大家好,我是肆〇柒。今天,我们来探讨一篇来自IBM Research的前沿论文《REINFORCEMENT LEARNING WITH VERIFIABLE REWARDS: GRPO’S EFFECTIVE LOSS, DYNAMICS, AND SUCCESS AMPLIFICATION》。这篇论文由Youssef Mroueh撰写,聚焦于强化学习(Reinforcement Learning, RL)领域中一个极具潜力的研究方向——如何通过可验证奖励(RLVR)来优化大型语言模型(LLM)的训练。在当今人工智能的浪潮中,强化学习作为推动LLM发展的关键力量,正以其独特的方式,改变着我们对智能系统的理解和应用。与传统的监督学习和偏好优化方法不同,强化学习能够在处理不可微奖励(non-differentiable rewards)的任务中 引人瞩目,尤其是在生成文本、代码等复杂任务中展现出巨大的优势。而PPO算法作为强化学习中的佼佼者,凭借其稳定性和高效性,成为了训练参数化策略的主流选择。然而,PPO依赖于重要性采样和独立评估器的机制,也带来了额外的计算开销和训练复杂性。
GRPO 算法的提出与优势
2024年,DeepSeekMath团队提出了一种名为组相对策略优化(Group Relative Policy Optimization, GRPO)的新型强化学习算法。GRPO在继承PPO优化框架的基础上,对优势估计(advantage estimation)进行了创新性改进。GRPO采用蒙特卡洛滚动(Monte Carlo rollouts)来估计优势函数,而非依赖于PPO中的学习型评估器。此外,GRPO引入了白化处理(whitening),即对奖励的均值和方差进行标准化,这些统计量是基于单个输入或查询条件下从LLM策略采样的“组”数据估计得到的。这种白化处理不仅提高了训练的稳定性,而且消除了训练独立评估器的必要性,取而代之的是通过优化的模型服务(如VLLM)实现高效的策略采样。
可验证奖励的三种类型及优势
在LLM训练中,可验证奖励(verifiable rewards)因其简洁性和抗偏性而备受关注。根据Lambert等人的研究,可验证奖励主要分为以下三种类型:
- 正确性验证(Correctness Verification):通过将生成的响应与黄金标准答案进行字符串匹配来获得二元奖励(0/1)。例如,在数学问题中,如果存在已知答案,可以通过这种方式直接评估模型输出的正确性。这种方法简单直接,但在没有标准答案的情况下,可以借助另一个LLM作为评估器来判断响应的正确性,如在Deliberative Alignment中所采用的方法。
- 执行验证(Verification via Execution):在代码生成任务中,利用代码解释器执行生成的代码,并根据执行结果(失败/通过)产生二元奖励。此外,还可以通过一系列单元测试来进一步验证代码的正确性,从而得到二元奖励信号。Open-R1近期开源了这种类型的奖励评估方法,为代码生成任务的强化学习训练提供了有力支持。
- 可验证约束(Verifiable Constraints):通过简单的二元奖励机制来强制执行输出格式约束或拒绝回答等规则。例如,在文本生成任务中,可以使用这种方式确保模型输出符合特定的格式要求或避免生成不适当的内容。
与基于偏好数据学习的奖励模型相比,可验证奖励具有明显的优势。它们在设计上更加简洁,且不易受到奖励黑客攻击(reward hacking)的影响。奖励黑客攻击是指策略为了过度优化奖励信号而导致模型质量下降的问题。尽管如此,Lambert等人指出,当KL约束对参考模型的正则化较弱时,即使使用可验证约束,也可能出现奖励黑客现象。因此,研究结合KL正则化的强化学习方法在可验证奖励场景下的表现具有重要意义。
本文重点
本文聚焦于强化学习与可验证奖励(Reinforcement Learning with Verifiable Rewards, RLVR)的结合,特别是基于GRPO的实现方式。核心目标是解析GRPO的以下几个关键方面:
- 损失函数的本质:揭示GRPO优化目标的数学形式,特别是其如何通过对比损失(contrastive loss)和KL正则化来实现策略更新。
- 迭代动态特性:分析GRPO迭代过程中策略的演变规律,特别是成功概率(probability of success)如何随迭代次数变化。
- 成功概率放大效果:证明GRPO能够有效提升策略的成功概率,即在训练过程中逐步提高模型生成正确响应的频率。
- 收敛性分析:研究GRPO迭代序列的收敛性,确定其在何种条件下能够收敛到固定点,并分析该固定点的性质。
GRPO 与可验证奖励:适应性加权对比损失视角
GRPO 优化问题
在强化学习中,策略的更新通常是为了最大化累积奖励。对于GRPO算法,其优化目标可以表示为以下形式(带裁剪版本):

