight 可精准识别手写文字
Google Research 展示了一种使用人工智能读取手写内容的新方法,名为 InkSight 的系统能够直接从手写文字的图片中提取出数字文本,无需任何中间设备。 传统的手写文字识别技术主要依赖于光学字符识别 (OCR),但这种方法在处理复杂背景、模糊不清或低光照条件下的手写文字时往往表现不佳。 InkSight 则采用了不同的思路,通过模仿人类学习阅读的过程,即通过不断地重写文本,来学习整个单词的外观和含义。
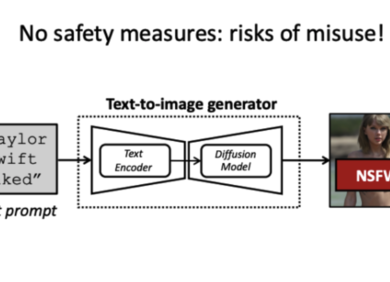
ECCV 2024|牛津大学&港科提出毫秒级文生图安全检测框架Latent Guard
最近的文本到图像生成器由文本编码器和扩散模型组成。 如果在没有适当安全措施的情况下部署,它们会产生滥用风险(左图)。 我们提出了潜在保护方法(右图),这是一种旨在阻止恶意输入提示的安全方法。

谷歌 DeepMind 开源 SynthID Text 工具,可辨别 AI 生成的文字
谷歌 DeepMind 于 10 月 23 日宣布正式开源旗下 SynthID Text 文本水印工具,供开发者和企业免费使用。 谷歌在 2023 年 8 月推出了 SynthID 工具,该工具具备创建 AI 内容水印(声明该作品由 AI 打造)和识别 AI 生成内容的能力。 它可以在不损害原始内容的前提下,将数字水印直接嵌入由 AI 生成的图像、声音、文本和视频中,同时也能扫描这些内容已有的数字水印,以辨识它们是否由 AI 生成,不过本次谷歌开源的仅为针对文本生成的 SynthID Text。

RTX 4090 笔记本 0.37 秒直出大片:英伟达联手 MIT 清华祭出 Sana 架构,速度秒杀 FLUX
一台 4090 笔记本,秒生 1K 质量高清图。英伟达联合 MIT 清华团队提出的 Sana 架构,得益于核心架构创新,具备了惊人的图像生成速度,而且最高能实现 4k 分辨率。一台 16GB 的 4090 笔记本,仅需 0.37 秒,直接吐出 1024×1024 像素图片。

端侧最强开源 AI 模型 Llama 3.2 登场:可在手机运行,从 1B 纯文本到 90B 多模态,挑战 OpenAI 4o mini
Meta 公司昨日(9 月 25 日)发布博文,正式推出了 Llama 3.2 AI 模型,其特点是开放和可定制,开发者可以根据其需求定制实现边缘人工智能和视觉革命。Llama 3.2 提供了多模态视觉和轻量级模型,代表了 Meta 在大型语言模型(LLMs)方面的最新进展,在各种使用案例中提供了更强大的功能和更广泛的适用性。其中包括适合边缘和移动设备的中小型视觉 LLMs (11B 和 90B),以及轻量级纯文本模型(1B 和 3B),此外提供预训练和指令微调(instruction-tuned)版本。AI在线附

英伟达 NVLM 1.0 引领多模态 AI 变革:媲美 GPT-4o,不牺牲性能平衡文本和图像处理难题
科技媒体 marktechpost 昨日(9 月 20 日)发布博文,报道了英伟达(Nvidia)最新发布的论文,介绍了多模态大语言模型系列 NVLM 1.0。多模态大型语言模型(MLLM)多模态大型语言模型(MLLM)所创建的 AI 系统,能够无缝解读文本和视觉数据等,弥合自然语言理解和视觉理解之间的差距,让机器能够连贯地处理从文本文档到图像等各种形式的输入。多模态大型语言模型在图像识别、自然语言处理和计算机视觉等领域拥有广阔应用前景,改进人工智能整合和处理不同数据源的方式,帮助 AI 朝着更复杂的应用方向发展。

古农文垂直领域大语言模型“齐民”发布,基于我国大量农业古籍文本训练
综合新华社、中国网消息,由农业农村部农业大数据重点实验室、中国农业科学院农业信息研究所联合湖北省图书馆、华中农业大学图书馆、郑州师范学院传播学院、中华书局古联(北京)数字传媒科技有限公司等单位开发的古农文垂直领域大语言模型“齐民”今天在北京发布。AI在线从报道中获悉,中国具备历史悠久的农业文明和耕读文化,孕育了众多的农学家、产生了大量的古农书,古农书是中国传统农业精髓的重要载体,也是我国文化遗产的重要组成部分。“齐民”古农文大语言模型基于我国古代大量农业古籍文本训练,从农业古籍中汲取智慧,深入挖掘古代农业技术、农耕

刚刚,GPT-4o关键人物离职创业!曾在OpenAI最早提出构建「Her」
OpenAI 最早提出构建「Her」的那个人,刚刚宣布离职创业了。今年 5 月份,OpenAI 发布了震惊世界的 GPT-4o。这个模型可以跨越文本、视觉和音频,以一种非常自然的形式和人类语音对话,延迟低到与人类在对话中的响应时间相似。而且,它允许用户随时打断,并能感知和回应用户的情绪。因此,该模型发布后,很多人说科幻电影《Her》中的场景照进了现实。此次离职的 Alexis Conneau 就是 GPT-4o 项目的关键人物之一。离职前,他是 OpenAI 音频 AGI 研究负责人,也是 OpenAI 最早提出

元象推出国内首个基于物理的3D动作生成模型MotionGen
www.MotionGen.cn 一句话生成复杂3D动作,效果惊艳!测试期可申请免费试用。3D内容制作领域,生成逼真的角色动作生成是一个持续挑战,传统方法依赖大量的手K制作,或昂贵动作捕捉设备,效率低、成本高、难以生成一般运动任务或适应复杂场景和交互。元象XVERSE推出国内首个基于物理的3D动作生成模型MotionGen,创新性融合大模型、物理仿真和强化学习等前沿算法,让用户输入简单文本指令,就能快速生成逼真、流畅、复杂的3D动作,效果惊艳,标志着中国3D AIGC领域的重大突破。现在起,零经验创作者也能轻松上手
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