强化学习
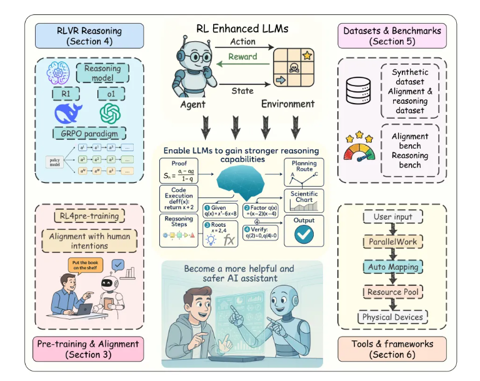
复旦、同济和港中文等重磅发布:强化学习在大语言模型全周期的全面综述
近年来,以强化学习为核心的训练方法显著提升了大语言模型(Large Language Models, LLMs)的推理能力与对齐性能,尤其在理解人类意图、遵循用户指令以及增强推理能力方面效果突出。 尽管现有综述对强化学习增强型 LLMs 进行了概述,但其涵盖范围较为有限,未能全面总结强化学习在 LLMs 全生命周期中的作用机制。 对此,来自复旦大学、同济大学、兰卡斯特大学以及香港中文大学 MM Lab 等顶尖科研机构的研究者们全面总结了大语言模型全生命周期的最新强化学习研究,完成题为 “Reinforcement Learning Meets Large Language Models: A Survey of Advancements and Applications Across the LLM Lifecycle” 的长文综述,系统性回顾了领域最新进展,深入探讨研究挑战并展望未来发展方向。

汪军对话 Rich Sutton:大模型在一定程度上分散了我们对智能理解的注意力
在刚刚落幕的 RL China 2025 开幕式上,伦敦大学学院(UCL)汪军教授与图灵奖得主、“强化学习之父” Richard Sutton 展开了一场跨越地域的思想对话,从强化学习(RL)的学科根基出发,共探智能的本质与未来方向。 汪军教授深耕智能信息系统领域多年,现任 UCL 计算机系教授,Turing Fellow,是华人强化学习社区 RL China 的联合发起人。 RL China 是由全球华人学者与强化学习相关从业者共同发起的非盈利性学术与技术交流平台,致力于推动强化学习及决策智能领域的研究、应用与教育。

从探索到验证:Parallel-R1 如何塑造大模型的"思考"哲学
大家好,我是肆〇柒。 今天看看由腾讯AI Lab Seattle联合马里兰大学、北卡罗来纳大学、香港城市大学和圣路易斯华盛顿大学共同研究的工作——Parallel-R1,它首次通过强化学习让大语言模型真正掌握了"并行思考"这一人类高级认知能力,而非仅依赖推理时策略的临时拼凑。 这项研究不仅刷新了AIME25数学竞赛基准测试的准确率记录,更揭示了机器"思考"方式的演化规律。

AI正在偷走白领工作!OpenAI狂砸10亿教AI上班,你的完美继任者即将上岗
AI正在接管白领工作吗? 今年5月,Anthropic CEO Dario Amodei曾表示:AI有可能在未来1—5年内消灭一半的入门级白领职位,并使美国失业率上涨到10—20%。 这场史无前例的岗位大替代,引发了普遍担忧。

加速近5倍!北大与字节团队提出BranchGRPO,用「树形分叉 + 剪枝」重塑扩散模型对齐
快分叉与稳收敛在扩散 / 流匹配模型的人类偏好对齐中,实现高效采样与稳定优化的统一,一直是一个重大挑战。 近期,北京大学与字节团队提出了名为 BranchGRPO 的新型树形强化学习方法。 不同于顺序展开的 DanceGRPO,BranchGRPO 通过在扩散反演过程中引入分叉(branching)与剪枝(pruning),让多个轨迹共享前缀、在中间步骤分裂,并通过逐层奖励融合实现稠密反馈。

统一视角下的HPT:动态融合SFT与RL,释放LLM后训练新潜能
大家好,我是肆〇柒。 今天探索一篇来自清华大学、上海AI实验室与微信AI团队的前沿研究。 这篇论文提出了一种名为HPT的创新算法,它像一位“智能教练”,能根据模型的实时表现,动态决定是该用监督学习“补基础”,还是用强化学习“练推理”,从而解决后训练中SFT与RL难以调和的矛盾,让模型性能实现质的飞跃。

清华、上海AI Lab等顶级团队发布推理模型RL超全综述,探索通往超级智能之路
超高规格团队,重新审视RL推理领域发展策略。 在人工智能的发展中,强化学习 (RL) 一直是一种非常重要的方法。 自 1998 年 Sutton 提出强化学习概念以来,就明确了只要给出明确的奖励信号,智能体就能学会在复杂环境中超越人类。
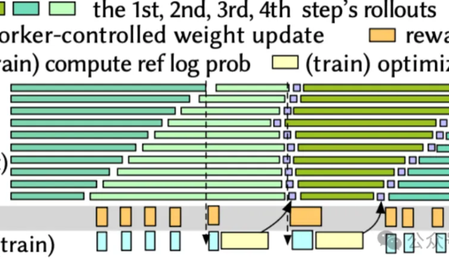
攻克强化学习「最慢一环」!交大字节联手,RL训练速度飙升2.6倍
强化学习的训练效率,实在是太低了! 随着DeepSeek、GPT-4o、Gemini等模型的激烈角逐,大模型“深度思考”能力的背后,强化学习(RL)无疑是那把最关键的密钥。 然而,这场竞赛的背后,一个巨大的瓶颈正悄然限制着所有玩家的速度——相较于预训练和推理,RL训练更像一个效率低下的“手工作坊”,投入巨大但产出缓慢。