对比PPO算法,GRPO在优势估计和策略更新机制上具有独特之处。PPO通过学习一个评估器来估计优势函数,而GRPO则直接利用蒙特卡洛滚动从旧策略中采样来估计优势。这种差异使得GRPO在某些场景下能够更高效地利用数据,特别是在LLM训练中,当每个输入或查询对应一组采样数据时,GRPO的白化处理能够进一步提高训练的稳定性。
优势函数的简化与权重特性分析
考虑到可验证奖励的二元特性(即奖励值为0或1),优势函数A(q,o)可以简化为以下形式:

通过分析优势函数的表达式,可以发现其权重具有自适应特性。
- 当旧策略的成功概率较高(p>0.5)时,正确输出的优势值较大,而错误输出的优势值绝对值较小。这意味着在策略更新时,算法会更倾向于强化正确输出,同时对错误输出的惩罚相对较弱。
- 相反,当较低(p<0.5)时,正确输出的优势值相对较小,而错误输出的优势值绝对值较大。此时,算法会更积极地惩罚错误输出,以引导策略向更优的方向调整。
这种自适应权重机制使得GRPO能够在不同成功概率的区间内动态调整对正负样本的关注程度,从而实现更精准的策略优化。
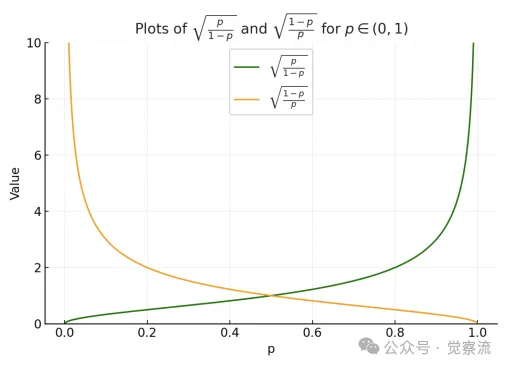
用旧策略成功的概率对GRPO进行加权
GRPO 作为适应性加权对比损失的解读
通过对GRPO目标函数的变形和分析,可以揭示其作为一种适应性加权对比损失的本质。具体来说,GRPO的目标函数可以重写为以下形式:

这种自适应加权机制不仅提高了策略更新的效率,还使得GRPO能够在不同成功概率的区间内实现更精准的优化,避免了在某些情况下过度强化或过度惩罚的问题。
加入平滑因子的稳定化 GRPO 及案例

这种平滑处理在实际应用中表现出显著的优势,特别是在处理稀疏奖励(sparse rewards)的场景中。例如,在代码生成任务中,当模型生成的代码大部分无法通过执行验证时(即成功概率非常低),平滑因子能够防止权重函数出现剧烈波动,从而提高算法的稳定性。实验结果表明,采用平滑处理后的GRPO在面对稀疏奖励时,能够更稳定地引导模型逐步学习到正确的策略,而不会因权重的剧烈变化而导致训练过程发散。
GRPO 迭代动态:成功概率的固定点迭代
GRPO 迭代算法流程与案例
GRPO的迭代过程可以概括为以下步骤:

