强化学习

小鹏汽车推新物理大模型,定位AI汽车公司
近日,小鹏汽车创始人何小鹏在社交媒体上透露,作为将 “智能化” 作为核心的车企之一,小鹏汽车的本质定位在于 “AI 汽车公司”。 他强调,人工智能(AI)最大的价值不仅在于数字世界的应用,更在于能够改变我们的物理世界。 这一观点引发了行业内外的关注与讨论。

强化学习带来的改进只是「噪音」?最新研究预警:冷静看待推理模型的进展
「推理」已成为语言模型的下一个主要前沿领域,近期学术界和工业界都取得了突飞猛进的进展。 在探索的过程中,一个核心的议题是:对于模型推理性能的提升来说,什么有效? 什么无效?

字节新推理模型逆袭DeepSeek,200B参数战胜671B,豆包史诗级加强?
字节最新深度思考模型,在数学、代码等多项推理任务中超过DeepSeek-R1了? 而且参数规模更小。 同样是MoE架构,字节新模型Seed-Thinking-v1.5有200B总参数和20B激活参数。

AI Agent 发展史:从 RL 驱动到大模型驱动 |AIR 2025
Manus 的出现将智能体推入当下 AI 格局的前列,使得这个过去略抽象的概念变得具体可感知。 然而行业中也不乏对 Manus 的争议,认为 Manus 没有底层技术创新力,更多的是将现有技术融合从而在工程上创新,即所谓的“套壳”。 虽说工程创新也是一种护城河,但“套壳”的说法也并非完全没道理。

UI-R1|仅136张截图,vivo开源DeepSeek R1式强化学习,提升GUI智能体动作预测
基于规则的强化学习(RL/RFT)已成为替代 SFT 的高效方案,仅需少量样本即可提升模型在特定任务中的表现。 该方法通过预定义奖励函数规避人工标注成本,如 DeepSeek-R1 在数学求解中的成功应用,以及多模态领域在图像定位等任务上的性能突破(通常使用 IOU 作为规则 reward)。 vivo 与香港中文大学的研究团队受到 DeepSeek-R1 的启发,首次将基于规则的强化学习(RL)应用到了 GUI 智能体领域。

首次引入强化学习!火山引擎Q-Insight让画质理解迈向深度思考
从 GPT-4o 吉卜力风、即梦的 3D 动画、再到苹果 Vision Pro,AI 视觉创作正迎来生产力大爆炸。 一个重要问题随之浮现:如何评估机器生成的画质符合人眼审美? 人眼能瞬间辨别图像优劣,但教会机器理解「好看」却充满挑战。

大模型RL不止数学代码!7B奖励模型搞定医学法律经济全学科, 不用思维链也能做题
一个7B奖励模型搞定全学科,大模型强化学习不止数学和代码。 o1/r1的强化学习很强,但主要探索了数学和代码领域,因为这两个领域的数据结构化程度高,奖励函数/奖励模型比较好设计。 那么,想提升大模型在其他学科领域的能力该怎么办?

业界突破多模态泛化推理能力,OPPO研究院&港科广提出OThink-MR1技术
用上动态强化学习,多模态大模型也能实现泛化推理了? 来自OPPO研究院和港科广的科研人员提出了一项新技术——OThink-MR1,将强化学习扩展到多模态语言模型,帮助其更好地应对各种复杂任务和新场景。 研究人员表示,这一技术使业界突破多模态泛化推理能力。

SWEET-RL:基于训练时信息的多轮LLM代理强化学习框架
SWEET-RL(Step-WisE Evaluation from Training-time information,基于训练时信息的逐步评估)是多轮大型语言模型(LLM)代理强化学习领域的重要技术进展。 该算法相较于现有最先进的方法,成功率提升了6%,使Llama-3.1-8B等小型开源模型能够达到甚至超越GPT-4O等大型专有模型的性能水平。 本文将深入分析SWEET-RL如何改进AI代理在复杂协作任务中的训练方法。

清华与蚂蚁数科携手突破:BodyGen助力机器人性能跃升 60%
近年来,具身智能热度飙升,从春晚机器人精彩表演,到被写入政府工作报告,再到英伟达黄仁勋多次力推,它已成为AI领域的焦点。 具身智能旨在让机器人像人类一样,在真实世界中精准感知、灵活应对。 清华大学与蚂蚁数科的研究团队带来重大突破,他们在ICLR2025发表的论文中提出BodyGen算法框架。

腾讯“混元-T1”推理模型在基准测试中与 OpenAI 的 o1 能力相匹配
腾讯近日宣布推出其最新的大型语言模型——混元-T1,并表示该模型在推理能力上可与OpenAI的最佳推理系统相匹敌。 据腾讯介绍,混元-T1在开发过程中高度依赖强化学习,高达96.7%的训练后算力都用于提升模型的逻辑推理能力以及与人类偏好的一致性。 在多项基准测试中,混元-T1展现出强大的性能。

