
最近在做项目时,我发现有些甲方对RAG和模型微调分区的不太清楚,明明大语言模型(LLM)加挂RAG就可以解决的问题,却坚持要微调,但是具体沟通后发现,其实只是不太了解二者的实际用途。
其实,Retrieval-Augmented Generation (RAG) 和微调 (Fine-Tuning) 是两种最常用的LLM的“大脑升级”技术,虽然它们都能提升模型的性能,但工作原理和适用场景却大相径庭。今天,我就来深入聊聊这两种技术,弄清楚在不同情况下,到底该选 RAG 还是微调。
RAG 和微调分别做了什么
想象一下,LLM 是一个学识渊博的大脑。
微调(Fine-Tuning)就像是给这个大脑进行一次“专科培训”。我们用一个较小的、聚焦于特定领域(比如医疗、法律)或特定任务(比如情感分析、摘要生成)的数据集,对预训练好的 LLM 进行进一步训练。通过调整模型的内部参数,让它更精通某个领域的知识或更擅长完成某个任务。就像一个通才经过医学专业的深造,变得擅长诊断疾病。
RAG(检索增强生成)则更像给这个大脑配备了一个“超级图书馆”和一位“速查助手”。当有人提问时,“助手”会迅速从外部的动态知识库(比如企业数据库、最新的新闻文章)中检索相关信息,然后将这些信息和用户的问题一起提供给 LLM 大脑,让大脑结合这些最新、最具体的信息来生成回答。这种方式不需要改变大脑本身的结构(无需重新训练模型),而是通过提供外部信息来增强其回答的准确性和时效性。就像一个博览群书的人,在回答特定问题时能迅速查阅最新资料来佐证和完善。
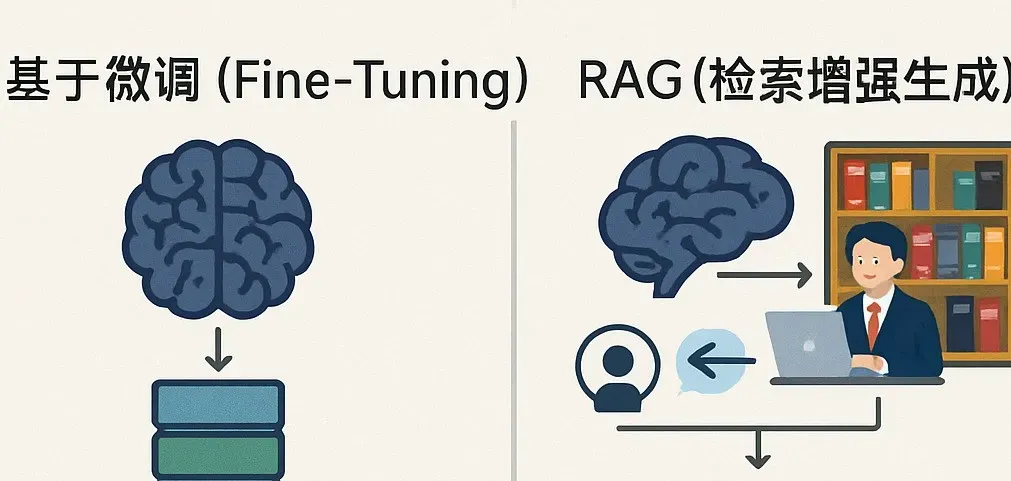
主要差异
RAG 和微调最核心的区别在于它们处理和利用知识的方式。
RAG 依赖外部动态数据源,这些数据可以实时更新,让模型始终获取最新信息,而且更新知识库无需重新训练模型。
微调则依赖固定的数据集,如果数据或任务发生变化,就需要重新进行训练,成本较高。
RAG 能够在利用外部特定知识的同时,保持模型原有的通用能力。
微调则可能因为在特定数据集上的深度训练而牺牲一部分通用性,出现所谓的“灾难性遗忘”。
而在资源需求上,RAG 主要需要在数据检索基础设施(如向量数据库)上投入,推理阶段的计算需求相对较低。
微调则在训练阶段需要消耗大量计算资源,但在推理阶段模型自身就包含所需知识。
因此,可以说RAG 更适合需要实时信息且信息源动态变化的场景,比如客户服务聊天机器人需要了解最新的产品信息,或新闻摘要应用需要抓取最新报道。
微调则更适合任务高度专精、需要对某个领域有深厚理解的场景,比如医疗诊断需要模型掌握大量医学术语和病理知识,或法律文档分析需要熟悉复杂的法律条文。
结论
RAG 和微调都是提升 LLM 能力的强大工具,但它们各有侧重,并非非此即彼。RAG 以其灵活性和实时性,擅长处理动态信息;微调则通过深度训练,让模型在特定领域达到卓越的专精度。理解两者的核心差异、优缺点及适用场景,并结合实际的项目需求、数据特点和资源状况,才能做出最明智的技术选择,甚至考虑将两者巧妙结合,打造出更强大、更符合需求的 AI 应用。
写在最后
2025年的今天,AI创新已经喷井,几乎每天都有新的技术出现。作为亲历三次AI浪潮的技术人,我坚信AI不是替代人类,而是让我们从重复工作中解放出来,专注于更有创造性的事情,关注我们公众号口袋大数据,一起探索大模型落地的无限可能!