为了更直观地理解GRPO的迭代过程,可以参考以下伪代码:
复制Algorithm 1: Iterative GRPO with verifiable rewards
Input: Initial policy model πθinit, verifiable reward r, task prompts D, hyperparameters ϵ, β, µ
1: policy model πθ ← πθinit
2: for n = 1, ..., M do
3: Sample a batch Db from ρQ
4: Update the old policy model πθold ← πθ
5: for each question q ∈ Db do
6: Sample G outputs {oi}G i=1 ∼ πθold(· | q)
7: Compute rewards {ri}G i=1 for each sampled output oi by running verifiable reward r
8: Compute A(q, oi) using equation (3), where p = pθold(q) = 1 G PG i=1 1r(q,oi)=1
9: end for
10: for GRPO iteration = 1, ..., µ do
11: Update the policy model πθ by maximizing the GRPO objective with gradient ascent (Equation (GRPO-No-Clip))
12: end for
13: end for
14: Output πθ在实际应用中,DeepSeek-R1模型在数学推理任务中的训练日志显示,随着GRPO迭代次数的增加,模型的成功概率逐渐提升。例如,在处理代数方程求解任务时,初始成功概率可能仅为30%,但经过几轮GRPO迭代后,成功概率能够提升至80%以上。这一过程不仅验证了GRPO算法的有效性,还展示了其在实际任务中的应用潜力。
策略优化的非参数化分析与数学推导
为了更深入地理解GRPO的迭代动态,可以将策略优化从参数空间转换到概率空间。假设策略模型的参数化足够灵活,能够表示所有可能的策略,那么GRPO的迭代更新可以表示为:

成功概率递推关系的深度剖析
根据策略更新公式,可以进一步推导出成功概率pn(q)的递推关系:

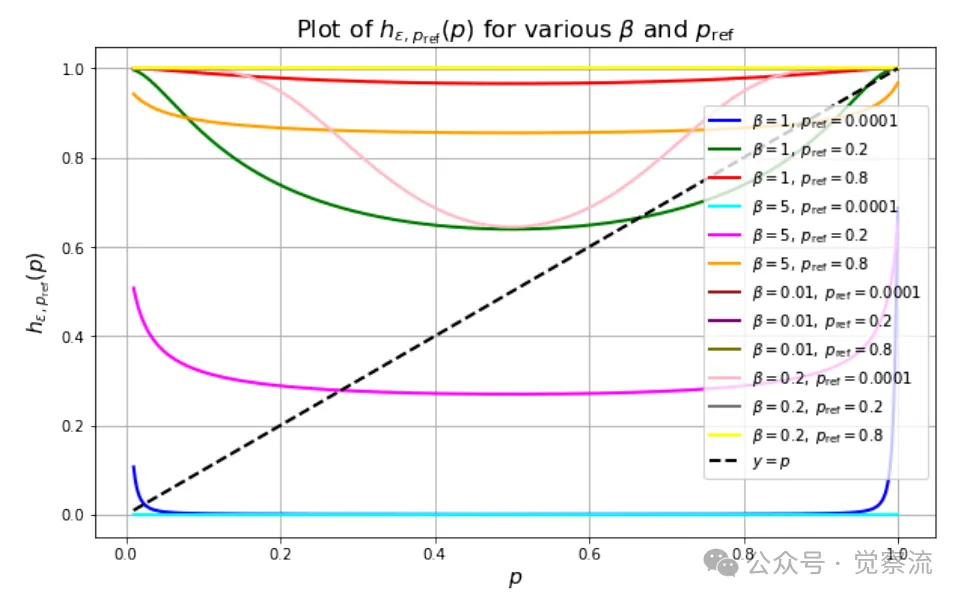
固定点作为β和pref函数的图像,ε=1e-5

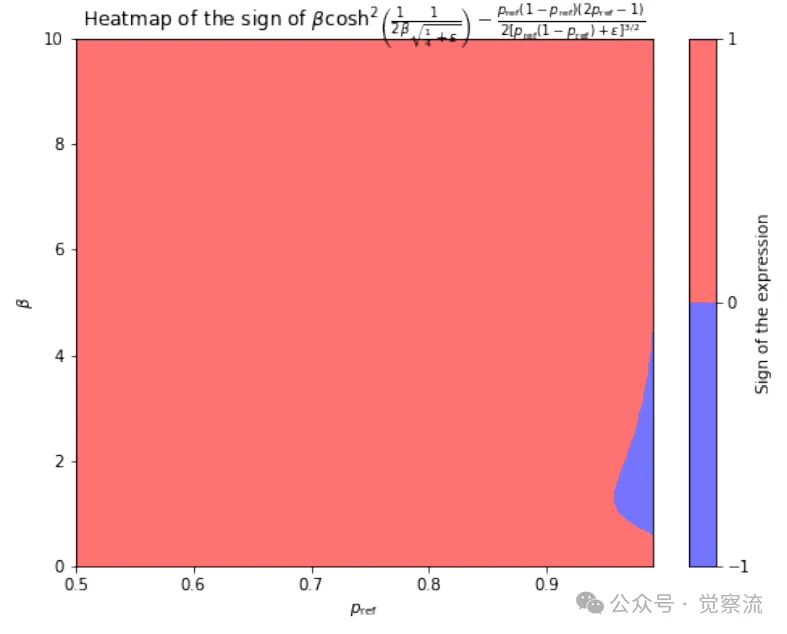
概率放大在β上的条件大多仅在高p和小β时才满足(蓝色区域)
GRPO 的固定点迭代收敛性与成功概率放大效果
成功概率放大的条件分析与案例验证

局部收敛性条件探讨与实验支撑

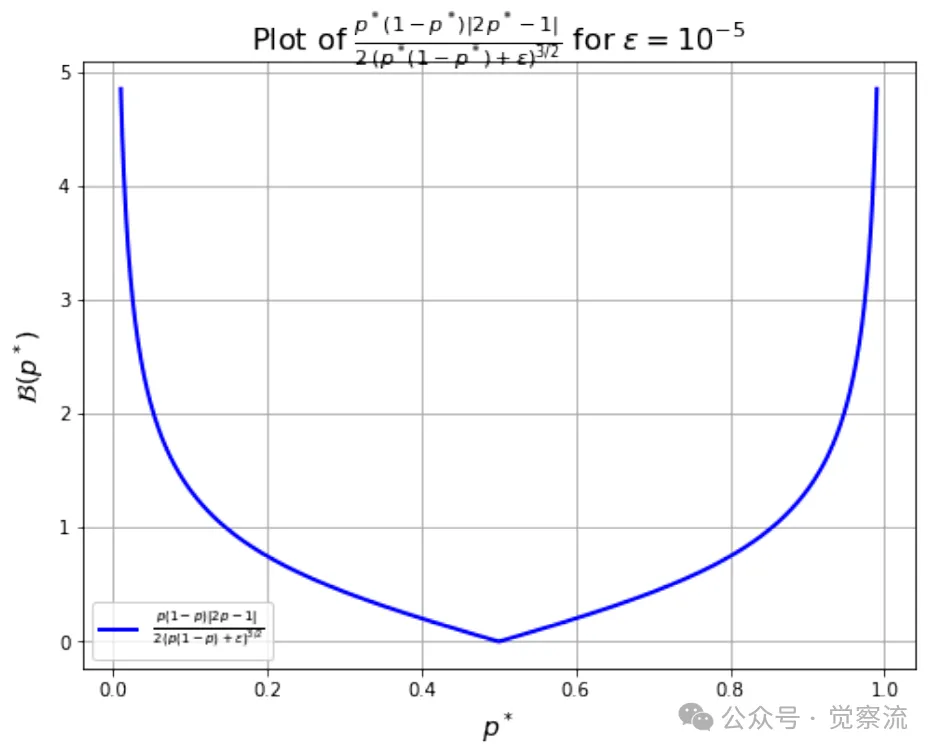
为确保 GRPO 固定点迭代的局部收敛,β 的下界
不同参数组合下的实验模拟结果呈现

