你是否想过,工厂是如何在很多种不同产品中,精准识别出浅浅的划痕、缺失的元件,甚至是几乎察觉不到的微小缺陷?这远比「图像识别」要复杂。
在工业质检、安防监控、医疗影像等场景中,无监督异常检测(Unsupervised Anomaly Detection, UAD)日益成为核心技术之一。
由于现实世界中异常样本稀少、类型多样、标注昂贵,UAD 凭借「仅用正常样本训练」的能力,在工业界获得了广泛关注。
但一个悄然被忽视的难题也在同步放大:当前最先进的检测模型,无论是基于图像重建的 Diffusion/UNet/ViT,还是基于特征对比的 DINO/ViT,在生成异常图(anomaly map)时几乎都隐含了一个过程:匹配(matching)。
当前许多AI系统依赖于将待测图像与正常样本进行匹配来判断异常,但这一过程极易受到噪声干扰,尤其在处理模糊、低对比或结构细微的缺陷时,常常出现误报与漏检。
而这个看似「简单」的操作,常常掩盖了检测失败的根源。匹配过程中的噪声,可能是真正导致误检与漏检的幕后黑手。
在ICML 2025接收论文中,来自东北大学、Meta和英国萨里大学的研究者联合提出CostFilter-AD,首次将「匹配代价体滤波」系统性引入无监督异常检测(UAD)。与其说关注「学得更好」,CostFilter-AD更关注「比得更准」。

论文链接:https://icml.cc/virtual/2025/poster/46359
GitHub地址:https://github.com/ZHE-SAPI/CostFilter-AD
演示:
https://github.com/ZHE-SAPI/CostFilter-AD/blob/main/Materials/CostFilter-AD_slide_ICML2025.pdf
它构建一个异常代价体来全局表征图像与正常模板之间的匹配成本,并通过滤波机制清除噪声、增强边界,使得微小异常也难以遁形。