从"调用工具"到"思考策略":Chain-of-Agents实现智能体技术的临界点突破
大家好,我是肆零柒。 今天,我们一起来了解一篇由OPPO AI Agent Team研究的论文。 这项工作名为Chain-of-Agents(CoA),它不只是一个新的AI框架,更是一次对"智能体"本质的深刻探索。

Prime Intellect 推出开放平台“环境中心”,对抗AI强化学习领域的封闭趋势
位于旧金山的人工智能初创公司 Prime Intellect 正式发布“环境中心”(Environments Hub),这是一个用于构建和共享强化学习(RL)环境的开放平台,旨在对抗当前由大型人工智能实验室主导的封闭生态。 Prime Intellect 指出,交互式训练环境已成为下一阶段 AI 发展的关键瓶颈。 在强化学习中,AI 代理通过与规则驱动的环境互动来学习,仅在面对动态变化时才能实现真正的智能。

首个为具身智能而生的大规模强化学习框架RLinf!清华、北京中关村学院、无问芯穹等重磅开源
清华大学、北京中关村学院、无问芯穹联合北大、伯克利等机构重磅开源RLinf:首个面向具身智能的“渲训推一体化”大规模强化学习框架。 人工智能正在经历从 “感知” 到 “行动” 的跨越式发展,融合大模型的具身智能被认为是人工智能的下一发展阶段,成为学术界与工业界共同关注的话题。 在大模型领域,随着 o1/R1 系列推理模型的发布,模型训练的重心逐渐从数据驱动的预训练 / 后训练转向奖励驱动的强化学习(Reinforcement Learning, RL)。
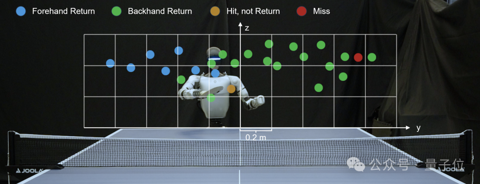
不愧是中国机器人,乒乓打得太6了
机器人打乒乓球,这(zhei)您受得了吗? 关键玩的还都是高难度:并步接球! 0.42秒极限反应回击扣球!

Meta万引强化学习大佬跑路!用小扎原话作为离别寄语,扎心了
小扎在这头疯狂挖人,结果家里的老员工纷纷跑路了? ? 最新消息,Meta万引强化学习大佬Rishabh Agarwal即将离职,还留下了一篇让人浮想联翩的小作文:这是我在Meta的最后一周。

突破Agent长程推理效率瓶颈!MIT&NUS联合推出强化学习新训练方法
AI Agent正在被要求处理越来越多复杂的任务。 但当它要不停地查资料、跳页面、筛选信息时,显存狂飙、算力吃紧的问题就来了。 针对这一难题,MIT和新加坡国立大学联合提出了MEM1框架。

微软Agent Lightning:零代码接入RL,“解耦”任何AI Agent学会“在实践中学习”
大家好,我是肆〇柒。 我从工程落地角度出发,看到一篇很有意思的研究想要分享出来。 这是一项来自微软研究团队的研究工作——Agent Lightning。

突破Agent长程推理效率瓶颈!MIT&新加坡国立联合推出强化学习新训练方法
AI Agent正在被要求处理越来越多复杂的任务。 但当它要不停地查资料、跳页面、筛选信息时,显存狂飙、算力吃紧的问题就来了。 针对这一难题,MIT和新加坡国立大学联合提出了MEM1框架。

如何训练你的大型语言模型
打造一个听起来很智能的大型语言模型 (LLM) 助手,就像在反复塑造泥塑一样。 你从一块泥土开始,把它挤压成一个可行的结构,然后开始精雕细琢,直到最终成品。 越接近最终成品,那些精妙的点缀就越重要,正是这些点缀决定了最终成品是杰作还是恐怖谷效应。

混合数学编程逻辑数据,一次性提升AI多领域强化学习能力 | 上海AI Lab
近年来,AI大模型在数学计算、逻辑推理和代码生成领域的推理能力取得了显著突破。 特别是DeepSeek-R1等先进模型的出现,可验证强化学习(RLVR)技术展现出强大的性能提升潜力。 然而,现有关于强化学习和模型的研究多聚焦于单一领域优化,缺乏对跨领域知识迁移和协同推理能力的系统性探索,让模型能够在多领域协同工作,发挥更好的推理能力。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