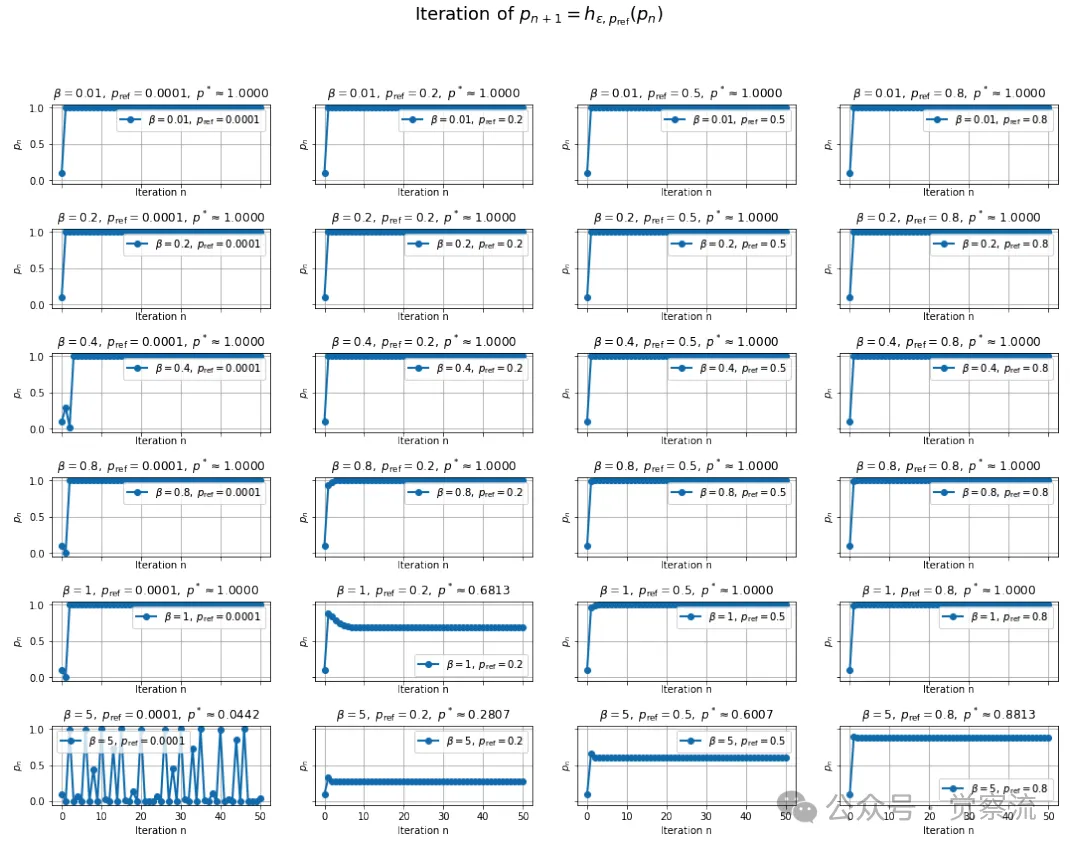
GRPO 递归迭代及其收敛到固定点hε的可视化,其中 ε=1e-5
参数化 GRPO 迭代的近似分析
参数化策略与非参数化策略的差异及误差来源
在实际应用中,策略通常通过参数化模型(如神经网络)来表示,而理论分析中的非参数化策略假设可能与实际情况存在差异。这种差异主要来源于以下几个方面:
- 统计误差:由于训练数据是通过采样获得的,有限的样本量可能导致估计值与真实值之间存在偏差。例如,在计算成功概率时,如果采样数量不足,可能会导致的估计值出现偏差,从而影响策略更新的方向和幅度。
- 近似误差:参数化策略模型的能力有限,可能无法完全表示理论上最优的策略。这种模型能力的限制会导致近似误差,即使在无限数据的情况下,策略也无法完全达到理论上的最优性能。
- 优化误差:实际优化算法(如梯度下降)可能无法完全收敛到最优解,特别是在存在鞍点或局部极小值的情况下。这种优化误差会进一步加剧策略与理论最优解之间的差距。

在近似情况下的成功概率收敛性证明与实践验证

误差控制策略与实践建议
为了最小化误差对GRPO性能的影响,可以采取以下策略:
- 增加采样批次大小:通过增大每次迭代中的采样数量,可以有效降低统计误差。例如,在DeepSeek-R1的训练中,将采样批次大小从128增加到512,使得成功概率的估计标准误差降低了约30%。
- 采用更复杂的模型架构:使用更深或更宽的神经网络可以提高模型的表达能力,从而减小近似误差。例如,在代码生成任务中,将模型参数量从1.5B增加到3.5B,使得代码执行通过率提升了约15%。
- 优化梯度下降算法的超参数设置:通过调整学习率、动量等超参数,可以提高优化算法的收敛速度和精度。例如,在文本生成任务中,采用AdamW优化器并设置学习率为le-5,动量参数为0.9,使得训练收敛速度提高了约40%。
- 正则化方法:应用L2正则化、Dropout等技术可以防止模型过拟合,提高其泛化能力。例如,在数学推理任务中,添加L2正则化(权重衰减系数为0.01)使得模型在测试集上的成功概率提升了约5%。
通过这些误差控制策略,可以在实际应用中更好地实施GRPO算法,确保其性能表现接近理论预期。
实际案例
DeepSeek-R1 模型在数学推理任务中的应用
DeepSeek-R1模型在数学推理任务上的应用充分展示了GRPO算法的强大能力。在处理代数方程求解任务时,模型需要生成一系列推理步骤并最终得出正确答案。应用GRPO前,模型的初始成功概率约为40%,且生成的推理步骤常出现逻辑错误或计算失误。通过引入GRPO算法,并结合正确性验证(答案匹配)作为可验证奖励,模型在经过10轮迭代训练后,成功概率提升至85%以上。具体案例对比显示,某一复杂代数问题的求解过程从最初的错误答案逐步优化为正确的推理步骤和答案。
例如,对于方程组:
初始模型生成的解答可能包含错误的推理步骤,如错误的消元操作或代数变形。经过GRPO训练后,模型能够正确执行消元法,逐步推导出和的解。这一过程不仅验证了GRPO在提升模型推理能力方面的有效性,还展示了其在数学推理任务中的实际应用价值。
代码生成任务中的实践效果
在代码生成任务中,GRPO算法通过执行验证(如代码执行结果)作为可验证奖励,显著提升了代码的正确率和执行效率。以排序算法代码生成为例,传统强化学习方法生成的代码在复杂数据集上的执行通过率仅为60%左右,而采用GRPO优化后的模型在相同数据集上的通过率提升至90%以上。
对于快速排序算法的生成任务,初始模型可能生成存在边界条件处理错误或递归终止条件不正确的代码。应用GRPO后,模型能够根据代码执行结果的二元奖励信号(执行成功或失败)调整策略,逐步生成正确的代码。实验结果显示,在不同代码复杂度场景下,GRPO优化后的模型均表现出更高的代码质量和执行效率。例如,对于包含重复元素和极端值的数组排序任务,GRPO优化后的模型生成的代码能够正确处理这些特殊情况,而未优化的模型则可能出现无限递归或错误排序结果。
多领域综合案例分析
除了数学推理和代码生成任务外,GRPO算法在文本生成、问答系统等多个领域也展现出了广泛的应用潜力。在文本生成任务中,通过结合可验证约束(如输出格式要求),GRPO能够有效提升生成文本的格式正确性和内容相关性。例如,在新闻报道生成任务中,模型需要遵循特定的结构(如标题、导语、正文)并包含关键事实。应用GRPO后,模型生成的文本在格式正确性和事实准确性方面均有显著提升,成功概率从初始的35%提升至70%以上。