更重要的是,CostFilter-AD无需真实缺陷样本参与训练,仅依赖正常样本就能精准检测各类未知异常,具备强泛化能力与部署适应性。
作为一个通用插件式模块,它能无缝集成到现有检测方法中,有效提升检测精度与边界清晰度,为工业质检带来更智能、更可靠的解决方案。
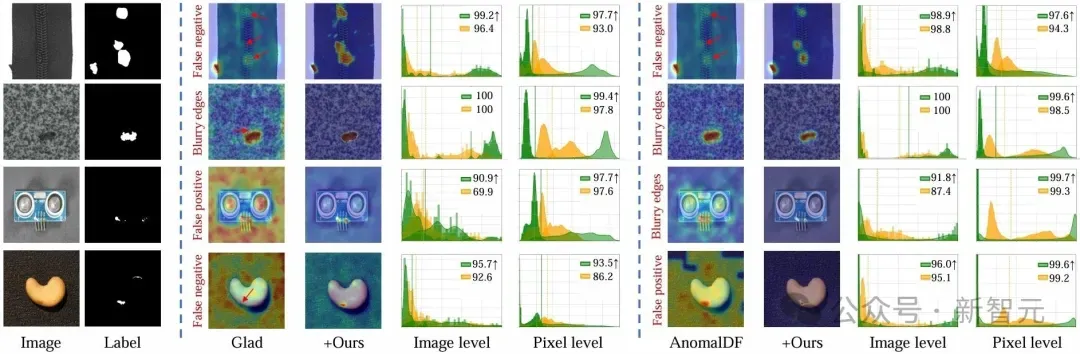
图1 多类别无监督异常检测(UAD)结果对比。展示了图像级与像素级logits的可视化结果及其核密度估计曲线(Parzen,1962)。其中,基线方法的结果以黄色标示,提出的方法以绿色标示。相比之下,该模型在检测异常时噪声更少,且在正常与异常logits之间提供了更清晰的区分,表现更加优越。
方法突破口
动机分析:不是模型不够强,而是「匹配得不够准」。
目前主流UAD方法大致分为两类:
- 重建式方法:将输入图像还原成「正常版本」,异常区域将表现为高残差;
- 嵌入式方法:将输入图像投影到特征空间,与正常样本进行相似性匹配。
两类方法虽然形式不同,但在最后生成anomaly heat map时,本质都要完成一种「输入vs正常样本」的匹配。
问题在于:现实中的匹配从不完美。
- 重建式方法中,Diffusion等模型可能会错误保留异常结构(e.g. short cut issue),形成「伪正常」图像;
- 嵌入式方法中,基于预训练特征(如ViT、DINO)提取的嵌入往往存在尺度、视角、纹理的偏差,使得相似性计算被高维噪声干扰。
然而,这些「匹配噪声」长期被忽视,异常检测系统只能被动接受「残差」或「相似性」分数,而非从源头优化其可靠性。
CostFilter-AD:首提「匹配代价体滤波」范式
为解决这一核心难题,研究人员提出一种全新视角:
异常检测=匹配代价体构建+滤波优化+anomaly map生成,具体步骤为:
- 构建完整的匹配代价体(Cost Volume),显式表征「输入图vs正常样本」之间的多维匹配关系;