Fin-R1:基于Qwen2.5-7B强化学习训练的金融大模型,7B参数击败行业巨头
金融科技领域迎来一位强劲新秀。 上海财经大学统计与数据科学学院张立文教授团队(SUFE-AIFLM-Lab)联合财跃星辰共同研发的Fin-R1模型正式开源,以惊人的性能引发业界广泛关注。 这款基于Qwen2.5-7B的金融专用大模型通过强化学习训练,在多项金融基准测试中达到了领先水平。
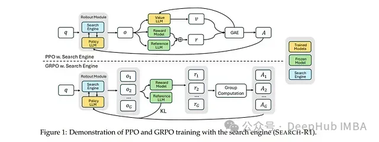
SEARCH-R1: 基于强化学习的大型语言模型多轮搜索与推理框架
这个研究提出了一种新型强化学习(RL)框架SEARCH-R1,该框架使大型语言模型(LLM)能够实现多轮、交错的搜索与推理能力集成。 不同于传统的检索增强生成(RAG)或工具使用方法,SEARCH-R1通过强化学习训练LLM自主生成查询语句,并优化其基于搜索引擎结果的推理过程。 该模型的核心创新在于完全依靠强化学习机制(无需人工标注的交互轨迹)来学习最优的搜索查询策略及基于检索知识的推理方法,从而显著提升问答任务的性能表现。

小米大模型团队在音频推理领域取得重大突破,登顶国际评测榜
近日,小米大模型团队在音频推理领域的研究中取得了突破性进展,成功应用强化学习算法于多模态音频理解任务,准确率达到了64.5%,这一成就使其在国际权威的 MMAU 音频理解评测中夺得了第一名。 这一成果的背后,离不开团队对 DeepSeek-R1的启发。 MMAU(Massive Multi-Task Audio Understanding and Reasoning)评测集是衡量音频推理能力的重要标准,通过对包含语音、环境声和音乐的多种音频样本进行分析,测试模型在复杂推理任务中的表现。
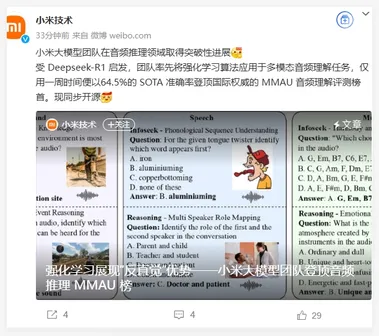
小米大模型团队登顶音频推理 MMAU 榜,受到DeepSeek-R1启发
小米技术官方微博宣布,小米大模型团队在音频推理领域取得了显著进展。 他们在受到 DeepSeek-R1的启发后,率先将强化学习算法应用于多模态音频理解任务。 团队在短短一周内便以64.5% 的 SOTA(State Of The Art)准确率,登顶国际权威的 MMAU 音频理解评测榜,并同步将相关技术开源。

首创GRPO方案!AlphaDrive:VLM+RL破解自动驾驶长尾难题
写在前面 & 笔者的个人理解OpenAI o1 和 DeepSeek R1 在数学和科学等复杂领域达到了或甚至超越了人类专家的水平,强化学习(RL)和推理在其中发挥了关键作用。 在自动驾驶领域,最近的端到端模型极大地提高了规划性能,但由于常识和推理能力有限,仍然难以应对长尾问题。 一些研究将视觉-语言模型(VLMs)集成到自动驾驶中,但它们通常依赖于预训练模型,并在驾驶数据上进行简单的监督微调(SFT),没有进一步探索专门为规划设计的训练策略或优化方法。
360智脑团队成功复现Deepseek强化学习效果,发布开源模型Light-R1-14B-DS
近日,360智脑团队宣布成功复现Deepseek的强化学习效果,并正式发布开源推理模型 Light-R1-14B-DS。 该模型性能表现超越 DeepSeek-R1-Distill-Llama-70B和 DeepSeek-R1-Distill-Qwen-32B,成为业界首款在14B参数规模上实现强化学习效果的模型,显著提升了数学推理能力,成绩超过大多数32B级别模型。 与 DeepSeek-R1-14B 相比,Light-R1-14B-DS*在数学竞赛任务中表现突出:在 AIME24测试中提升4.3分,在 AIME25中更是提高10分。

超越DeepSeek-R1关键RL算法GRPO,CMU「元强化微调」新范式登场
大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。 通常来说,这些方法在训练模型时可以产生比典型正确解决方案更长的轨迹,并包含了试图实现某些「算法」的 token:例如反思前一个答案、规划或实现某种形式的线性搜索。 这些方法包括显式地微调预训练 LLM 以适应算法行为,例如对搜索数据进行监督微调(SFT)或针对 0/1 正确性奖励运行结果奖励(outcome-reward,OR)RL。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