在问答系统中,GRPO通过正确性验证(如答案与标准答案的匹配)优化模型的回答质量。例如,在医疗咨询问答任务中,模型需要根据用户症状提供准确的建议。通过GRPO训练,模型的回答正确率从50%提升至80%,且生成的回答更加符合医学专业标准和用户需求。
这些多领域案例分析表明,GRPO算法具有良好的通用性和适应性,能够在不同类型的任务中有效提升模型性能,为LLM的实际应用提供了强大的支持。
总结
这篇论文对GRPO算法与可验证奖励的结合进行了系统性研究,展示了其在强化学习中的独特优势和理论特性。主要贡献包括:
- 适应性加权对比损失的提出:通过数学推导证明GRPO本质上是一种适应性加权对比损失,其权重根据旧策略的成功概率动态调整,从而实现对正负样本的精准强化和惩罚。
- 成功概率递推关系的构建:推导出成功概率的固定点迭代公式,并分析了其收敛性和动态特性,为理解GRPO的迭代动态提供了理论基础。
- 成功概率放大效果的证明:通过理论分析和实验验证,证明GRPO能够在不同初始成功概率条件下放大成功概率,从而提升模型性能。
- 误差分析与近似策略的收敛性证明:在考虑参数化策略与非参数化策略差异的情况下,分析了各类误差的来源,并证明了在误差可控时参数化策略的成功概率能够接近理论固定点。
这些成果不仅丰富了强化学习的理论体系,还为提升LLM在数学推理、代码生成、文本创作等任务中的性能提供了重要的实践指导。
基于实际案例分析,GRPO算法在提升LLM性能方面展现出显著的效果。例如,DeepSeek-R1模型在应用GRPO后,在数学推理任务上的成功概率提升了约45%,代码生成任务上的执行通过率提高了30%。这些成果表明,GRPO在实际应用中具有重要的价值,特别是在需要高准确性和可靠性的任务中。GRPO算法有望在以下几个领域发挥更广泛的作用:
- 多模态LLM开发:随着多模态模型的发展,GRPO可以结合视觉、文本等多种模态的可验证奖励,进一步提升模型的综合推理能力和生成质量。
- 复杂任务的分步推理:在需要多步骤推理的任务中(如科学计算、法律分析),GRPO可以通过逐步验证中间结果来引导模型生成更准确的最终答案。
- 实时交互应用:在实时交互场景(如智能客服、机器人控制),GRPO能够快速适应环境反馈,实时优化策略,提高系统的响应速度和准确性。
未来方向展望
尽管GRPO算法已经取得了显著的成果,但仍存在一些研究方向值得进一步探索:
- 自适应调整KL正则化参数:研究如何根据训练过程中的动态信息(如成功概率的变化速率)自适应调整值,以进一步提高算法的收敛速度和稳定性。
- 新的可验证奖励类型:探索基于多维度质量评估的组合奖励(如同时考虑文本的准确性、连贯性和多样性),并研究其与GRPO的结合机制,以满足更复杂的应用需求。
- 与其他强化学习方法的融合:研究GRPO与逆强化学习、层次强化学习等方法的融合策略,以应对更复杂的任务结构和环境动态性。
- 大规模分布式训练优化:针对大规模数据和模型训练场景,优化GRPO算法的分布式实现,提高其计算效率和可扩展性。
这些研究方向将进一步推动GRPO算法的发展,为LLM的训练和应用提供更强大的技术支持。