- 引入一个基于双流注意力(Dual Stream Attention)的3D U-Net网络,对代价体进行细粒度滤波;
- 输出结构清晰的anomaly heat map,作为最终异常检测分割图。
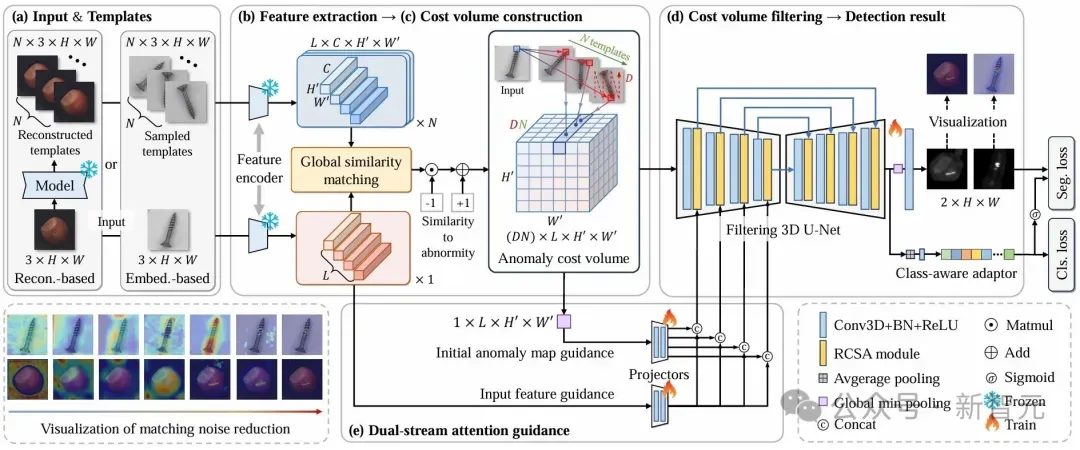
图2 CostFilter-AD方法概览。将无监督异常检测(UAD)重新表述为一个「匹配代价滤波」过程。(i)首先,利用预训练编码器从输入图像和模板图像中提取特征,模板可以是重建得到的正常图像,或随机选择的正常样本;(ii)接着,基于全局相似性计算构建异常代价体(anomaly cost volume);(iii)然后,设计一个代价体滤波网络,结合从输入特征和初始异常图中提取的注意力查询信息,对代价体进行细化,生成最终检测结果;(iv)最后,引入类别感知适配器,以应对类别不平衡问题,并提升模型对多类异常的同时检测能力。
方法亮点包括:
- 机制创新:首次引入「匹配代价体+滤波」到UAD领域;
- 即插即用:不需改动原模型架构,适配所有主流检测器;
- 性能显著提升:Image-AUROC & Pixel-AUROC等七种异常检测指标全面增长;
- 泛化增强:处理模糊边界、小尺寸异常亦很有效。
不是再造大模型,而是细化匹配过程
CostFilter-AD包括以下三个关键阶段:
构建匹配代价体(Matching Cost Volume)
研究人员不再仅仅计算一对图像之间的单一匹配值,而是:
- 对输入图像与多个正常模板图像进行全局像素级匹配;
- 在每个特征层上计算余弦相似度,得到三维代价体(空间维度 × 匹配维度 × 通道);
- 转换为 anomaly cost(1−similarity),形成全局异常热图。
与常见的最近邻匹配KNN不同,CostFilter-AD捕获了多模板、多尺度、多位置之间的结构性匹配模式。
匹配代价体滤波(Cost Volume Filtering)
匹配代价体矩阵虽然得到,但其中依然混有大量「误判」:正常边缘误认为异常(或相反)、异常细节被模糊覆盖等。
为此,研究人员引入一个具备Dual-Stream Attention机制的3D U-Net网络,对代价体进行去噪与增强:
- 通道引导(MG):使用初始 anomaly 热图引导模型关注更可能为异常的通道区域;
- 空间引导(SG):使用输入图特征作为空间注意力,引导模型保留边界结构;
- 残差引导机制(RCSA):融合上述注意力流,逐层优化代价体表示。
经过滤波后,输出anomaly map的分布更集中、边界更清晰。
类别自适应损失与泛化机制
为适配多类工业检测任务,研究人员设计了Class-Aware Adapter:
- 利用 soft logit 调整 focal loss 的聚焦因子,自适应平衡易错类别;
- 优化结构损失(SSIM + soft IoU),增强检测的结构一致性。
这让CostFilter-AD在单模型处理多类anomaly时保持高效与准确。
实验结果
四大数据集、五个最新baseline、七种异常检测指标全面刷新
CostFilter-AD被集成至五大主流UAD框架中:
- GLAD(Reconstruction-based Diffusion, ECCV’24);
- HVQ-Trans(Reconstruction-based Transformer, NeurIPS’23);
- AnomalDino(Embedding-based Dinov2, WACV’25);
- UniAD(Embedding-based Transformer, NeurIPS’22);
- Dinomaly(Reconstruction-based Transformer, CVPR’25).
研究人员在MVTec-AD、VisA、MPDD、BTAD四个工业数据集上进行像素级和图像级别异常检测。
· 定量结果:
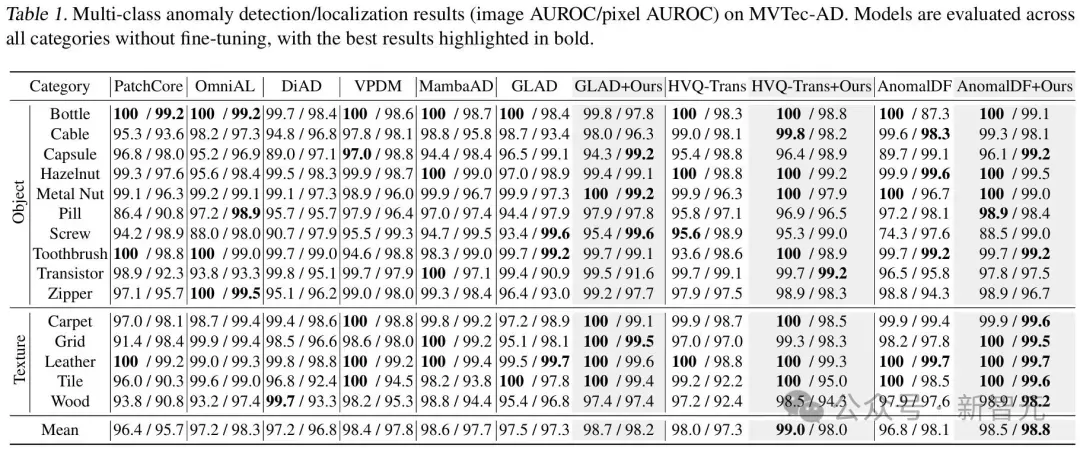
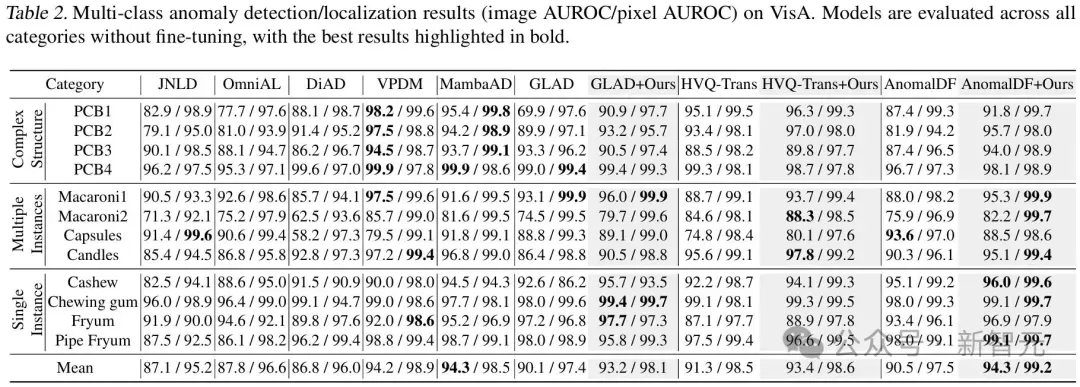
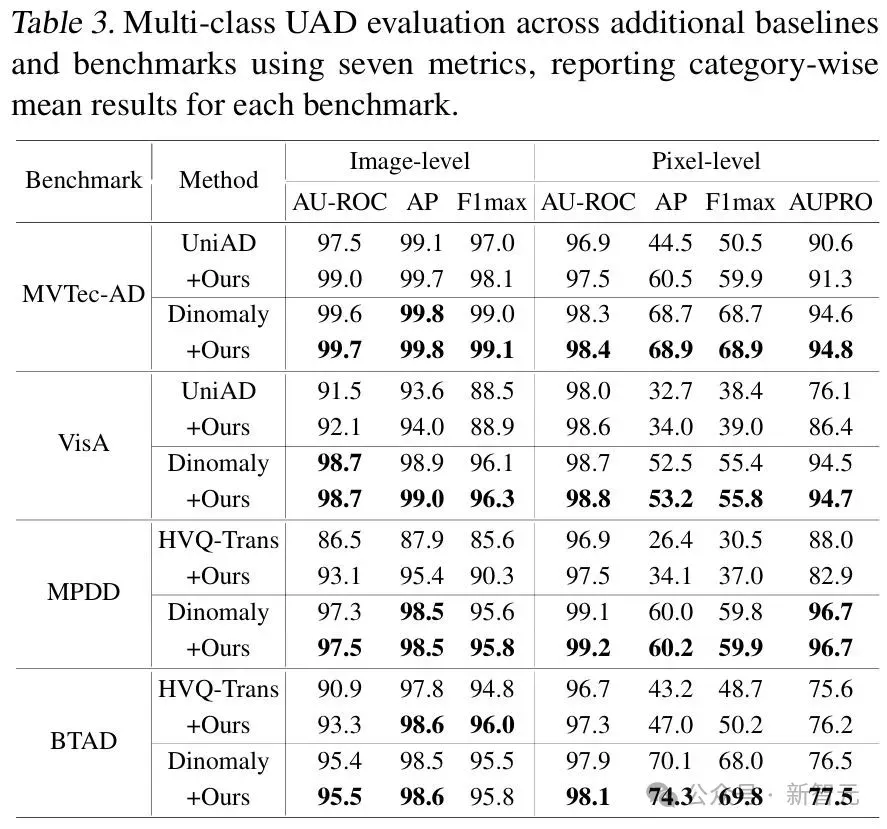
更多测试指标请参考论文附录。
· 可视化结果:边界更清晰,baseline漏检区域被成功检测;
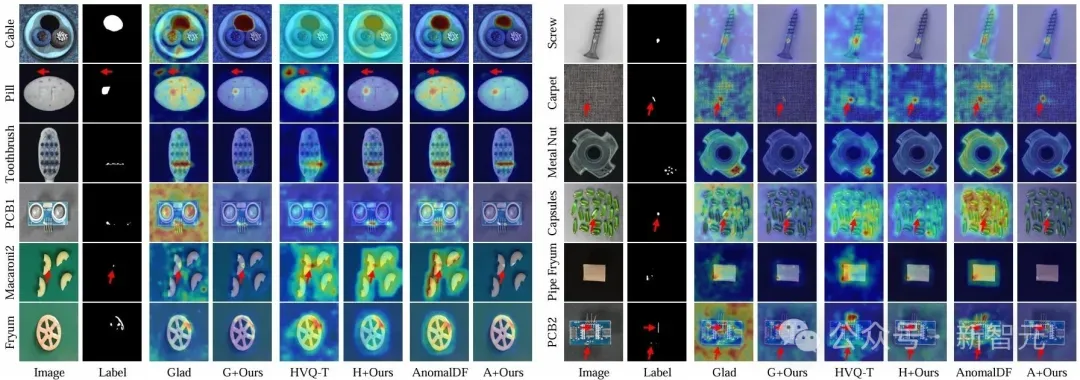
图3 多类别异常定位的定性对比。研究人员将该方法与GLAD(G)、HVQ-Trans(H)和AnomalDF(A)在MVTec-AD(上三行)和VisA(下三行)数据集上的结果进行对比。通过集成至现有方法中,该方法能够有效缓解匹配噪声问题(例如:PCB2中的漏检、Pill中的误检,以及Carpet中的模糊边界),显著提升异常检测性能。
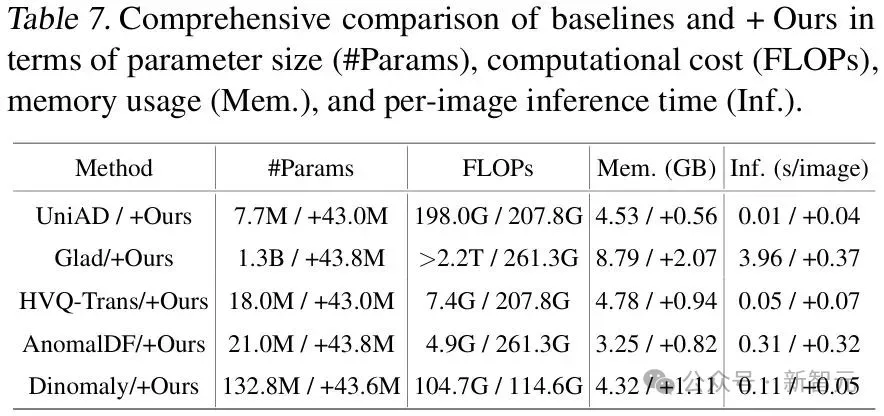
· 内存&推理:平均仅提升显存和延时较小,有助于实际可部署。
即插即用,轻量部署,工业友好
CostFilter-AD是一款即插即用(plug-and-play)的异常检测增强模块:
- 支持多种输入模板:重建图、特征模板、混合中间表示;
- 兼容主流模型:ViT-B/8、EfficientNet-B4、DINO、Diffusion全部适配;
- 部署无压力:可部署于工业边缘设备、服务器或API服务端。
方法总结:从匹配修正出发,重塑异常检测核心范式
CostFilter-AD的核心理念在于重塑anomaly map/score的生成方式:
异常检测的难点,不仅在于是否能还原/嵌入得好,更在于是否「比」得准确。
通过构建代价体并对其进行滤波优化,研究人员重新定义了异常分数的构成逻辑:不是谁更像,而是「匹配结果如何更可信」。
这一思路不仅适用于图像异常检测,或许还可迁移至:
- 时序异常检测(e.g. 预测轨迹vs实际轨迹的匹配代价);
- 视觉异常追踪(匹配掩码vs模板结构);
- RL状态匹配估计(当前状态vs高奖励状态的策略匹配)等场景。


